
المذكرة لا ترضي أحداً لكنها تغير كل شيء.
عندما اكتشف قسم أشباه الموصلات في Samsung أن المهندسين قد حمّلوا تصاميم رقائق خاصة إلى ChatGPT، كان الرد فورياً ومطلقاً. حظر على مستوى الشركة. بدون استثناءات. بدون عملية استئناف. الأداة التي أصبحت مرادفة لإنتاجية الذكاء الاصطناعي أصبحت الآن محظورة على جميع شبكات الشركة.
لم تكن Samsung وحدها. في غضون أشهر، ظهرت إعلانات مماثلة من JPMorgan Chase وApple وAmazon وGoldman Sachs وDeutsche Bank وعشرات المؤسسات الأخرى. منعت شركات المحاماة التي تقدم الاستشارات لشركات Fortune 500 المحامين من استخدام الخدمة. حظرت أنظمة الرعاية الصحية الوصول على مستوى جدار الحماية. أصدرت الوكالات الحكومية توجيهات أنهت فعلياً أي غموض حول الاستخدام المقبول.
كشف النمط شيئاً تجاهله عشاق التكنولوجيا في حماسهم لقدرات الذكاء الاصطناعي: يعمل التبني المؤسسي تحت قيود لا يعمل بها التبني الاستهلاكي.
تفحص هذه المقالة لماذا تتشدد سياسات الذكاء الاصطناعي في الشركات، وما المخاطر المحددة التي تدفع هذه القرارات، وكيف يمكن للمؤسسات الحفاظ على قدرات الذكاء الاصطناعي دون قبول التعرض غير المقبول للبيانات. لا يتطلب المسار للأمام التخلي عن الذكاء الاصطناعي. يتطلب فهم أن البنية التحتية مهمة بقدر أهمية الذكاء.

الحوادث التي غيرت كل شيء
لم تنشأ حظورات الذكاء الاصطناعي في الشركات من تقييمات مخاطر نظرية. جاءت بعد حوادث فعلية حيث هربت معلومات سرية من السيطرة المؤسسية.
خرق Samsung لأشباه الموصلات
في أوائل عام 2023، استخدم موظفو Samsung Electronics ChatGPT لتصحيح الأكواد المصدرية وتحسين عمليات تصنيع أشباه الموصلات. لصق المهندسون أكواداً خاصة مباشرة في واجهة الدردشة. حمّل آخرون ملاحظات اجتماعات تحتوي على مناقشات التخطيط الاستراتيجي. في غضون ثلاثة أسابيع من السماح باستخدام ChatGPT داخلياً، حدد فريق أمن المعلومات في Samsung حالات متعددة من نقل البيانات السرية إلى خوادم OpenAI.
تعمل صناعة أشباه الموصلات على هوامش تُقاس بالنانومتر ومزايا تنافسية تُقاس بالأشهر. كان احتمال أن عمليات التصنيع الخاصة بـ Samsung أصبحت الآن في مجموعة تدريب OpenAI—ومن المحتمل أن تكون متاحة للمنافسين الذين يستخدمون نفس الخدمة—غير مقبول. نفذت Samsung حظراً كاملاً وبدأت في تطوير أدوات ذكاء اصطناعي داخلية لن تنقل البيانات خارجياً أبداً.
استجابة صناعة الخدمات المالية
قيدت JPMorgan Chase الوصول إلى ChatGPT قبل أي حادثة معلنة، معترفة بالآثار التنظيمية بشكل استباقي. عندما يحلل موظفو البنك محافظ العملاء أو يناقشون استراتيجيات الاندماج أو يقيمون مخاطر الائتمان، فإنهم يتعاملون مع معلومات تخضع للوائح SEC وقوانين السرية المصرفية والواجبات الائتمانية. نقل مثل هذه المعلومات إلى خدمة ذكاء اصطناعي تابعة لطرف ثالث—بغض النظر عن سياسات الخصوصية المعلنة لتلك الخدمة—يخلق تعرضاً للامتثال لن يقبله أي مستشار قانوني عام.
تبعتها Goldman Sachs وCitigroup وBank of America وDeutsche Bank بقيود مماثلة. عكست الاستجابة المنسقة لصناعة الخدمات المالية ليس جنون العظمة بل الفهم المهني للمسؤولية التنظيمية. سيتطلب خرق البيانات الناشئ عن استخدام موظفي ChatGPT الإفصاح ويحفز التحقيق التنظيمي وقد يؤدي إلى إجراء تنفيذي.
الآثار المترتبة على الصناعة القانونية
لم تصدر نقابة المحامين الأمريكية حظراً شاملاً على أدوات الذكاء الاصطناعي، لكن التأثير العملي لمتطلبات امتياز المحامي-الموكل يقاربه. عندما يناقش محامٍ مسائل موكليه مع ChatGPT، قد تتنازل المحادثة عن حماية الامتياز. يمكن أن تفقد المعلومات المكشوفة لأطراف ثالثة—حتى أنظمة الذكاء الاصطناعي—السرية التي تجعل المشورة القانونية محمية.
نفذت شركات المحاماة الكبرى بما في ذلك Davis Polk وCravath وSullivan & Cromwell قيوداً تتراوح من الحظر الكامل إلى سياسات الاستخدام المعتمد فقط التي تتطلب إذن الشريك. أظهرت استجابة مهنة المحاماة أن مخاطر الذكاء الاصطناعي تمتد إلى ما وراء أمن البيانات إلى أسئلة جوهرية عن المسؤولية المهنية.
