
Das Memo befriedigt niemanden, aber verändert alles.
Als Samsungs Halbleitersparte entdeckte, dass Ingenieure proprietäre Chipdesigns zu ChatGPT hochgeladen hatten, war die Reaktion sofort und absolut. Ein unternehmensweites Verbot. Keine Ausnahmen. Kein Einspruchsverfahren. Das Tool, das zum Synonym für KI-Produktivität geworden war, war nun in allen Unternehmensnetzwerken verboten.
Samsung war nicht allein. Innerhalb von Monaten kamen ähnliche Ankündigungen von JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank und Dutzenden anderen Unternehmen. Anwaltskanzleien, die Fortune-500-Unternehmen beraten, verboten Associates die Nutzung des Dienstes. Gesundheitssysteme blockierten den Zugang auf Firewall-Ebene. Regierungsbehörden gaben Richtlinien heraus, die jede Unklarheit über akzeptable Nutzung effektiv beendeten.
Das Muster offenbarte etwas, das Technologie-Enthusiasten in ihrer Begeisterung für KI-Fähigkeiten übersehen hatten: Die Unternehmensadoption operiert unter Einschränkungen, die für die Verbraucheradoption nicht gelten.
Dieser Artikel untersucht, warum sich Unternehmens-KI-Richtlinien verschärfen, welche spezifischen Risiken diese Entscheidungen antreiben und wie Organisationen KI-Fähigkeiten aufrechterhalten können, ohne inakzeptable Datenexposition zu akzeptieren. Der Weg nach vorne erfordert nicht, KI aufzugeben. Er erfordert das Verständnis, dass die Infrastruktur genauso wichtig ist wie die Intelligenz.

Die Vorfälle, die alles veränderten
Unternehmens-KI-Verbote entstanden nicht aus theoretischen Risikobewertungen. Sie folgten auf tatsächliche Vorfälle, bei denen vertrauliche Informationen der organisatorischen Kontrolle entkamen.
Der Samsung-Halbleiter-Vorfall
Anfang 2023 nutzten Mitarbeiter von Samsung Electronics ChatGPT, um Quellcode zu debuggen und Halbleiterfertigungsprozesse zu optimieren. Ingenieure fügten proprietären Code direkt in die Chat-Oberfläche ein. Andere luden Besprechungsnotizen hoch, die strategische Planungsdiskussionen enthielten. Innerhalb von drei Wochen nach der Genehmigung von ChatGPT für die interne Nutzung identifizierte Samsungs Informationssicherheitsteam mehrere Fälle von vertraulicher Datenübertragung an OpenAI-Server.
Die Halbleiterindustrie operiert mit Margen, die in Nanometern gemessen werden, und Wettbewerbsvorteilen, die in Monaten gemessen werden. Die Möglichkeit, dass Samsungs Fertigungsprozesse nun im Trainingskorpus von OpenAI residierten—potenziell zugänglich für Wettbewerber, die denselben Dienst nutzen—war inakzeptabel. Samsung implementierte ein vollständiges Verbot und begann mit der Entwicklung interner KI-Tools, die niemals Daten extern übertragen würden.
Reaktion der Finanzdienstleistungsbranche
JPMorgan Chase schränkte den ChatGPT-Zugang ein, bevor ein öffentlich bekannter Vorfall eintrat, und erkannte die regulatorischen Implikationen proaktiv. Wenn Bankmitarbeiter Kundenportfolios analysieren, Fusionsstrategien diskutieren oder Kreditrisiken bewerten, behandeln sie Informationen, die SEC-Vorschriften, Bankgeheimnisgesetzen und Treuepflichten unterliegen. Die Übertragung solcher Informationen an einen Drittanbieter-KI-Dienst—unabhängig von den angegebenen Datenschutzrichtlinien dieses Dienstes—schafft Compliance-Risiken, die kein General Counsel akzeptieren würde.
Goldman Sachs, Citigroup, Bank of America und Deutsche Bank folgten mit ähnlichen Einschränkungen. Die koordinierte Reaktion der Finanzdienstleistungsbranche spiegelte nicht Paranoia wider, sondern professionelles Verständnis regulatorischer Haftung. Ein Datenleck, das durch die ChatGPT-Nutzung von Mitarbeitern entsteht, würde eine Offenlegung erfordern, eine regulatorische Untersuchung auslösen und möglicherweise zu Durchsetzungsmaßnahmen führen.
Implikationen für die Rechtsbranche
Die American Bar Association hat kein pauschales Verbot von KI-Tools erlassen, aber die praktische Wirkung der Anforderungen an das Anwalt-Mandanten-Privileg kommt dem nahe. Wenn ein Anwalt Mandantenangelegenheiten mit ChatGPT bespricht, kann das Gespräch den Privilegschutz aufheben. Informationen, die Dritten offengelegt werden—auch KI-Systemen—können die Vertraulichkeit verlieren, die Rechtsberatung schützt.
Große Anwaltskanzleien wie Davis Polk, Cravath und Sullivan & Cromwell implementierten Einschränkungen, die von vollständigen Verboten bis hin zu Nur-genehmigte-Nutzung-Richtlinien reichen, die eine Partnergenehmigung erfordern. Die Reaktion des Rechtsberufs zeigte, dass KI-Risiken über die Datensicherheit hinaus grundlegende Fragen der beruflichen Verantwortung berühren.
