
El memorando no satisface a nadie pero lo cambia todo.
Cuando la división de semiconductores de Samsung descubrió que los ingenieros habían subido diseños de chips propietarios a ChatGPT, la respuesta fue inmediata y absoluta. Una prohibición a nivel de toda la empresa. Sin excepciones. Sin proceso de apelación. La herramienta que se había convertido en sinónimo de productividad de IA ahora estaba prohibida en todas las redes corporativas.
Samsung no estaba sola. En cuestión de meses, surgieron anuncios similares de JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank y docenas de otras empresas. Bufetes de abogados que asesoran a empresas Fortune 500 prohibieron a los asociados usar el servicio. Los sistemas de salud bloquearon el acceso a nivel de firewall. Las agencias gubernamentales emitieron orientaciones que efectivamente terminaron con cualquier ambigüedad sobre el uso aceptable.
El patrón reveló algo que los entusiastas de la tecnología habían pasado por alto en su entusiasmo por las capacidades de la IA: la adopción empresarial opera bajo restricciones que la adopción del consumidor no tiene.
Este artículo examina por qué las políticas corporativas de IA se están endureciendo, qué riesgos específicos impulsan estas decisiones y cómo las organizaciones pueden mantener capacidades de IA sin aceptar una exposición de datos inaceptable. El camino a seguir no requiere abandonar la IA. Requiere entender que la infraestructura importa tanto como la inteligencia.

Los incidentes que lo cambiaron todo
Las prohibiciones corporativas de IA no surgieron de evaluaciones de riesgo teóricas. Siguieron a incidentes reales donde información confidencial escapó del control organizacional.
La brecha de semiconductores de Samsung
A principios de 2023, empleados de Samsung Electronics usaron ChatGPT para depurar código fuente y optimizar procesos de fabricación de semiconductores. Los ingenieros pegaron código propietario directamente en la interfaz de chat. Otros subieron notas de reuniones que contenían discusiones de planificación estratégica. En tres semanas desde que se permitió ChatGPT para uso interno, el equipo de seguridad de la información de Samsung identificó múltiples instancias de transmisión de datos confidenciales a servidores de OpenAI.
La industria de semiconductores opera con márgenes medidos en nanómetros y ventajas competitivas medidas en meses. La posibilidad de que los procesos de fabricación de Samsung ahora residieran en el corpus de entrenamiento de OpenAI—potencialmente accesibles para competidores usando el mismo servicio—era inaceptable. Samsung implementó una prohibición completa y comenzó a desarrollar herramientas de IA internas que nunca transmitirían datos externamente.
Respuesta de la industria de servicios financieros
JPMorgan Chase restringió el acceso a ChatGPT antes de cualquier incidente publicado, reconociendo las implicaciones regulatorias de manera proactiva. Cuando los empleados bancarios analizan carteras de clientes, discuten estrategias de fusión o evalúan riesgos crediticios, manejan información sujeta a regulaciones de la SEC, leyes de secreto bancario y deberes fiduciarios. Transmitir dicha información a un servicio de IA de terceros—independientemente de las políticas de privacidad declaradas de ese servicio—crea exposición de cumplimiento que ningún asesor legal general aceptaría.
Goldman Sachs, Citigroup, Bank of America y Deutsche Bank siguieron con restricciones similares. La respuesta coordinada de la industria de servicios financieros reflejó no paranoia sino comprensión profesional de la responsabilidad regulatoria. Una brecha de datos originada por el uso de ChatGPT por parte de empleados requeriría divulgación, desencadenaría investigación regulatoria y potencialmente resultaría en acción de cumplimiento.
Implicaciones para la industria legal
La American Bar Association no ha emitido una prohibición general sobre herramientas de IA, pero el efecto práctico de los requisitos del privilegio abogado-cliente se aproxima a una. Cuando un abogado discute asuntos de clientes con ChatGPT, la conversación puede renunciar a la protección del privilegio. La información divulgada a terceros—incluso sistemas de IA—puede perder la confidencialidad que hace que el asesoramiento legal esté protegido.
Grandes bufetes de abogados incluyendo Davis Polk, Cravath y Sullivan & Cromwell implementaron restricciones que van desde prohibiciones completas hasta políticas de solo uso aprobado que requieren autorización de socios. La respuesta de la profesión legal demostró que los riesgos de la IA se extienden más allá de la seguridad de datos hacia cuestiones fundamentales de responsabilidad profesional.