الواقع التقني للتعامل مع بيانات الذكاء الاصطناعي السحابي
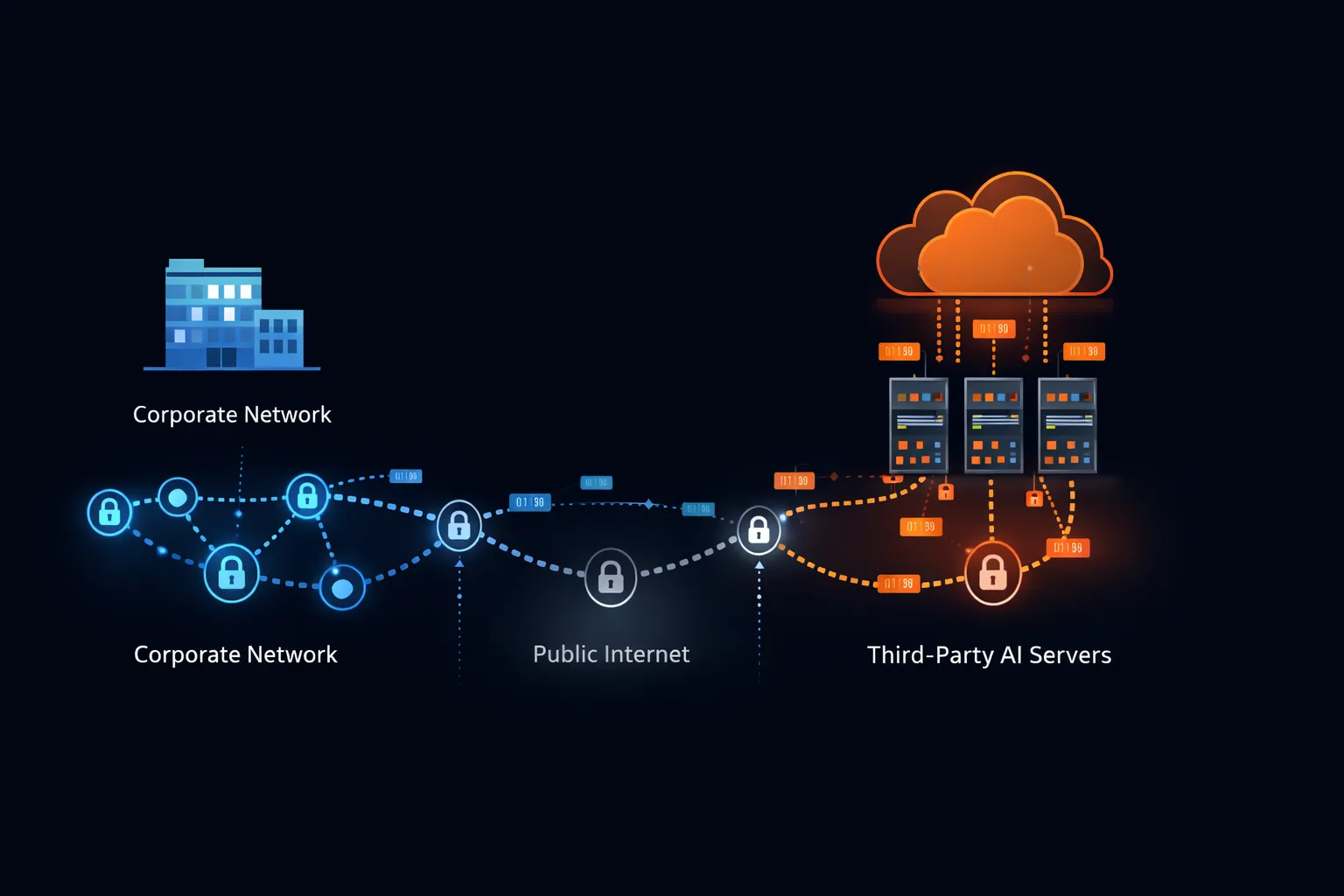
يتطلب فهم سبب حظر المؤسسات لـ ChatGPT فحص ما يحدث فعلياً عند إرسال رسالة إلى خدمة ذكاء اصطناعي سحابية.
مسار نقل البيانات
عندما تكتب موجهاً في ChatGPT، ينتقل نصك من جهازك عبر شبكة شركتك، عبر الإنترنت العام، إلى بنية OpenAI التحتية. تعمل OpenAI بشكل أساسي على Microsoft Azure، مما يعني أن بياناتك تعبر شبكة Microsoft وتقيم على خوادم يديرها Microsoft.
يحدث هذا النقل بغض النظر عن حساسية المحتوى. لا يستطيع النظام التمييز بين طلب كتابة قصيدة وطلب تحليل شروط اندماج سرية. كل حرف تدخله يتبع نفس المسار إلى نفس الوجهة.
سياسات الاحتفاظ بالبيانات
تطورت سياسات استخدام البيانات الخاصة بـ OpenAI مع مرور الوقت، لكن أساسيات معينة تبقى ثابتة. تُسجل مدخلات المستخدم. تُخزن المحادثات. تعتمد مدة التخزين والغرض منه على مستوى اشتراكك واتفاقياتك المحددة.
بالنسبة لمشتركي الطبقة المجانية وPlus، تحتفظ OpenAI صراحة بالحق في استخدام المدخلات لتحسين النموذج. موجهاتك تصبح بيانات تدريب. الكود السري الذي لصقته لتصحيح مشكلة قد يؤثر على كيفية استجابة النموذج للمستخدمين المستقبليين—ربما بما في ذلك منافسيك.
يمكن لمستخدمي API ومشتركي Enterprise الانسحاب من المساهمة في بيانات التدريب، لكن مدخلاتهم لا تزال تُعالج على بنية OpenAI التحتية. لا تزال البيانات موجودة على خوادم لا تتحكم فيها، يديرها موظفون لم تفحصهم، وتخضع لعمليات قانونية لا يمكنك التأثير فيها.
مشكلة الطرف الثالث
تميز بنى الأمان المؤسسية بين أنظمة الطرف الأول (البنية التحتية التي تملكها وتشغلها)، وأنظمة الطرف الثاني (الموردون الذين لديهم علاقات تعاقدية مباشرة وضوابط أمان مُدققة)، وأنظمة الطرف الثالث (الخدمات التي يتم الوصول إليها دون تكامل أمني مفصل).
يعمل ChatGPT، بالنسبة لمعظم المستخدمين، كطرف ثالث غير مُدقق. ما لم تكن مؤسستك قد تفاوضت على اتفاقية مؤسسية محددة مع ملحقات أمنية وحقوق اختبار الاختراق وشهادات الامتثال المطابقة لمتطلباتك، يقع ChatGPT خارج محيطك الأمني مع إمكانية الوصول إلى أي بيانات يختار الموظفون مشاركتها.