Die technische Realität der Cloud-KI-Datenverarbeitung
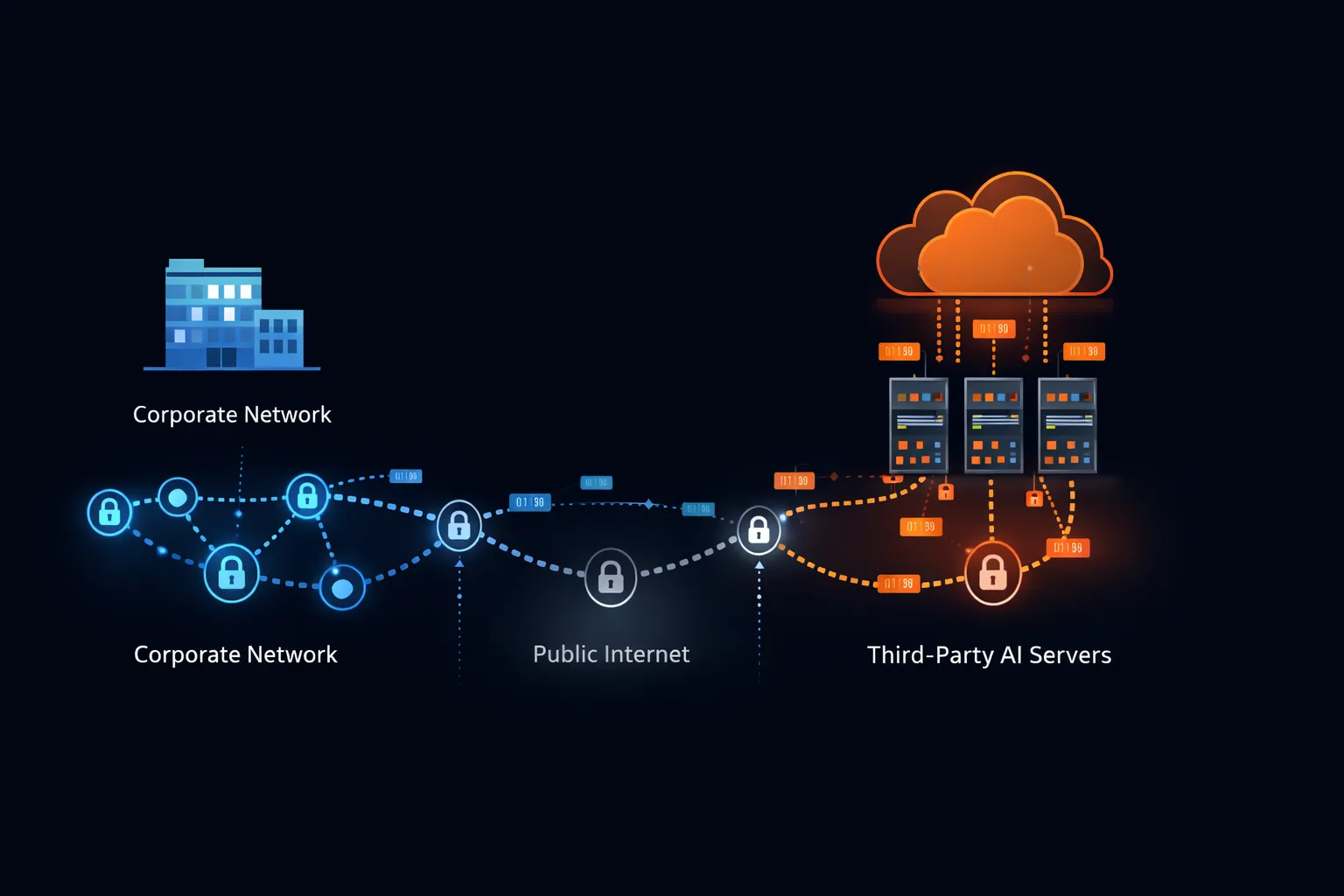
Um zu verstehen, warum Unternehmen ChatGPT verbieten, muss man untersuchen, was tatsächlich passiert, wenn Sie eine Nachricht an einen Cloud-KI-Dienst senden.
Datenübertragungspfad
Wenn Sie einen Prompt in ChatGPT eingeben, reist Ihr Text von Ihrem Gerät über Ihr Unternehmensnetzwerk, über das öffentliche Internet zur Infrastruktur von OpenAI. OpenAI betreibt hauptsächlich auf Microsoft Azure, was bedeutet, dass Ihre Daten das Microsoft-Netzwerk durchqueren und auf von Microsoft verwalteten Servern residieren.
Diese Übertragung erfolgt unabhängig von der Sensibilität des Inhalts. Das System kann nicht zwischen einer Anfrage, ein Gedicht zu schreiben, und einer Anfrage, vertrauliche Fusionsbedingungen zu analysieren, unterscheiden. Jedes Zeichen, das Sie eingeben, folgt demselben Pfad zum selben Ziel.
Datenaufbewahrungsrichtlinien
Die Datennutzungsrichtlinien von OpenAI haben sich im Laufe der Zeit weiterentwickelt, aber bestimmte Grundlagen bleiben konsistent. Benutzereingaben werden protokolliert. Gespräche werden gespeichert. Die Dauer und der Zweck der Speicherung hängen von Ihrer Abonnementstufe und spezifischen Vereinbarungen ab.
Für Free-Tier- und Plus-Abonnenten behält sich OpenAI ausdrücklich das Recht vor, Eingaben zur Modellverbesserung zu verwenden. Ihre Prompts werden zu Trainingsdaten. Der vertrauliche Code, den Sie eingefügt haben, um ein Problem zu debuggen, kann beeinflussen, wie das Modell zukünftigen Nutzern antwortet—möglicherweise einschließlich Ihrer Wettbewerber.
API-Nutzer und Enterprise-Abonnenten können der Trainingsdatenbeitragung widersprechen, aber ihre Eingaben werden weiterhin auf OpenAI-Infrastruktur verarbeitet. Daten existieren weiterhin auf Servern, die Sie nicht kontrollieren, verwaltet von Mitarbeitern, die Sie nicht überprüft haben, und unterliegen rechtlichen Prozessen, die Sie nicht beeinflussen können.
Das Drittanbieter-Problem
Unternehmenssicherheitsarchitekturen unterscheiden zwischen Erstanbieter-Systemen (Infrastruktur, die Sie besitzen und betreiben), Zweitanbieter-Systemen (Anbieter mit direkten Vertragsbeziehungen und geprüften Sicherheitskontrollen) und Drittanbieter-Systemen (Dienste, auf die ohne detaillierte Sicherheitsintegration zugegriffen wird).
ChatGPT operiert für die meisten Nutzer als ungeprüfter Drittanbieter. Sofern Ihre Organisation keine spezifische Unternehmensvereinbarung mit Sicherheitszusätzen, Penetrationstestrechten und auf Ihre Anforderungen abgestimmten Compliance-Zertifizierungen ausgehandelt hat, sitzt ChatGPT außerhalb Ihres Sicherheitsperimeters mit Zugang zu allen Daten, die Mitarbeiter zu teilen wählen.
Diese architektonische Realität erklärt, warum Sicherheitsteams ChatGPT anders behandeln als Microsoft Office oder Salesforce. Diese Systeme, obwohl Cloud-basiert, operieren unter Unternehmensvereinbarungen mit definierten Sicherheitskontrollen, Prüfrechten und Haftungsbedingungen. ChatGPT bietet für einen Nutzer mit einem 20-Dollar-pro-Monat-Abonnement keinen dieser Schutzmaßnahmen.
Regulatorische Rahmenwerke, die Unternehmensvorsorge antreiben
Unternehmens-KI-Richtlinien existieren nicht im Vakuum. Sie reagieren auf gesetzliche Anforderungen, die vor ChatGPT bestanden und es überdauern werden.
DSGVO und europäischer Datenschutz
Die Datenschutz-Grundverordnung stellt strenge Anforderungen an die Verarbeitung personenbezogener Daten von EU-Bürgern. Wenn ein Mitarbeiter Kundeninformationen in ChatGPT einfügt, initiiert er eine Datenübertragung an einen in den USA ansässigen Verarbeiter. Diese Übertragung erfordert eine Rechtsgrundlage—entweder Angemessenheitsbeschlüsse, Standardvertragsklauseln oder verbindliche Unternehmensregeln.
Die Datenverarbeitungsvereinbarungen von OpenAI können DSGVO-Anforderungen für einige Anwendungsfälle erfüllen, aber die meisten Mitarbeiter, die das Verbraucherprodukt nutzen, haben keine solche Vereinbarung. Sie übertragen einfach personenbezogene Daten an ein ausländisches Unternehmen ohne Genehmigung.
Italienische Regulierungsbehörden verboten ChatGPT 2023 vorübergehend speziell wegen DSGVO-Bedenken. Obwohl der Dienst wieder aufgenommen wurde, nachdem OpenAI Compliance-Anpassungen vorgenommen hatte, zeigte der Vorfall die Bereitschaft der Regulierungsbehörden zu handeln. Europäische Unternehmen sind direkt haftbar für Mitarbeiterhandlungen, die gegen die DSGVO verstoßen, was starke Anreize für restriktive Richtlinien schafft.