La realidad técnica del manejo de datos de IA en la nube
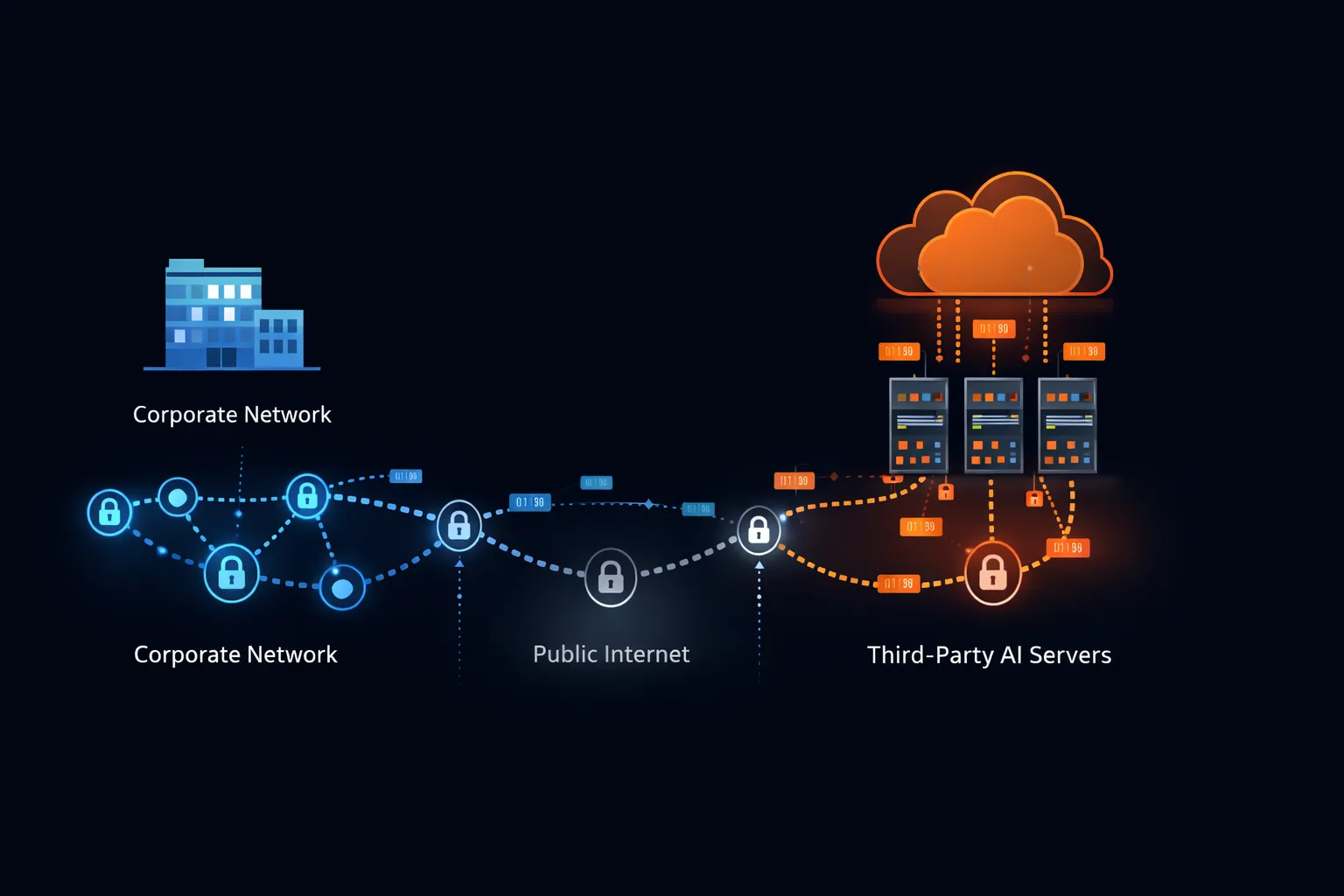
Entender por qué las empresas prohíben ChatGPT requiere examinar qué sucede realmente cuando envía un mensaje a un servicio de IA en la nube.
Ruta de transmisión de datos
Cuando escribe un prompt en ChatGPT, su texto viaja desde su dispositivo a través de su red corporativa, a través de internet público, hasta la infraestructura de OpenAI. OpenAI opera principalmente en Microsoft Azure, lo que significa que sus datos transitan la red de Microsoft y residen en servidores gestionados por Microsoft.
Esta transmisión ocurre independientemente de la sensibilidad del contenido. El sistema no puede distinguir entre una solicitud para escribir un poema y una solicitud para analizar términos de fusión confidenciales. Cada carácter que ingresa sigue el mismo camino al mismo destino.
Políticas de retención de datos
Las políticas de uso de datos de OpenAI han evolucionado con el tiempo, pero ciertos fundamentos permanecen consistentes. Las entradas de usuarios se registran. Las conversaciones se almacenan. La duración y el propósito del almacenamiento dependen de su nivel de suscripción y acuerdos específicos.
Para suscriptores del nivel gratuito y Plus, OpenAI se reserva explícitamente el derecho de usar las entradas para mejora del modelo. Sus prompts se convierten en datos de entrenamiento. El código confidencial que pegó para depurar un problema puede influir en cómo el modelo responde a futuros usuarios—potencialmente incluyendo a sus competidores.
Los usuarios de API y suscriptores Enterprise pueden optar por no contribuir a los datos de entrenamiento, pero sus entradas aún se procesan en la infraestructura de OpenAI. Los datos aún existen en servidores que usted no controla, gestionados por empleados que usted no ha verificado, sujetos a procesos legales que usted no puede influir.