يفسر هذا الواقع المعماري لماذا تعامل فرق الأمان ChatGPT بشكل مختلف عن معاملتها لـ Microsoft Office أو Salesforce. تعمل تلك الأنظمة، رغم كونها قائمة على السحابة، بموجب اتفاقيات مؤسسية مع ضوابط أمان محددة وحقوق تدقيق وشروط مسؤولية. لا يقدم ChatGPT، للمستخدم باشتراك 20 دولاراً شهرياً، أياً من هذه الحماية.
الأطر التنظيمية التي تدفع حذر المؤسسات
لا توجد سياسات الذكاء الاصطناعي في الشركات في فراغ. إنها تستجيب لمتطلبات قانونية سبقت ChatGPT وستبقى بعده.
GDPR وحماية البيانات الأوروبية
تفرض اللائحة العامة لحماية البيانات متطلبات صارمة على معالجة البيانات الشخصية لسكان الاتحاد الأوروبي. عندما يلصق موظف معلومات عميل في ChatGPT، فإنه يبدأ نقل بيانات إلى معالج مقره الولايات المتحدة. يتطلب هذا النقل أساساً قانونياً—إما قرارات الملاءمة أو البنود التعاقدية القياسية أو القواعد المؤسسية الملزمة.
قد تفي اتفاقيات معالجة البيانات الخاصة بـ OpenAI بمتطلبات GDPR لبعض حالات الاستخدام، لكن معظم الموظفين الذين يستخدمون المنتج الاستهلاكي ليس لديهم مثل هذه الاتفاقية. إنهم ببساطة ينقلون بيانات شخصية إلى شركة أجنبية دون تفويض.
حظر المنظمون الإيطاليون ChatGPT مؤقتاً في عام 2023 تحديداً بسبب مخاوف GDPR. بينما استُؤنفت الخدمة بعد إجراء OpenAI لتعديلات الامتثال، أظهرت الحادثة استعداد المنظمين للتصرف. تواجه المؤسسات الأوروبية مسؤولية مباشرة عن تصرفات الموظفين التي تنتهك GDPR، مما يخلق حوافز قوية للسياسات المقيدة.
HIPAA وبيانات الرعاية الصحية
يحظر قانون قابلية نقل التأمين الصحي والمساءلة الإفصاح عن معلومات صحية محمية (PHI) إلا في ظروف محددة مصرح بها. العامل في مجال الرعاية الصحية الذي يناقش حالات المرضى مع ChatGPT يكشف PHI لمتلقٍ غير مصرح به.
لا توجد اتفاقية شريك أعمال بين مؤسسات الرعاية الصحية النموذجية وOpenAI. لم يتحقق أي تدقيق أمني من امتثال ChatGPT للضمانات التقنية لـ HIPAA. لا يوجد إطار قانوني يفوض الإفصاح.
تواجه مؤسسات الرعاية الصحية التي تكتشف أن الموظفين قد شاركوا PHI عبر ChatGPT متطلبات إخطار الخرق والتحقيق المحتمل من OCR وعقوبات تصل إلى 1.5 مليون دولار لكل فئة انتهاك سنوياً. تفسر هذه العواقب لماذا تحظر أنظمة المستشفيات ChatGPT على مستوى الشبكة بدلاً من الاعتماد على الامتثال للسياسة.
اللوائح المالية
تعمل البنوك والوسطاء ومستشارو الاستثمار بموجب لوائح SEC وFINRA وOCC والاحتياطي الفيدرالي التي تفرض حفظ السجلات والإشراف على الاتصالات التجارية. عندما يستخدم محلل ChatGPT لصياغة مراسلات العملاء، يجب التقاط تلك المحادثة في أرشيفات الامتثال.
لا يوفر ChatGPT أي تكامل مع أنظمة الأرشفة المؤسسية. لا توجد أدوات إشراف تحدد الاستخدام الإشكالي المحتمل. المحادثة موجودة فقط على خوادم OpenAI وجهاز الموظف—ولا يفي أي منهما بمتطلبات حفظ السجلات التنظيمية.
بعيداً عن حفظ السجلات، يعبر المنظمون الماليون عن قلقهم بشأن نصائح الاستثمار المولدة بالذكاء الاصطناعي ومشاركة الذكاء الاصطناعي في قرارات الائتمان وتحليلات الذكاء الاصطناعي التي قد تشكل تلاعباً بالسوق. يظل المشهد التنظيمي غير مستقر، ويستجيب مسؤولو الامتثال لعدم اليقين بتقييد الاستخدام بدلاً من السماح به في انتظار الوضوح.
اللوائح الناشئة الخاصة بالذكاء الاصطناعي
سيفرض قانون الذكاء الاصطناعي الأوروبي، المتوقع أن يدخل حيز التنفيذ تدريجياً خلال عامي 2025 و2026، متطلبات إضافية على نشر أنظمة الذكاء الاصطناعي. تتطلب تطبيقات الذكاء الاصطناعي عالية المخاطر—بما في ذلك تلك التي تؤثر على التوظيف والائتمان والتعليم—تقييمات المطابقة والتوثيق والرقابة البشرية.
قد تجد المؤسسات التي تستخدم ChatGPT في هذه السياقات نفسها تشغل أنظمة ذكاء اصطناعي غير متوافقة بمجرد دخول اللوائح حيز التنفيذ. تقيد المؤسسات الاستباقية الاستخدام الآن بدلاً من مواجهة معالجة الامتثال لاحقاً.
الملكية الفكرية: المخاطر التي لا يحلها أي عقد
يمثل الامتثال التنظيمي فئة واحدة من المخاوف. تمثل حماية الملكية الفكرية فئة أخرى—وبالنسبة للعديد من المؤسسات، الأكثر أهمية.
الأسرار التجارية والسرية
تتطلب حماية الأسرار التجارية بموجب قانون الدفاع عن الأسرار التجارية والمكافئات الحكومية أن تظل المعلومات سرية من خلال تدابير حماية معقولة. عندما يلصق موظف خوارزميات خاصة أو عمليات تصنيع أو خطط استراتيجية في ChatGPT، تكون تدابير الحماية الخاصة بالمؤسسة قد فشلت.
تفحص المحاكم التي تقيم دعاوى الأسرار التجارية ما إذا كان الطرف المطالب قد اتخذ خطوات معقولة للحفاظ على السرية. السماح للموظفين بمشاركة المعلومات السرية مع خدمات ذكاء اصطناعي تابعة لطرف ثالث يقوض هذا المتطلب. حتى لو لم تتسرب المعلومات أبداً من أنظمة OpenAI، فإن فعل الإفصاح نفسه قد يضر بالحماية القانونية.