HIPAA und Gesundheitsdaten
Der Health Insurance Portability and Accountability Act verbietet die Offenlegung geschützter Gesundheitsinformationen (PHI) außer unter bestimmten autorisierten Umständen. Ein Mitarbeiter im Gesundheitswesen, der Patientenfälle mit ChatGPT bespricht, offenbart PHI gegenüber einem nicht autorisierten Empfänger.
Es existiert keine Business-Associate-Vereinbarung zwischen typischen Gesundheitsorganisationen und OpenAI. Kein Sicherheitsaudit hat die Konformität von ChatGPT mit den technischen Schutzmaßnahmen von HIPAA verifiziert. Kein rechtlicher Rahmen autorisiert die Offenlegung.
Gesundheitsorganisationen, die entdecken, dass Mitarbeiter PHI über ChatGPT geteilt haben, sehen sich Anforderungen zur Benachrichtigung über Verstöße, potenziellen OCR-Untersuchungen und Strafen von bis zu 1,5 Millionen Dollar pro Verstoßkategorie pro Jahr gegenüber. Diese Konsequenzen erklären, warum Krankenhaussysteme ChatGPT auf Netzwerkebene blockieren, anstatt sich auf Richtlinienkonformität zu verlassen.
Finanzvorschriften
Banken, Broker-Dealer und Anlageberater operieren unter SEC-, FINRA-, OCC- und Federal-Reserve-Vorschriften, die Aufzeichnungspflichten und Überwachung von Geschäftskommunikation vorschreiben. Wenn ein Analyst ChatGPT nutzt, um Kundenkorrespondenz zu verfassen, sollte dieses Gespräch in Compliance-Archiven erfasst werden.
ChatGPT bietet keine Integration mit Unternehmensarchivierungssystemen. Keine Überwachungstools kennzeichnen potenziell problematische Nutzung. Das Gespräch existiert nur auf OpenAI-Servern und dem Gerät des Mitarbeiters—keines von beiden erfüllt regulatorische Aufzeichnungsanforderungen.
Über die Aufzeichnung hinaus äußern Finanzregulierer Bedenken hinsichtlich KI-generierter Anlageberatung, KI-Beteiligung an Kreditentscheidungen und KI-Analysen, die Marktmanipulation darstellen könnten. Die regulatorische Landschaft bleibt ungewiss, und Compliance-Beauftragte reagieren auf Unsicherheit, indem sie die Nutzung einschränken, anstatt sie bis zur Klärung zu erlauben.
Aufkommende KI-spezifische Regulierung
Der EU AI Act, der voraussichtlich progressiv 2025 und 2026 in Kraft treten wird, wird zusätzliche Anforderungen an den Einsatz von KI-Systemen stellen. Hochrisiko-KI-Anwendungen—einschließlich solcher, die Beschäftigung, Kredit und Bildung betreffen—erfordern Konformitätsbewertungen, Dokumentation und menschliche Aufsicht.
Organisationen, die ChatGPT in diesen Kontexten nutzen, könnten feststellen, dass sie nicht konforme KI-Systeme betreiben, sobald die Vorschriften in Kraft treten. Proaktive Unternehmen schränken die Nutzung jetzt ein, anstatt später Compliance-Korrekturen vorzunehmen.
Geistiges Eigentum: Das Risiko, das kein Vertrag löst
Regulatorische Compliance repräsentiert eine Kategorie von Bedenken. Der Schutz geistigen Eigentums repräsentiert eine andere—und für viele Unternehmen die folgenreichere.
Geschäftsgeheimnisse und Vertraulichkeit
Der Schutz von Geschäftsgeheimnissen nach dem Defend Trade Secrets Act und staatlichen Äquivalenten erfordert, dass Informationen durch angemessene Schutzmaßnahmen vertraulich bleiben. Wenn ein Mitarbeiter proprietäre Algorithmen, Fertigungsprozesse oder strategische Pläne in ChatGPT einfügt, haben die Schutzmaßnahmen der Organisation versagt.
Gerichte, die Ansprüche auf Geschäftsgeheimnisse bewerten, prüfen, ob die anspruchserhebende Partei angemessene Schritte zur Wahrung der Geheimhaltung unternommen hat. Die Erlaubnis für Mitarbeiter, vertrauliche Informationen mit Drittanbieter-KI-Diensten zu teilen, untergräbt diese Anforderung. Selbst wenn die Informationen niemals aus OpenAIs Systemen durchsickern, kann der Akt der Offenlegung selbst den rechtlichen Schutz beeinträchtigen.
Diese Bedenken gehen über hypothetische Rechtsstreitigkeiten hinaus. Unternehmen erheben regelmäßig Ansprüche auf Geschäftsgeheimnisse gegen ausscheidende Mitarbeiter und Wettbewerber. Wenn die Offenlegung zeigt, dass die “geheimen” Informationen zuvor mit ChatGPT geteilt wurden—zugänglich für Millionen von Nutzern durch potenzielle Modelltraining—schwächt sich der Anspruch erheblich.
Quellcode und technische Vermögenswerte
Softwareunternehmen sind besonders exponiert. Entwickler wollen natürlich KI-Tools zum Debuggen von Code, zum Generieren von Boilerplate und zur Beschleunigung der Entwicklung nutzen. Aber Quellcode repräsentiert das Kernvermögen eines Softwareunternehmens. Einmal an ChatGPT übertragen, existiert dieser Code außerhalb der organisatorischen Kontrolle.
Das Bedenken bezüglich Trainingsdaten ist nicht theoretisch. Große Sprachmodelle lernen aus ihren Eingaben. Während OpenAI angibt, dass Enterprise- und API-Kunden dem Trainingsbeitrag widersprechen können, bietet das Verbraucherprodukt keine solche Garantie. Von einem Entwickler geteilter Code kann Vervollständigungen beeinflussen, die einem anderen Entwickler angezeigt werden—möglicherweise bei einem konkurrierenden Unternehmen.
Amazons interne Warnung an Mitarbeiter verwies speziell auf das Risiko, dass ChatGPT-Antworten vertraulichen Amazon-Informationen ähneln könnten, was darauf hindeutet, dass ähnliche Daten bereits in das Modell eingeflossen waren. Ob dies tatsächlichen Amazon-Code in Trainingsdaten oder einfach ähnliche Muster darstellte, bleibt unklar. Die Unklarheit selbst trieb die restriktive Richtlinie an.
Kunden- und Mandanteninformationen
Professionelle Dienstleistungsunternehmen—Berater, Buchhalter, Anwälte, Architekten—arbeiten mit Kundeninformationen, die diesen Kunden gehören, nicht dem Dienstleister. Das Teilen von Kundendaten mit ChatGPT kann gegen Auftragsschreiben, Vertraulichkeitsvereinbarungen und berufsethische Regeln verstoßen.