يمتد هذا القلق إلى ما هو أبعد من التقاضي الافتراضي. تؤكد الشركات بانتظام دعاوى الأسرار التجارية ضد الموظفين المغادرين والمنافسين. إذا كشف الاستكشاف أن المعلومات “السرية” تمت مشاركتها سابقاً مع ChatGPT—ويمكن لملايين المستخدمين الوصول إليها من خلال تدريب النموذج المحتمل—تضعف المطالبة بشكل كبير.
الأكواد المصدرية والأصول التقنية
تواجه شركات البرمجيات تعرضاً خاصاً. يريد المطورون بطبيعة الحال استخدام أدوات الذكاء الاصطناعي لتصحيح الأكواد وإنشاء القوالب وتسريع التطوير. لكن الأكواد المصدرية تمثل الأصل الأساسي لعمل البرمجيات. بمجرد نقلها إلى ChatGPT، يوجد ذلك الكود خارج السيطرة المؤسسية.
القلق بشأن بيانات التدريب ليس نظرياً. تتعلم النماذج اللغوية الكبيرة من مدخلاتها. بينما تذكر OpenAI أن عملاء Enterprise وAPI يمكنهم الانسحاب من المساهمة في التدريب، لا يحمل المنتج الاستهلاكي مثل هذا الضمان. قد يؤثر الكود الذي شاركه مطور واحد على الإكمالات المعروضة لمطور آخر—ربما في شركة منافسة.
أشار التحذير الداخلي لـ Amazon للموظفين تحديداً إلى خطر أن ردود ChatGPT قد تشبه معلومات Amazon السرية، مما يشير إلى أن بيانات مماثلة قد أُدرجت بالفعل في النموذج. سواء كان هذا يمثل كود Amazon فعلياً في بيانات التدريب أو مجرد أنماط مماثلة لا يزال غير واضح. دفع الغموض نفسه السياسة المقيدة.
معلومات العملاء والزبائن
تعمل شركات الخدمات المهنية—المستشارون والمحاسبون والمحامون والمهندسون المعماريون—مع معلومات عملاء تنتمي لأولئك العملاء، وليس لمقدم الخدمة. قد تنتهك مشاركة بيانات العملاء مع ChatGPT خطابات التعاقد واتفاقيات السرية وقواعد الأخلاقيات المهنية.
المستشار الذي يحمّل التوقعات المالية لعميل إلى ChatGPT للتحليل قد شارك معلومات ذلك العميل السرية مع طرف ثالث. قد تواجه شركة المستشار دعاوى خرق العقد والتأديب المهني وفقدان علاقات العملاء إذا اكتُشف الأمر.
تنطبق هذه المخاوف بالتساوي على أي عمل يتعامل مع بيانات العملاء. ممثل المبيعات الذي يلصق مراسلات العملاء في ChatGPT لصياغة رد قد نقل اتصالات العملاء إلى OpenAI. اعتماداً على الصناعة والاتفاقيات المعمول بها، قد ينتهك هذا التزامات التعامل مع بيانات العملاء.

عدم كفاية اتفاقيات الذكاء الاصطناعي المؤسسية
تقدم OpenAI ChatGPT Enterprise خصيصاً لمعالجة مخاوف الشركات. توفر Microsoft خدمة Azure OpenAI مع ميزات الأمان المؤسسية. تتحسن هذه المنتجات على العروض الاستهلاكية لكنها لا تزيل المخاوف الأساسية لحالات الاستخدام عالية الحساسية.
ما توفره الاتفاقيات المؤسسية
يتضمن ChatGPT Enterprise عدة تحسينات ذات مغزى:
- لا تُستخدم البيانات لتدريب النموذج
- شهادة امتثال SOC 2 Type 2
- تشفير البيانات أثناء السكون والنقل
- تكامل SSO وضوابط إدارية
- ضوابط الاحتفاظ بالبيانات
تلبي هذه الميزات المتطلبات للعديد من حالات الاستخدام المؤسسية. يواجه فريق التسويق الذي يصيغ نص حملة مخاطر ضئيلة. يعمل قسم خدمة العملاء الذي ينشئ قوالب الردود ضمن معايير مقبولة.
ما لا تستطيع الاتفاقيات المؤسسية توفيره
بالنسبة للصناعات المنظمة والملكية الفكرية الحساسة، تقصر الاتفاقيات المؤسسية بطرق أساسية.
أولاً، لا تزال البيانات تُعالج على بنية تحتية لا تتحكم فيها. معلوماتك تقيم على خوادم OpenAI، يديرها موظفو OpenAI، وتخضع لممارسات أمان OpenAI. أنت تثق في تنفيذهم. تثق في فحص موظفيهم. تثق في استجابتهم للحوادث. قد تكون هذه الثقة مبررة، لكنها ثقة على أي حال—وليست تحققاً.
ثانياً، تظل البيانات خاضعة للعملية القانونية. أمر استدعاء يُقدم على OpenAI يمكن أن يجبرهم على الكشف عن محادثاتك. تحقيق حكومي في عميل آخر يمكن أن يكشف عن البنية التحتية المشتركة. تعمل رسائل الأمن القومي وأوامر محكمة FISA بموجب متطلبات السرية التي ستمنع OpenAI من إخطارك بالوصول.
ثالثاً، يشمل سطح الهجوم منظمة OpenAI بأكملها. لم يعد محيطك الأمني ينتهي عند حدود شبكتك. كل موظف في OpenAI لديه وصول للنظام، وكل مورد لديه وصول للبنية التحتية، وكل ثغرة أمنية في أنظمة OpenAI تصبح جزءاً من ملف المخاطر الخاص بك.
رابعاً، يظل الخروج وقابلية النقل مقيدين. تاريخ محادثاتك والسلوكيات المضبوطة بدقة والمعرفة المؤسسية المتراكمة في ChatGPT تنتمي إلى التفاعلات مع نظام OpenAI. يتطلب الانتقال إلى بديل إعادة البناء من الصفر.