Ein Berater, der Finanzprognosen eines Kunden zur Analyse zu ChatGPT hochlädt, hat die vertraulichen Informationen dieses Kunden mit einem Dritten geteilt. Die Firma des Beraters kann mit Vertragsverletzungsklagen, berufsrechtlicher Disziplinierung und Verlust von Kundenbeziehungen konfrontiert werden, wenn dies entdeckt wird.
Diese Bedenken gelten gleichermaßen für jedes Unternehmen, das mit Kundendaten umgeht. Ein Vertriebsmitarbeiter, der Kundenkorrespondenz in ChatGPT einfügt, um eine Antwort zu verfassen, hat Kundenkommunikation an OpenAI übertragen. Je nach Branche und geltenden Vereinbarungen kann dies gegen Verpflichtungen zum Umgang mit Kundendaten verstoßen.

Die Unzulänglichkeit von Enterprise-KI-Vereinbarungen
OpenAI bietet ChatGPT Enterprise speziell an, um Unternehmensbedenken zu adressieren. Microsoft bietet Azure OpenAI Service mit Enterprise-Sicherheitsfunktionen. Diese Produkte verbessern sich gegenüber Verbraucherangeboten, beseitigen aber nicht grundlegende Bedenken für hochsensible Anwendungsfälle.
Was Enterprise-Vereinbarungen bieten
ChatGPT Enterprise umfasst mehrere bedeutende Verbesserungen:
- Daten werden nicht für Modelltraining verwendet
- SOC 2 Type 2 Compliance-Zertifizierung
- Datenverschlüsselung im Ruhezustand und bei der Übertragung
- SSO-Integration und administrative Kontrollen
- Datenaufbewahrungskontrollen
Diese Funktionen erfüllen Anforderungen für viele Unternehmensanwendungsfälle. Ein Marketingteam, das Kampagnentexte verfasst, ist minimalem Risiko ausgesetzt. Eine Kundendienstabteilung, die Antwortvorlagen generiert, operiert innerhalb akzeptabler Parameter.
Was Enterprise-Vereinbarungen nicht bieten können
Für regulierte Branchen und sensibles geistiges Eigentum bleiben Enterprise-Vereinbarungen auf grundlegende Weise unzureichend.
Erstens werden Daten weiterhin auf Infrastruktur verarbeitet, die Sie nicht kontrollieren. Ihre Informationen residieren auf OpenAI-Servern, verwaltet von OpenAI-Mitarbeitern, unterliegen OpenAIs Sicherheitspraktiken. Sie vertrauen ihrer Implementierung. Sie vertrauen ihrer Personalüberprüfung. Sie vertrauen ihrer Incident-Response. Dieses Vertrauen mag gerechtfertigt sein, aber es ist dennoch Vertrauen—nicht Verifizierung.
Zweitens bleiben Daten rechtlichen Prozessen unterworfen. Eine OpenAI zugestellte Vorladung könnte die Offenlegung Ihrer Gespräche erzwingen. Eine Regierungsuntersuchung eines anderen Kunden könnte potenziell gemeinsame Infrastruktur offenlegen. National Security Letters und FISA-Gerichtsbeschlüsse operieren unter Geheimhaltungsanforderungen, die OpenAI daran hindern würden, Sie über den Zugriff zu informieren.
Drittens umfasst die Angriffsfläche die gesamte OpenAI-Organisation. Ihr Sicherheitsperimeter endet nicht mehr an Ihrer Netzwerkgrenze. Jeder OpenAI-Mitarbeiter mit Systemzugang, jeder Anbieter mit Infrastrukturzugang, jede Sicherheitslücke in OpenAIs Systemen wird Teil Ihres Risikoprofils.
Viertens bleiben Exit und Portabilität eingeschränkt. Ihr Gesprächsverlauf, feinabgestimmte Verhaltensweisen und in ChatGPT angesammeltes Organisationswissen gehören zu Interaktionen mit OpenAIs System. Die Migration zu einer Alternative erfordert einen Neuaufbau von Grund auf.
Für ein Pharmaunternehmen, das neuartige Verbindungen entwickelt, einen Verteidigungsunternehmer, der Forschung im Graubereich der Geheimhaltung handhabt, oder ein Finanzinstitut mit Handelsalgorithmen, die Milliarden an potenziellem Wert darstellen, sind diese Einschränkungen von Bedeutung. Enterprise-Vereinbarungen reduzieren das Risiko. Sie beseitigen es nicht.
Die Open-Weights-Alternative
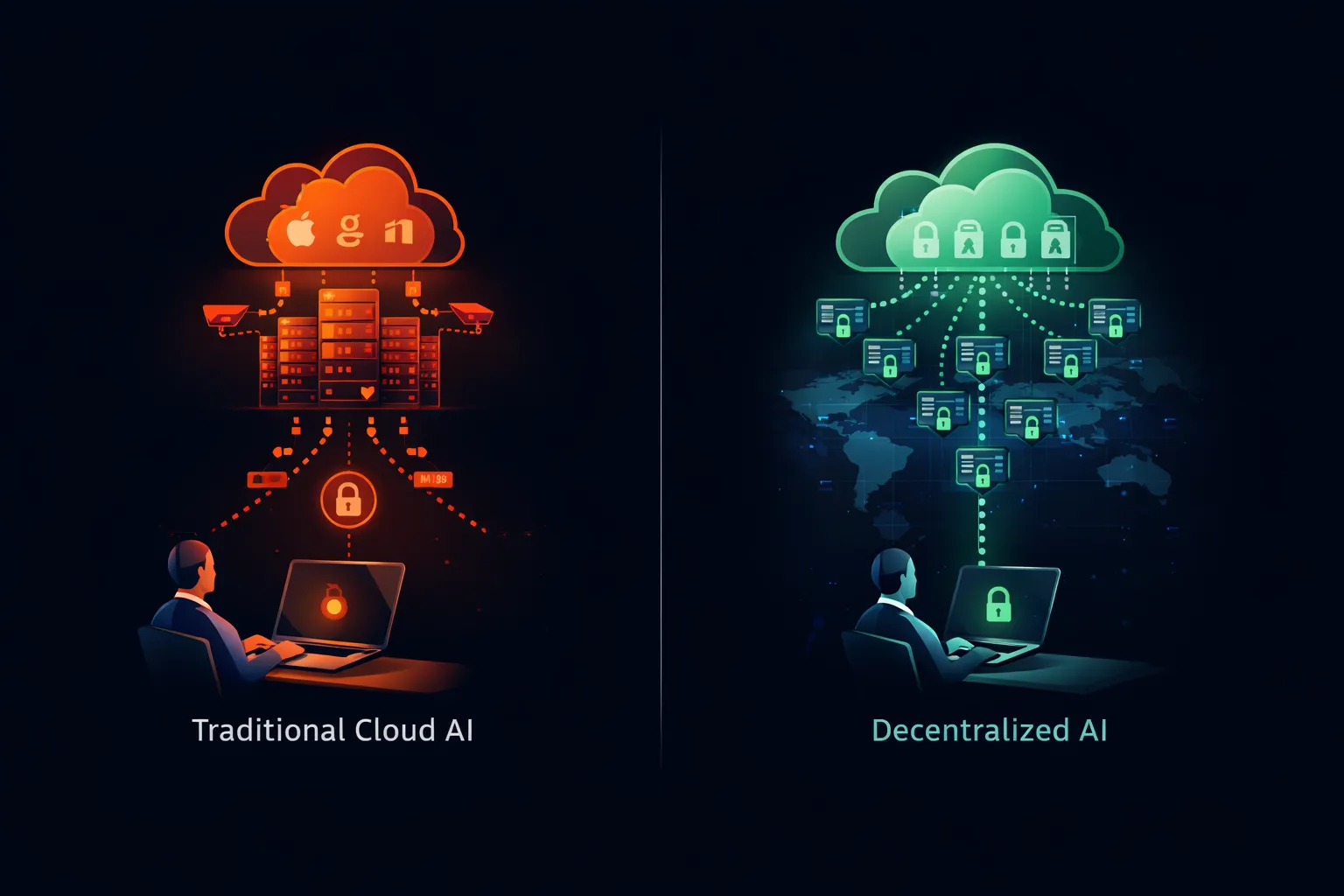
Die Einschränkungen, die Unternehmens-ChatGPT-Verbote antreiben, gelten nicht für KI im Allgemeinen. Sie gelten speziell für Cloud-KI-Dienste, bei denen Daten die organisatorische Kontrolle verlassen. Eine andere Architektur beseitigt diese Bedenken vollständig.
Was Open-Weights-Modelle bieten
Open-Weights-Modelle—Llama von Meta, Mistral von Mistral AI, Qwen von Alibaba und Dutzende andere—bieten herunterladbare Modelldateien, die auf jeder kompatiblen Hardware laufen. Die Modellgewichte sind öffentlich. Der Inferenzcode ist Open Source. Sie können das gesamte System auf Infrastruktur ausführen, die Sie besitzen und betreiben.
Wenn Sie Llama auf Ihrem eigenen Server ausführen, verlassen Ihre Prompts niemals Ihr Netzwerk. Kein Dritter empfängt Ihre Daten. Kein Cloud-Dienst protokolliert Ihre Anfragen. Keine Trainingspipeline inkorporiert Ihre Eingaben. Das Modell läuft lokal, verarbeitet lokal und speichert nichts außer dem, was Sie explizit konfigurieren.
Diese Architektur befriedigt jedes Bedenken, das ChatGPT-Verbote antreibt:
-
Regulatorische Compliance: Daten verbleiben innerhalb Ihres Sicherheitsperimeters, unterliegen Ihren Kontrollen, werden durch Ihre Richtlinien geregelt. DSGVO-Datenübertragungen finden nicht statt, weil Daten nicht übertragen werden. HIPAA-Bedenken lösen sich auf, weil keine Offenlegung an nicht autorisierte Parteien erfolgt.
-
Schutz geistigen Eigentums: Geschäftsgeheimnisse bleiben geheim. Quellcode verlässt niemals Ihre Systeme. Kundenvertraulichkeit wird gewahrt, weil kein Dritter Kundeninformationen erhält.
-
Sicherheitskontrolle: Ihre Angriffsfläche bleibt Ihre eigene. Sie verifizieren Ihre Sicherheitspraktiken. Sie überprüfen Ihr Personal. Sie kontrollieren Ihre Incident-Response. Die Schwachstellen keiner externen Organisation betreffen Ihre Daten.
-
Audit und Compliance: Jede Anfrage, jede Antwort, jede Modellinteraktion kann gemäß Ihren Anforderungen protokolliert werden. Regulatorische Aufzeichnung integriert sich in Ihre bestehenden Archivsysteme.
Fähigkeitsvergleich
Die natürliche Frage ist, ob Open-Weights-Modelle die Fähigkeiten von ChatGPT erreichen. Die ehrliche Antwort: Es hängt vom Anwendungsfall ab.
Für allgemeine Wissensanfragen bietet ChatGPTs Training auf Daten im Internetmaßstab eine Breite, die kleinere offene Modelle nicht erreichen können. GPT-4s Reasoning-Fähigkeiten bei komplexen Problemen übertreffen das, was Llama-3-8B erreicht.
Aber Unternehmensanwendungsfälle erfordern selten Wissen im Internetmaßstab. Ein Rechtsteam, das Verträge analysiert, benötigt Dokumentenverständnis und präzise Sprachgenerierung—Fähigkeiten, bei denen feinabgestimmte offene Modelle hervorragend sind. Ein Entwicklungsteam, das Code debuggt, benötigt Mustererkennung innerhalb spezifischer Codebasen—eine Aufgabe, bei der benutzerdefiniertes Training generische Modelle deutlich übertrifft.
Die entscheidende Erkenntnis ist, dass Feinabstimmung generische Modelle in Domänenspezialisten verwandelt. Ein auf Ihre Organisationsdokumente, Codierungsstandards und Kommunikationsmuster feinabgestimmtes Llama-3-8B-Modell wird GPT-4 für Ihre spezifischen Aufgaben übertreffen und dabei vollständige Datenisolation aufrechterhalten.
Unser Pillar-Guide zum privaten LLM-Feintuning auf dezentralen GPUs bietet den vollständigen technischen Workflow für diesen Prozess.
Infrastrukturoptionen für private KI-Bereitstellung
Das Ausführen von Open-Weights-Modellen erfordert GPU-Rechenleistung. Organisationen haben mehrere Optionen, um diese Fähigkeit zu erwerben.
Lokale Hardware
Der Kauf von NVIDIA-GPUs für interne Rechenzentren bietet maximale Kontrolle. Die Hardware befindet sich in Ihrer Einrichtung, wird von Ihrem Personal verwaltet und ist mit Ihrem Netzwerk verbunden. Keine externe Partei hat irgendeinen Zugang.
Die Herausforderung sind Kapitalaufwand und Vorlaufzeit. Eine NVIDIA H100 GPU kostet ungefähr 30.000 Dollar. Ein bedeutungsvolles Cluster für Training erfordert mehrere Einheiten. Beschaffungszeiträume erstrecken sich über Monate. Laufende Wartung erfordert spezialisierte Expertise.
Für große Unternehmen mit bestehenden Rechenzentrumsbetrieben stellt lokale KI-Infrastruktur eine natürliche Erweiterung dar. Für kleinere Organisationen oder solche ohne GPU-Expertise sind die Barrieren erheblich.
Private Cloud-Instanzen
AWS, GCP und Azure bieten GPU-Instanzen, die mehr Kontrolle bieten als SaaS-KI-Produkte. Sie konfigurieren die Umgebung. Sie kontrollieren den Zugang. Ihre Daten werden auf dedizierten Instanzen statt auf geteilten Diensten verarbeitet.
Dieser Ansatz verbessert ChatGPTs Architektur, behält aber die Beteiligung des Cloud-Anbieters bei. Ihre Daten residieren weiterhin auf Infrastruktur, die Sie nicht physisch kontrollieren. Cloud-Anbieter-Mitarbeiter mit ausreichendem Zugang könnten theoretisch auf Ihre Systeme zugreifen. Rechtliche Prozesse, die dem Cloud-Anbieter zugestellt werden, könnten Ihre Daten erreichen.