بالنسبة لشركة أدوية تطور مركبات جديدة، أو مقاول دفاع يتعامل مع أبحاث شبه سرية، أو مؤسسة مالية مع خوارزميات تداول تمثل مليارات في القيمة المحتملة، هذه القيود مهمة. تقلل الاتفاقيات المؤسسية المخاطر. لكنها لا تزيلها.
بديل النماذج مفتوحة الأوزان
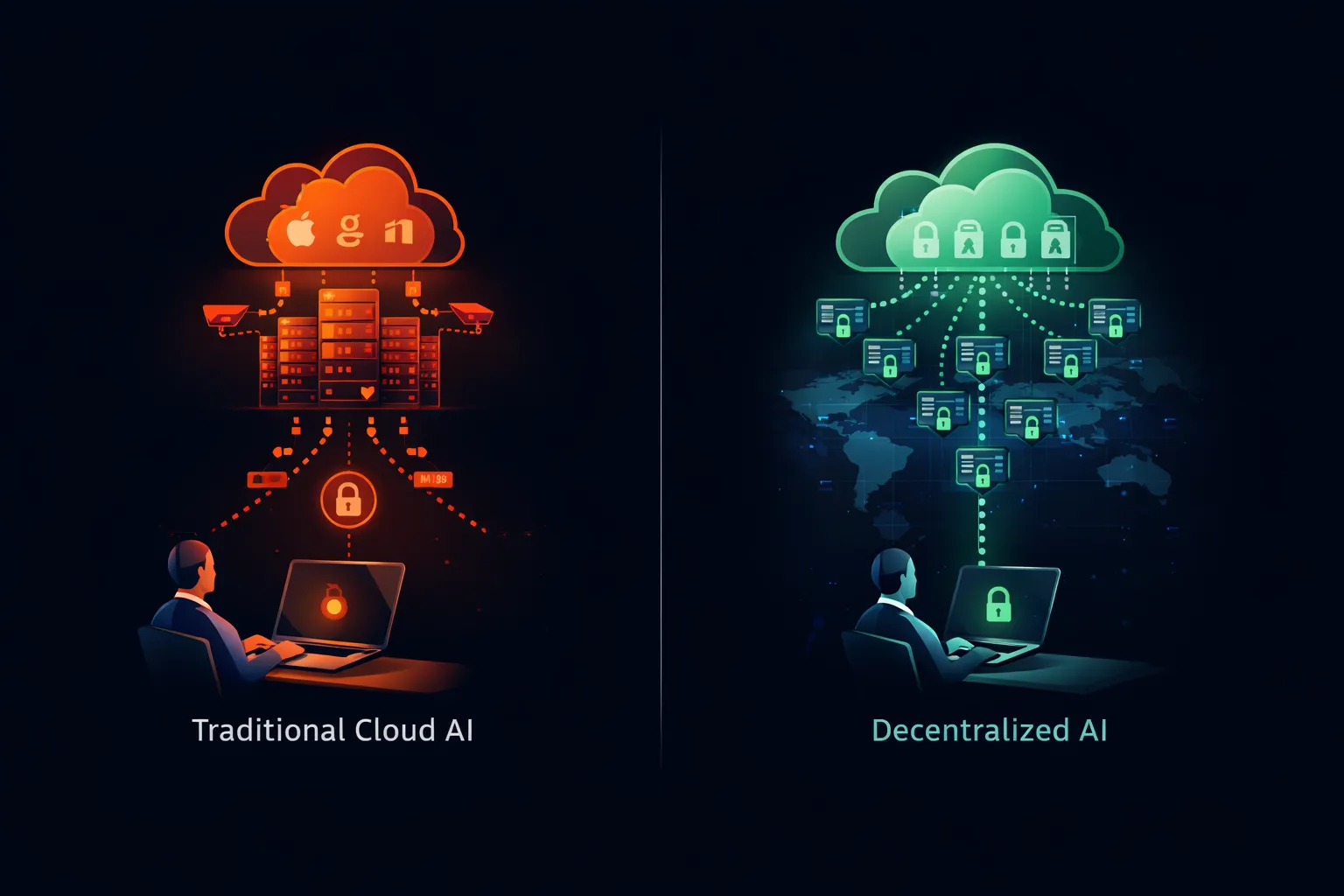
لا تنطبق القيود التي تدفع حظر ChatGPT في الشركات على الذكاء الاصطناعي بشكل عام. إنها تنطبق تحديداً على خدمات الذكاء الاصطناعي السحابية حيث تغادر البيانات السيطرة المؤسسية. بنية مختلفة تزيل هذه المخاوف بالكامل.
ما توفره النماذج مفتوحة الأوزان
توفر النماذج مفتوحة الأوزان—Llama من Meta وMistral من Mistral AI وQwen من Alibaba وعشرات غيرها—ملفات نموذج قابلة للتنزيل تعمل على أي عتاد متوافق. أوزان النموذج عامة. كود الاستدلال مفتوح المصدر. يمكنك تنفيذ النظام بأكمله على بنية تحتية تملكها وتشغلها.
عندما تشغل Llama على خادمك الخاص، موجهاتك لا تغادر شبكتك أبداً. لا يتلقى طرف ثالث بياناتك. لا تسجل خدمة سحابية استفساراتك. لا يدمج أي خط تدريب مدخلاتك. يعمل النموذج محلياً ويعالج محلياً ولا يخزن شيئاً سوى ما تكونه صراحة.
تلبي هذه البنية كل قلق يدفع حظر ChatGPT:
-
الامتثال التنظيمي: تبقى البيانات ضمن محيطك الأمني، تخضع لضوابطك، تُحكم بسياساتك. لا تحدث عمليات نقل بيانات GDPR لأن البيانات لا تُنقل. تتلاشى مخاوف HIPAA لأنه لا يحدث إفصاح لأطراف غير مصرح بها.
-
حماية الملكية الفكرية: تبقى الأسرار التجارية سرية. الأكواد المصدرية لا تغادر أنظمتك أبداً. تُحافظ على سرية العملاء لأنه لا يتلقى طرف ثالث معلومات العملاء.
-
التحكم الأمني: يبقى سطح هجومك ملكك. تتحقق من ممارساتك الأمنية. تفحص موظفيك. تتحكم في استجابتك للحوادث. لا تؤثر ثغرات مؤسسة خارجية على بياناتك.
-
التدقيق والامتثال: كل استعلام وكل رد وكل تفاعل مع النموذج يمكن تسجيله وفقاً لمتطلباتك. يتكامل حفظ السجلات التنظيمي مع أنظمة الأرشفة الموجودة لديك.
مقارنة القدرات
السؤال الطبيعي هو ما إذا كانت النماذج مفتوحة الأوزان تطابق قدرات ChatGPT. الإجابة الصادقة: يعتمد على حالة الاستخدام.
لاستفسارات المعرفة العامة، يوفر تدريب ChatGPT على بيانات بحجم الإنترنت اتساعاً لا تستطيع النماذج المفتوحة الأصغر مطابقته. قدرات التفكير لـ GPT-4 في المشاكل المعقدة تتجاوز ما يحققه Llama-3-8B.
لكن حالات الاستخدام المؤسسية نادراً ما تتطلب معرفة بحجم الإنترنت. يحتاج فريق قانوني يحلل العقود إلى فهم الوثائق وتوليد لغة دقيقة—قدرات تتفوق فيها النماذج المفتوحة المضبوطة بدقة. يحتاج فريق تطوير يصحح الأكواد إلى التعرف على الأنماط ضمن قواعد أكواد محددة—مهمة يتفوق فيها التدريب المخصص بشكل كبير على النماذج العامة.
الرؤية الحاسمة هي أن الضبط الدقيق يحول النماذج العامة إلى متخصصين في المجال. نموذج Llama-3-8B المضبوط بدقة على وثائق مؤسستك ومعايير البرمجة وأنماط الاتصال سيتفوق على GPT-4 لمهامك المحددة مع الحفاظ على عزل البيانات الكامل.
يوفر دليلنا الأساسي حول الضبط الدقيق الخاص لـ LLM على وحدات GPU اللامركزية سير العمل التقني الكامل لهذه العملية.
خيارات البنية التحتية لنشر الذكاء الاصطناعي الخاص
يتطلب تشغيل النماذج مفتوحة الأوزان حوسبة GPU. لدى المؤسسات عدة خيارات لاكتساب هذه القدرة.
العتاد المحلي
يوفر شراء وحدات NVIDIA GPUs لمراكز البيانات الداخلية أقصى قدر من التحكم. يقع العتاد في منشأتك، يديره موظفوك، متصل بشبكتك. لا يوجد لأي طرف خارجي أي وصول.
التحدي هو النفقات الرأسمالية والوقت اللازم. تكلف وحدة NVIDIA H100 GPU حوالي 30,000 دولار. يتطلب مجموعة ذات مغزى للتدريب وحدات متعددة. تمتد جداول الشراء إلى أشهر. تتطلب الصيانة المستمرة خبرة متخصصة.
بالنسبة للمؤسسات الكبيرة التي لديها عمليات مراكز بيانات قائمة، تمثل بنية الذكاء الاصطناعي المحلية التحتية امتداداً طبيعياً. بالنسبة للمؤسسات الأصغر أو تلك التي ليس لديها خبرة في GPU، تكون الحواجز كبيرة.
مثيلات السحابة الخاصة
تقدم AWS وGCP وAzure مثيلات GPU توفر تحكماً أكبر من منتجات AI SaaS. أنت تكون البيئة. تتحكم في الوصول. تُعالج بياناتك على مثيلات مخصصة بدلاً من الخدمات المشتركة.
يتحسن هذا النهج على بنية ChatGPT لكنه يحتفظ بمشاركة مزود السحابة. لا تزال بياناتك تقيم على بنية تحتية لا تتحكم فيها فعلياً. يمكن لموظفي مزود السحابة الذين لديهم وصول كافٍ نظرياً الوصول إلى أنظمتك. يمكن أن تصل العملية القانونية المقدمة على مزود السحابة إلى بياناتك.
بالإضافة إلى ذلك، تحمل مثيلات GPU للسحابة الخاصة تكاليف كبيرة. تعمل مثيلات AWS p4d.24xlarge (8x A100 GPUs) بحوالي 32 دولاراً في الساعة. تولد عمليات التدريب الممتدة أو خدمات الاستدلال المستمرة نفقات شهرية كبيرة. التوافر مقيد—تظهر مثيلات GPU بشكل متكرر قوائم انتظار أو توافر إقليمي محدود.
إيجارات GPU اللامركزية
يتجاوز خيار ثالث كلاً من النفقات الرأسمالية ومشاركة مزود السحابة. تربط أسواق GPU اللامركزية المستخدمين مباشرة بمالكي العتاد. تستأجر قدرة الحوسبة من نظير إلى نظير، تدفع بالعملة المشفرة، دون التحقق من الهوية أو وساطة مزود السحابة.
يوفر هذا النموذج عدة مزايا للمؤسسات المهتمة بالخصوصية:
-
لا متطلبات KYC: تربط محفظة وتستأجر عتاداً. لا حسابات مؤسسية. لا عملية مبيعات مؤسسية. لا توثيق هوية يربط مؤسستك بأنشطة ذكاء اصطناعي محددة.
-
لا مشاركة مزود سحابة: تُعالج بياناتك على عتاد مملوك لأفراد، ليس لشركات لديها أقسام قانونية وعقود حكومية وعلاقات مع جهات إنفاذ القانون.
-
كفاءة التكلفة: تعمل إيجارات RTX 4090 بين 0.40 و0.60 دولار في الساعة، حوالي عُشر تكلفة مثيلات السحابة المماثلة. تفصّل مقارنة أسعار إيجار GPU الاقتصاديات.
-
التوافر العالمي: يعني العرض اللامركزي عدم وجود قيود إقليمية. العتاد متاح عندما تحتاجه، موزع عبر الولايات القضائية في جميع أنحاء العالم.
بالنسبة للمؤسسات التي لا تستطيع تبرير النفقات الرأسمالية على عتاد GPU لكنها تتطلب ضمانات خصوصية أقوى مما يقدمه مزودو السحابة، توفر الإيجارات اللامركزية مساراً وسطاً عملياً.
يتضمن سير العمل نقل بياناتك مباشرة إلى عقدة الإيجار عبر اتصال SSH مشفر، وتشغيل مهمة التدريب أو الاستدلال، وتنزيل النتائج، وتنظيف البيئة البعيدة قبل قطع الاتصال. يغطي دليلنا حول تأمين مجموعة بياناتك على عقدة GPU عامة ممارسات الأمان التشغيلي بالتفصيل.