Zusätzlich tragen private Cloud-GPU-Instanzen erhebliche Kosten. AWS p4d.24xlarge-Instanzen (8x A100 GPUs) kosten ungefähr 32 Dollar pro Stunde. Längere Trainingsläufe oder kontinuierliche Inferenzdienste generieren erhebliche monatliche Ausgaben. Die Verfügbarkeit ist eingeschränkt—GPU-Instanzen zeigen häufig Wartelisten oder begrenzte regionale Verfügbarkeit.
Dezentrale GPU-Anmietungen
Eine dritte Option umgeht sowohl Kapitalaufwand als auch Cloud-Anbieter-Beteiligung. Dezentrale GPU-Marktplätze verbinden Nutzer direkt mit Hardware-Besitzern. Sie mieten Rechenkapazität Peer-to-Peer, zahlen mit Kryptowährung, ohne Identitätsverifizierung oder Cloud-Anbieter-Vermittlung.
Dieses Modell bietet mehrere Vorteile für datenschutzbewusste Organisationen:
-
Keine KYC-Anforderungen: Sie verbinden eine Wallet und mieten Hardware. Keine Unternehmenskonten. Kein Enterprise-Vertriebsprozess. Keine Identitätsdokumentation, die Ihre Organisation mit spezifischen KI-Aktivitäten verbindet.
-
Keine Cloud-Anbieter-Beteiligung: Ihre Daten werden auf Hardware verarbeitet, die Einzelpersonen gehört, nicht Unternehmen mit Rechtsabteilungen, Regierungsverträgen und Beziehungen zu Strafverfolgungsbehörden.
-
Kosteneffizienz: RTX 4090-Anmietungen kosten 0,40 bis 0,60 Dollar pro Stunde, ungefähr ein Zehntel der Kosten vergleichbarer Cloud-Instanzen. Unser GPU-Mietpreis-Vergleich detailliert die Wirtschaftlichkeit.
-
Globale Verfügbarkeit: Dezentrales Angebot bedeutet keine regionalen Einschränkungen. Hardware ist verfügbar, wenn Sie sie brauchen, verteilt über Jurisdiktionen weltweit.
Für Organisationen, die Kapitalaufwand für GPU-Hardware nicht rechtfertigen können, aber stärkere Datenschutzgarantien als Cloud-Anbieter bieten, ermöglichen dezentrale Anmietungen einen praktischen Mittelweg.
Der Workflow umfasst die Übertragung Ihrer Daten direkt zum Mietknoten über verschlüsselte SSH-Verbindung, das Ausführen Ihres Trainings- oder Inferenzjobs, das Herunterladen der Ergebnisse und das Bereinigen der Remote-Umgebung vor dem Trennen. Unser Guide zum Sichern Ihres Datensatzes auf einem öffentlichen GPU-Knoten behandelt die operativen Sicherheitspraktiken im Detail.
Implementierung einer konformen KI-Strategie
Organisationen, die von ChatGPT-Verboten zur privaten KI-Bereitstellung übergehen, sollten den Übergang systematisch angehen.
Phase 1: Richtlinienentwicklung
Beginnen Sie damit, zu artikulieren, was Ihre KI-Richtlinie tatsächlich verbietet und erlaubt. Viele anfängliche ChatGPT-Verbote waren reaktiv—pauschale Verbote, die schnell implementiert wurden, um unmittelbares Risiko zu stoppen. Eine ausgereifte Richtlinie unterscheidet zwischen:
- Datenkategorien, die niemals von externen KI-Systemen verarbeitet werden dürfen
- Anwendungsfälle, in denen Cloud-KI-Dienste mit entsprechenden Kontrollen akzeptabel sind
- Genehmigte Tools und Plattformen für verschiedene Sensibilitätsstufen
- Genehmigungsprozesse für die Einführung neuer KI-Tools
- Anforderungen zur Vorfallmeldung bei Richtlinienverstößen
Dieses Framework ermöglicht die Fortsetzung der KI-Nutzung, wo angemessen, während sensible Operationen geschützt werden.
Phase 2: Infrastrukturbewertung
Bewerten Sie Ihre Optionen für private KI-Bereitstellung basierend auf organisatorischen Ressourcen und Anforderungen:
-
Bestehende GPU-Ressourcen: Viele Organisationen haben Workstations oder Server mit NVIDIA-GPUs, die für andere Zwecke verwendet werden (Visualisierung, Rendering, wissenschaftliches Rechnen), die KI-Workloads unterstützen könnten.
-
Cloud-Budget und Risikobereitschaft: Wenn Ihr Sicherheitsteam Cloud-Anbieter-Beteiligung mit entsprechenden Kontrollen akzeptiert, bieten private Cloud-GPU-Instanzen einfacheren Betrieb als lokale oder dezentrale Optionen.
-
Datenschutzanforderungen: Wenn Ihr Anwendungsfall Daten umfasst, die unter keinen Umständen Cloud-Anbieter-Infrastruktur berühren können, werden lokale Hardware oder dezentrale Anmietungen notwendig.
-
Umfang und Häufigkeit: Gelegentliche Feinabstimmungsjobs eignen sich für Mietmodelle. Kontinuierlicher Inferenzbetrieb kann Kapitalinvestitionen rechtfertigen.
Phase 3: Modellauswahl und Anpassung
Generische Open-Weights-Modelle bieten einen Ausgangspunkt, aber organisatorischer Wert kommt aus der Anpassung. Feinabstimmung auf Ihre Daten erstellt Modelle, die Ihre Domäne, Ihre Terminologie und Ihre Anforderungen verstehen.
Überlegen Sie, welche Anwendungsfälle den höchsten Wert bieten:
- Dokumentenanalyse: Rechtsverträge, regulatorische Einreichungen, interne Richtlinien
- Code-Unterstützung: Entwicklung innerhalb Ihrer spezifischen Frameworks und Standards
- Kundenkommunikation: Antworten, die Ihre Markenstimme und Produktkenntnisse widerspiegeln
- Internes Wissen: Abfrage von Organisationsdokumentation und institutionellem Wissen
Jeder Anwendungsfall kann ein separates feinabgestimmtes Modell rechtfertigen, oder ein einzelnes Modell, das auf diverse Organisationsdaten trainiert wurde, kann mehrere Zwecke erfüllen.
Phase 4: Operative Integration
Private KI-Bereitstellung erfordert operative Fähigkeiten, die SaaS-Produkte abstrahieren:
-
Modell-Serving-Infrastruktur: Inferenz im großen Maßstab erfordert GPU-Ressourcen, Load Balancing und API-Schnittstellen. Tools wie vLLM, Text Generation Inference und Ollama vereinfachen die Bereitstellung.
-
Zugriffskontrollen: Wer kann das Modell abfragen? Welche Protokollierung erfolgt? Wie auditieren Sie die Nutzung?
-
Update-Verfahren: Wie integrieren Sie neue Trainingsdaten? Wie stellen Sie verbesserte Modellversionen bereit?
-
Incident-Response: Was passiert, wenn ein Modell problematische Ausgaben generiert? Wer überprüft Grenzfälle?
Organisationen, die an SaaS-Einfachheit gewöhnt sind, unterschätzen möglicherweise diesen operativen Overhead. Budgetieren Sie angemessen für laufende Wartung, nicht nur für die anfängliche Bereitstellung.