تنفيذ استراتيجية ذكاء اصطناعي متوافقة
يجب على المؤسسات التي تنتقل من حظر ChatGPT إلى نشر الذكاء الاصطناعي الخاص أن تتعامل مع الانتقال بشكل منهجي.
المرحلة الأولى: تطوير السياسات
ابدأ بتوضيح ما تحظره سياسة الذكاء الاصطناعي الخاصة بك فعلياً وما تسمح به. كانت العديد من حظورات ChatGPT الأولية تفاعلية—حظورات شاملة نُفذت بسرعة لإيقاف المخاطر الفورية. تميز السياسة الناضجة بين:
- فئات البيانات التي لا يجب معالجتها أبداً بواسطة أنظمة ذكاء اصطناعي خارجية
- حالات الاستخدام التي تكون فيها خدمات الذكاء الاصطناعي السحابية مقبولة مع ضوابط مناسبة
- الأدوات والمنصات المعتمدة لمستويات الحساسية المختلفة
- عمليات الموافقة على اعتماد أدوات ذكاء اصطناعي جديدة
- متطلبات الإبلاغ عن الحوادث لانتهاكات السياسة
يسمح هذا الإطار باستمرار استخدام الذكاء الاصطناعي حيث يكون مناسباً مع حماية العمليات الحساسة.
المرحلة الثانية: تقييم البنية التحتية
قيّم خياراتك لنشر الذكاء الاصطناعي الخاص بناءً على موارد المؤسسة ومتطلباتها:
-
موارد GPU الموجودة: العديد من المؤسسات لديها محطات عمل أو خوادم مع وحدات NVIDIA GPUs تُستخدم لأغراض أخرى (التصور، العرض، الحوسبة العلمية) يمكن أن تدعم أحمال عمل الذكاء الاصطناعي.
-
ميزانية السحابة وتحمل المخاطر: إذا قبل فريق الأمان الخاص بك مشاركة مزود السحابة مع ضوابط مناسبة، توفر مثيلات GPU للسحابة الخاصة عمليات أبسط من الخيارات المحلية أو اللامركزية.
-
متطلبات الخصوصية: إذا كانت حالة استخدامك تتضمن بيانات لا يمكن أن تلمس بنية مزود السحابة التحتية تحت أي ظروف، يصبح العتاد المحلي أو الإيجارات اللامركزية ضرورياً.
-
الحجم والتكرار: تناسب مهام الضبط الدقيق العرضية نماذج الإيجار. قد يبرر خدمة الاستدلال المستمرة الاستثمار الرأسمالي.
المرحلة الثالثة: اختيار النموذج والتخصيص
توفر النماذج مفتوحة الأوزان العامة نقطة انطلاق، لكن القيمة المؤسسية تأتي من التخصيص. الضبط الدقيق على بياناتك ينشئ نماذج تفهم مجالك ومصطلحاتك ومتطلباتك.
فكر في حالات الاستخدام التي تقدم أعلى قيمة:
- تحليل الوثائق: العقود القانونية، الملفات التنظيمية، السياسات الداخلية
- مساعدة الأكواد: التطوير ضمن أطرك ومعاييرك المحددة
- تواصل العملاء: ردود تعكس صوت علامتك التجارية ومعرفة منتجك
- المعرفة الداخلية: الاستعلام عن توثيق المؤسسة والمعرفة المؤسسية
قد تستدعي كل حالة استخدام نموذجاً مضبوطاً بدقة منفصلاً، أو قد يخدم نموذج واحد مدرب على بيانات مؤسسية متنوعة أغراضاً متعددة.
المرحلة الرابعة: التكامل التشغيلي
يتطلب نشر الذكاء الاصطناعي الخاص قدرات تشغيلية تخفيها منتجات SaaS:
-
بنية خدمة النموذج التحتية: يتطلب تشغيل الاستدلال على نطاق واسع موارد GPU وموازنة الحمل وواجهات API. تبسط أدوات مثل vLLM وText Generation Inference وOllama النشر.
-
ضوابط الوصول: من يمكنه الاستعلام من النموذج؟ ما التسجيل الذي يحدث؟ كيف تدقق الاستخدام؟
-
إجراءات التحديث: كيف تدمج بيانات التدريب الجديدة؟ كيف تنشر إصدارات النموذج المحسنة؟
-
الاستجابة للحوادث: ماذا يحدث إذا أنتج نموذج مخرجات إشكالية؟ من يراجع الحالات الحدية؟
قد تقلل المؤسسات المعتادة على بساطة SaaS من تقدير هذه الأعباء التشغيلية. خصص الميزانية بشكل مناسب للصيانة المستمرة، وليس فقط النشر الأولي.
دراسة حالة: بنية الامتثال للخدمات المالية
واجه بنك إقليمي بأصول 50 مليار دولار معضلة مألوفة. أراد مديرو العلاقات مساعدة الذكاء الاصطناعي في صياغة اتصالات العملاء وتحليل مراكز المحافظ. أدرك مسؤولو الامتثال أن نقل البيانات المالية للعملاء إلى ChatGPT ينتهك كلاً من المتطلبات التنظيمية والواجبات الائتمانية.
توضح بنية الحل كيف يمكن للمؤسسات إرضاء كلا الطرفين.
تصنيف البيانات
أنشأ البنك ثلاثة مستويات من البيانات المسموح بها للذكاء الاصطناعي:
-
المستوى الأول (عام): مواد التسويق، محتوى التثقيف المالي العام، أوصاف المنتجات العامة. خدمات الذكاء الاصطناعي السحابية مسموح بها مع إرشادات الاستخدام المقبول القياسية.
-
المستوى الثاني (داخلي): السياسات الداخلية، مواد التدريب، إجراءات التشغيل. خدمات الذكاء الاصطناعي السحابية مسموح بها مع اتفاقيات مؤسسية وملحقات التعامل مع البيانات.
-
المستوى الثالث (مقيد): بيانات العملاء، معلومات المحفظة، تفاصيل المعاملات، التخطيط الاستراتيجي. لا معالجة ذكاء اصطناعي خارجية تحت أي ظروف.
سمح هذا التصنيف باعتماد الذكاء الاصطناعي حيث يكون الخطر مقبولاً مع الحفاظ على الحماية المطلقة للفئات الحساسة.
نشر البنية التحتية الخاصة
لحالات استخدام المستوى الثالث، نشر البنك نموذج Llama مضبوطاً بدقة على خوادم GPU محلية داخل مركز بياناتهم الموجود. تم تدريب النموذج على:
- اتصالات عملاء تاريخية مجهولة الهوية (بموافقة العميل)
- إرشادات الامتثال الداخلية والتفسيرات التنظيمية
- توثيق المنتجات وأبحاث الاستثمار
- قوالب الاتصال المعتمدة من الامتثال
فهم النموذج الناتج المصطلحات المصرفية والقيود التنظيمية ومعايير الاتصال المؤسسية. يمكن لمديري العلاقات صياغة رسائل العملاء بمساعدة الذكاء الاصطناعي، مع العلم أنه لا توجد بيانات عملاء تغادر محيط البنك الأمني.
ضوابط التشغيل
كل تفاعل مع النموذج سُجل في نظام أرشيف الامتثال الموجود لدى البنك. يمكن للمشرفين مراجعة الاتصالات بمساعدة الذكاء الاصطناعي إلى جانب المراسلات التقليدية. أدت مسارات التدقيق إلى تلبية متطلبات حفظ السجلات التنظيمية.
عمل النموذج نفسه ضمن حواجز تمنع مخرجات معينة—توصيات الاستثمار، لغة الضمان، أو البيانات التي قد تشكل نصيحة تتطلب ترخيصاً محدداً. تم تنفيذ هذه القيود على مستوى التطبيق، دون الاعتماد على سلوك النموذج وحده.
النتائج المقاسة
بعد ستة أشهر من النشر، أفاد البنك بـ:
- انخفاض 40٪ في الوقت المستغرق في صياغة اتصالات العملاء الروتينية
- صفر حوادث امتثال متعلقة باستخدام الذكاء الاصطناعي
- اجتياز ناجح للفحص التنظيمي بدون ملاحظات متعلقة بنشر الذكاء الاصطناعي
- زيادة درجات رضا مديري العلاقات
ولّد الاستثمار في البنية التحتية الخاصة—حوالي 200,000 دولار شاملة العتاد والتطوير والتكامل—عوائد خلال السنة الأولى من خلال مكاسب الإنتاجية وحدها.
دراسة حالة: مؤسسة بحوث الرعاية الصحية
واجه مركز طبي أكاديمي كبير يجري أبحاثاً سريرية قيود HIPAA التي جعلت أي استخدام للذكاء الاصطناعي السحابي مع بيانات المرضى إشكالياً قانونياً. أراد الباحثون استخدام الذكاء الاصطناعي لمراجعة الأدبيات وتطوير البروتوكولات وتحليل البيانات.
النهج الهجين
بدلاً من الاختيار بين الحظر الكامل والمخاطر غير المقبولة، نفذت المؤسسة بنية هجينة:
-
مهام البحث العامة (مراجعة الأدبيات، أسئلة المنهجية، المناهج الإحصائية) استخدمت خدمات الذكاء الاصطناعي السحابية مع سياسات واضحة تحظر أي إدخال لبيانات المرضى.
-
تحليل بيانات المرضى استخدم نماذج منشورة محلياً على محطات عمل معزولة عن الإنترنت داخل بيئة البحث الآمنة. لم تكن لهذه الأجهزة اتصال بالإنترنت. لا يمكن للبيانات المغادرة بغض النظر عن سلوك المستخدم.
التدريب اللامركزي
افتقرت المؤسسة إلى ميزانية رأسمالية لعتاد GPU قادر على التدريب لكنها احتاجت نماذج مضبوطة بدقة على الأدبيات الطبية وبروتوكولات البحث. استخدموا إيجارات GPU اللامركزية لعمليات التدريب باستخدام الأدبيات الطبية العامة فقط ومجموعات البيانات مجهولة الهوية بدون آثار HIPAA.
اتبع سير عمل التدريب ممارسات الأمان الموضحة في دليلنا أمان مجموعة البيانات:
- نقل بيانات التدريب غير الحساسة فقط إلى عقد الإيجار
- تنفيذ مهام الضبط الدقيق
- تنزيل أوزان النموذج الناتجة
- تنظيف البيئات البعيدة بالكامل
- نشر النماذج المدربة على البنية التحتية الداخلية المعزولة
وفر هذا النهج قدرات ذكاء اصطناعي طبية مخصصة دون تعريض أي معلومات صحية محمية لأنظمة خارجية.
التحقق التنظيمي
راجعت لجنة المراجعة المؤسسية نشر الذكاء الاصطناعي كجزء من تعديلات بروتوكول البحث. أرضى الفصل الواضح بين تدريب البيانات العامة (خارجي) واستدلال بيانات المرضى (داخلي، معزول) متطلبات الخصوصية. وافق مسؤولو امتثال HIPAA على البنية بعد تقييم الأمان.

الضرورة الاستراتيجية
المؤسسات التي تنظر إلى سياسة الذكاء الاصطناعي من منظور تخفيف المخاطر فقط تفوّت الصورة الأكبر. المؤسسات التي تحظر ChatGPT اليوم لا تتخلى عن الذكاء الاصطناعي. إنها تعيد التموضع للميزة المستدامة.
التمايز التنافسي من خلال البيانات
تنبثق قدرات الذكاء الاصطناعي الأكثر قيمة من البيانات الخاصة. نموذج لغوي عام مدرب على نص الإنترنت يوفر قدرات عامة متاحة للجميع. نموذج مضبوط بدقة على تفاعلات عملائك وبياناتك التشغيلية ومعرفتك المؤسسية يوفر قدرات فريدة لمؤسستك.
يتطلب هذا التمايز الحفاظ على خصوصية البيانات الخاصة. المؤسسات التي تغذي مزاياها التنافسية في خدمات الذكاء الاصطناعي السحابية تساهم في نماذج تفيد جميع المستخدمين—بما في ذلك المنافسون. المؤسسات التي تحافظ على التحكم في البيانات أثناء نشر الذكاء الاصطناعي الخاص تراكم مزايا تتراكم مع مرور الوقت.
المسار التنظيمي
تنظيم الذكاء الاصطناعي يتشدد،