Fallstudie: Compliance-Architektur für Finanzdienstleistungen
Eine Regionalbank mit 50 Milliarden Dollar Vermögen stand vor einem vertrauten Dilemma. Relationship-Manager wollten KI-Unterstützung beim Verfassen von Kundenkommunikation und der Analyse von Portfoliopositionen. Compliance-Beauftragte erkannten, dass die Übertragung von Kundenfinanzdaten an ChatGPT sowohl gegen regulatorische Anforderungen als auch gegen Treuepflichten verstieß.
Die Lösungsarchitektur illustriert, wie Organisationen beide Seiten zufriedenstellen können.
Datenklassifizierung
Die Bank etablierte drei Stufen von KI-zulässigen Daten:
-
Stufe 1 (Öffentlich): Marketingmaterialien, öffentliche Finanzbildungsinhalte, allgemeine Produktbeschreibungen. Cloud-KI-Dienste erlaubt mit Standard-Nutzungsrichtlinien.
-
Stufe 2 (Intern): Interne Richtlinien, Schulungsmaterialien, Betriebsverfahren. Cloud-KI-Dienste erlaubt mit Unternehmensvereinbarungen und Datenverarbeitungszusätzen.
-
Stufe 3 (Eingeschränkt): Kundendaten, Portfolioinformationen, Transaktionsdetails, strategische Planung. Keine externe KI-Verarbeitung unter keinen Umständen.
Diese Klassifizierung ermöglichte KI-Adoption, wo Risiko akzeptabel war, bei gleichzeitiger Aufrechterhaltung absoluten Schutzes für sensible Kategorien.
Bereitstellung privater Infrastruktur
Für Stufe-3-Anwendungsfälle stellte die Bank ein feinabgestimmtes Llama-Modell auf lokalen GPU-Servern innerhalb ihres bestehenden Rechenzentrums bereit. Das Modell wurde trainiert auf:
- Anonymisierter historischer Kundenkommunikation (mit Kundeneinwilligung)
- Internen Compliance-Richtlinien und regulatorischen Interpretationen
- Produktdokumentation und Investment-Research
- Vom Compliance-Team genehmigten Kommunikationsvorlagen
Das resultierende Modell verstand Bankterminologie, regulatorische Einschränkungen und organisatorische Kommunikationsstandards. Relationship-Manager konnten Kundenbriefe mit KI-Unterstützung verfassen, wissend, dass keine Kundendaten den Sicherheitsperimeter der Bank verließen.
Operative Kontrollen
Jede Modellinteraktion wurde im bestehenden Compliance-Archivsystem der Bank protokolliert. Vorgesetzte konnten KI-unterstützte Kommunikation neben traditioneller Korrespondenz überprüfen. Audit-Trails erfüllten regulatorische Aufzeichnungsanforderungen.
Das Modell selbst operierte innerhalb von Leitplanken, die bestimmte Ausgaben verhinderten—Anlageempfehlungen, Garantiesprache oder Aussagen, die eine Beratung darstellen könnten, die eine spezifische Lizenzierung erfordert. Diese Einschränkungen wurden auf Anwendungsebene implementiert, ohne sich allein auf Modellverhalten zu verlassen.
Gemessene Ergebnisse
Sechs Monate nach der Bereitstellung berichtete die Bank:
- 40% Reduzierung der Zeit für das Verfassen routinemäßiger Kundenkommunikation
- Null Compliance-Vorfälle im Zusammenhang mit KI-Nutzung
- Erfolgreiche regulatorische Prüfung ohne Beanstandungen zur KI-Bereitstellung
- Erhöhte Zufriedenheitswerte der Relationship-Manager
Die Investition in private Infrastruktur—ungefähr 200.000 Dollar einschließlich Hardware, Entwicklung und Integration—generierte Renditen innerhalb des ersten Jahres allein durch Produktivitätsgewinne.
Fallstudie: Gesundheitsforschungsinstitution
Ein großes akademisches medizinisches Zentrum, das klinische Forschung durchführte, sah sich HIPAA-Einschränkungen gegenüber, die jede Cloud-KI-Nutzung mit Patientendaten rechtlich problematisch machten. Forscher wollten KI für Literaturrecherche, Protokollentwicklung und Datenanalyse nutzen.
Der hybride Ansatz
Anstatt zwischen vollständigem Verbot und inakzeptablem Risiko zu wählen, implementierte die Institution eine hybride Architektur:
-
Öffentliche Forschungsaufgaben (Literaturrecherche, Methodenfragen, statistische Ansätze) nutzten Cloud-KI-Dienste mit klaren Richtlinien, die jede Patientendateneingabe verboten.
-
Patientendatenanalyse nutzte lokal bereitgestellte Modelle auf vom Internet isolierten Workstations innerhalb der sicheren Forschungsumgebung. Diese Maschinen hatten keine Internetverbindung. Daten konnten unabhängig vom Benutzerverhalten nicht nach außen gelangen.
Dezentrales Training
Die Institution hatte kein Kapitalbudget für trainingsfähige GPU-Hardware, benötigte aber Modelle, die auf medizinische Literatur und Forschungsprotokolle feinabgestimmt waren. Sie nutzten dezentrale GPU-Anmietungen für Trainingsläufe, wobei nur öffentliche medizinische Literatur und anonymisierte Datensätze ohne HIPAA-Implikationen verwendet wurden.
Der Trainingsworkflow folgte den Sicherheitspraktiken aus unserem Datensatz-Sicherheitsguide:
- Übertragung nur nicht-sensibler Trainingsdaten zu Mietknoten
- Ausführung von Feinabstimmungsjobs
- Download der resultierenden Modellgewichte
- Vollständige Bereinigung der Remote-Umgebungen
- Bereitstellung trainierter Modelle auf isolierter interner Infrastruktur
Dieser Ansatz bot angepasste medizinische KI-Fähigkeiten, ohne geschützte Gesundheitsinformationen externen Systemen auszusetzen.
Regulatorische Validierung
Das IRB der Institution überprüfte die KI-Bereitstellung als Teil von Forschungsprotokoll-Änderungen. Die klare Trennung zwischen öffentlichem Datentraining (extern) und Patientendateninferenz (intern, isoliert) erfüllte die Datenschutzanforderungen. HIPAA-Compliance-Beauftragte genehmigten die Architektur nach Sicherheitsbewertung.

Die strategische Notwendigkeit
Organisationen, die KI-Richtlinien ausschließlich durch eine Risikominimierungslinse betrachten, verpassen das größere Bild. Die Unternehmen, die ChatGPT heute verbieten, geben KI nicht auf. Sie positionieren sich für nachhaltige Vorteile neu.
Wettbewerbsdifferenzierung durch Daten
Die wertvollsten KI-Fähigkeiten entstehen aus proprietären Daten. Ein generisches Sprachmodell, das auf Internettexten trainiert wurde, bietet generische Fähigkeiten, die jedem zur Verfügung stehen. Ein Modell, das auf Ihre Kundeninteraktionen, Ihre Betriebsdaten und Ihr institutionelles Wissen feinabgestimmt ist, bietet einzigartige Fähigkeiten für Ihre Organisation.
Diese Differenzierung erfordert, proprietäre Daten proprietär zu halten. Organisationen, die ihre Wettbewerbsvorteile in Cloud-KI-Dienste einspeisen, tragen zu Modellen bei, die allen Nutzern zugutekommen—einschließlich Wettbewerbern. Organisationen, die Datenkontrolle aufrechterhalten, während sie private KI bereitstellen, akkumulieren Vorteile, die sich im Laufe der Zeit verstärken.
Regulatorische Trajektorie
KI-Regulierung verschärft sich, nicht lockert sich. Der EU AI Act setzt Präzedenzfälle, denen andere Jurisdiktionen folgen werden. US-Behörden einschließlich FTC, SEC und Bankenregulierer entwickeln KI-spezifische Leitlinien. China hat KI-Vorschriften implementiert, die Modelltraining und -bereitstellung betreffen.
Organisationen, die jetzt private KI-Infrastruktur aufbauen, bereiten sich auf regulatorische Umgebungen vor, die die Cloud-KI-Nutzung zunehmend einschränken werden. Die Investition in konforme Architektur wird wertvoller, wenn sich die Compliance-Anforderungen verschärfen.
Lieferkettenüberlegungen
Die Abhängigkeit von einem einzigen KI-Anbieter schafft strategische Verwundbarkeit. OpenAIs Preisgestaltung, Richtlinien und Fähigkeiten ändern sich nach deren Ermessen. Dienstunterbrechungen betreffen alle Kunden gleichzeitig. Richtlinienänderungen können zuvor akzeptable Anwendungsfälle über Nacht verbieten.
Private KI-Bereitstellung eliminiert die Abhängigkeit von einem einzigen Anbieter. Open-Weights-Modelle sind herunterladbar und dauerhaft verfügbar. Mehrere Hardware-Optionen existieren für die Bereitstellung. Die Organisation kontrolliert ihre KI-Lieferkette, anstatt von externen Entscheidungen abzuhängen.
Implementierungs-Roadmap
Für Organisationen, die bereit sind, über ChatGPT-Verbote hinaus zu privater KI-Fähigkeit zu gelangen, empfehlen wir einen phasenweisen Ansatz.
Sofortige Maßnahmen (Woche 1-2)
- Audit der aktuellen KI-Nutzung in der gesamten Organisation
- Klassifizierung von Datentypen nach Sensibilität und regulatorischen Anforderungen
- Dokumentation, welche Anwendungsfälle private Infrastruktur versus akzeptable Cloud-Nutzung erfordern
- Etablierung einer Übergangsrichtlinie, die verbotene und erlaubte Aktivitäten klärt
Kurzfristige Entwicklung (Monat 1-3)
- Bewertung der Infrastrukturoptionen basierend auf Sensibilitätsanforderungen und Budget
- Auswahl erster Anwendungsfälle für private KI-Bereitstellung
- Identifizierung von Trainingsdatenquellen für Modellanpassung
- Etablierung von Sicherheitsprotokollen für externe GPU-Nutzung, falls zutreffend
Mittelfristige Bereitstellung (Monat 3-6)
- Feinabstimmung von Modellen auf Organisationsdaten nach unserem technischen Guide
- Bereitstellung von Inferenzinfrastruktur mit entsprechenden Zugriffskontrollen
- Integration mit bestehenden Compliance- und Auditsystemen
- Schulung der Nutzer zu genehmigten Workflows und Tools
Laufender Betrieb
- Regelmäßige Modell-Updates mit Einbeziehung neuer Trainingsdaten
- Sicherheitsbewertungen der KI-Infrastruktur
- Richtlinien-Updates entsprechend regulatorischer Änderungen
- Fähigkeitserweiterung auf zusätzliche Anwendungsfälle
Fazit
Die Unternehmensverbote von ChatGPT spiegeln rationales Risikomanagement wider, nicht Technophobie. Als Samsung das Tool verbot, nachdem entdeckt wurde, dass proprietäre Halbleiterdesigns hochgeladen worden waren, trafen sie die richtige Entscheidung. Als JPMorgan den Zugang proaktiv einschränkte, demonstrierten sie angemessenes regulatorisches Bewusstsein. Wenn Gesundheitssysteme den Zugang auf Firewall-Ebene blockieren, schützen sie die Patientenprivatsphäre wie gesetzlich vorgeschrieben.
Aber Verbot ist keine Strategie. Organisationen, die bei “Nein” stehenbleiben, verzichten auf Produktivitätsvorteile, die ihre Wettbewerber erfassen werden. Die Unternehmen, die gedeihen werden, sind diejenigen, die erkennen, dass ein dritter Weg existiert.
Open-Weights-Modelle, die auf privater Infrastruktur laufen, bieten KI-Fähigkeit ohne Datenexposition. Die Modelle sind jetzt verfügbar. Die Infrastruktur ist zugänglich. Die technischen Workflows sind dokumentiert. Die einzige Barriere ist der organisatorische Wille zur Umsetzung.
Ihre Wettbewerber, die Modelle auf ihren proprietären Daten feinabstimmen—Systeme trainieren, die ihre Kunden, ihre Produkte und ihre Operationen verstehen—bauen Vorteile auf, die Sie nicht replizieren können, indem Sie einen generischen Dienst abonnieren. Während Sie über Richtlinien debattieren, stellen sie Fähigkeiten bereit.
Die Infrastrukturentscheidungen, die Sie heute treffen, bestimmen, ob KI zu Ihrem Wettbewerbsvorteil wird oder zum Vorteil Ihrer Wettbewerber über Sie. Cloud-KI-Dienste verwandeln Ihre Daten in geteilte Ressourcen. Private KI-Bereitstellung verwandelt Ihre Daten in einzigartige Fähigkeit.
Die Wahl ist nicht, ob KI genutzt werden soll. Die Wahl ist, ob sie kontrolliert werden soll.
Verwandte Ressourcen
Dieser Artikel behandelt den strategischen und regulatorischen Kontext für Unternehmens-KI-Entscheidungen. Die folgenden Ressourcen bieten technische Implementierungsanleitungen:
Kern-Implementierungsguide
- Der ultimative Leitfaden für privates LLM-Feintuning auf dezentralen GPUs — Vollständiger technischer Workflow für das Training benutzerdefinierter Modelle
Sicherheit und Betrieb
- So sichern Sie Ihren Datensatz auf einem öffentlichen GPU-Knoten — Operative Sicherheitspraktiken für dezentrales Computing
- So mieten Sie eine GPU ohne KYC — Anonyme Miet-Workflows für datenschutzsensible Bereitstellungen
Plattform und Wirtschaftlichkeit
- GPU-Mietpreis-Vergleich 2026 — Kostenanalyse über Bereitstellungsoptionen
- Smart Contract Escrow erklärt — Wie dezentrale Zahlungen beide Parteien schützen
- Stablecoins sind der klügste Weg, GPU-Miete zu bezahlen — Zahlungsmechanismen für dezentrale Infrastruktur
Technische Vergleiche
- Ollama vs vLLM vs TGI: Benchmarking von Inferenzgeschwindigkeiten auf Consumer-GPUs — Inferenzserver-Auswahl für Bereitstellung
- RunPod vs Vast.ai Vergleich — Marktplatzbewertung für GPU-Anmietungen