El problema del tercero
Las arquitecturas de seguridad empresarial distinguen entre sistemas de primera parte (infraestructura que usted posee y opera), sistemas de segunda parte (proveedores con relaciones contractuales directas y controles de seguridad auditados), y sistemas de tercera parte (servicios a los que se accede sin integración de seguridad detallada).
ChatGPT, para la mayoría de los usuarios, opera como un tercero no auditado. A menos que su organización haya negociado un acuerdo empresarial específico con anexos de seguridad, derechos de pruebas de penetración y certificaciones de cumplimiento mapeadas a sus requisitos, ChatGPT se encuentra fuera de su perímetro de seguridad con acceso a cualquier dato que los empleados elijan compartir.
Esta realidad arquitectónica explica por qué los equipos de seguridad tratan a ChatGPT de manera diferente a Microsoft Office o Salesforce. Esos sistemas, a pesar de estar basados en la nube, operan bajo acuerdos empresariales con controles de seguridad definidos, derechos de auditoría y términos de responsabilidad. ChatGPT, para un usuario con una suscripción de $20/mes, no ofrece ninguna de esas protecciones.
Marcos regulatorios que impulsan la cautela empresarial
Las políticas corporativas de IA no existen en el vacío. Responden a requisitos legales que anteceden a ChatGPT y lo sobrevivirán.
GDPR y protección de datos europea
El Reglamento General de Protección de Datos impone requisitos estrictos sobre el procesamiento de datos personales de residentes de la UE. Cuando un empleado pega información de clientes en ChatGPT, inicia una transferencia de datos a un procesador con sede en EE.UU. Esta transferencia requiere base legal—ya sea decisiones de adecuación, cláusulas contractuales estándar o reglas corporativas vinculantes.
Los acuerdos de procesamiento de datos de OpenAI pueden satisfacer los requisitos del GDPR para algunos casos de uso, pero la mayoría de los empleados que usan el producto de consumo no tienen dicho acuerdo vigente. Simplemente están transmitiendo datos personales a una corporación extranjera sin autorización.
Los reguladores italianos prohibieron temporalmente ChatGPT en 2023 específicamente por preocupaciones del GDPR. Aunque el servicio se reanudó después de que OpenAI hiciera ajustes de cumplimiento, el incidente demostró la disposición regulatoria para actuar. Las empresas europeas enfrentan responsabilidad directa por acciones de empleados que violan el GDPR, creando fuertes incentivos para políticas restrictivas.
HIPAA y datos de salud
La Ley de Portabilidad y Responsabilidad del Seguro de Salud prohíbe la divulgación de información de salud protegida (PHI) excepto bajo circunstancias autorizadas específicas. Un trabajador de salud que discute casos de pacientes con ChatGPT divulga PHI a un receptor no autorizado.
No existe un acuerdo de asociado comercial entre las organizaciones de salud típicas y OpenAI. Ninguna auditoría de seguridad ha verificado el cumplimiento de ChatGPT con las salvaguardas técnicas de HIPAA. Ningún marco legal autoriza la divulgación.
Las organizaciones de salud que descubren que los empleados han compartido PHI a través de ChatGPT enfrentan requisitos de notificación de brechas, investigación potencial de OCR y sanciones que alcanzan $1.5 millones por categoría de violación por año. Estas consecuencias explican por qué los sistemas hospitalarios bloquean ChatGPT a nivel de red en lugar de depender del cumplimiento de políticas.
Regulaciones financieras
Los bancos, corredores de bolsa y asesores de inversiones operan bajo regulaciones de la SEC, FINRA, OCC y la Reserva Federal que exigen mantenimiento de registros y supervisión de comunicaciones comerciales. Cuando un analista usa ChatGPT para redactar correspondencia con clientes, esa conversación debería capturarse en archivos de cumplimiento.
ChatGPT no proporciona integración con sistemas de archivo empresarial. Ninguna herramienta de supervisión marca el uso potencialmente problemático. La conversación existe solo en los servidores de OpenAI y el dispositivo del empleado—ninguno de los cuales satisface los requisitos regulatorios de mantenimiento de registros.
Más allá del mantenimiento de registros, los reguladores financieros expresan preocupación por el asesoramiento de inversión generado por IA, la participación de IA en decisiones de crédito y el análisis de IA que podría constituir manipulación del mercado. El panorama regulatorio permanece incierto, y los oficiales de cumplimiento responden a la incertidumbre restringiendo el uso en lugar de permitirlo mientras se espera claridad.
Regulación emergente específica de IA
La Ley de IA de la UE, que se espera entre en vigor progresivamente durante 2025 y 2026, impondrá requisitos adicionales sobre la implementación de sistemas de IA. Las aplicaciones de IA de alto riesgo—incluyendo aquellas que afectan el empleo, el crédito y la educación—requieren evaluaciones de conformidad, documentación y supervisión humana.
Las organizaciones que usan ChatGPT en estos contextos pueden encontrarse operando sistemas de IA no conformes una vez que las regulaciones entren en vigor. Las empresas proactivas están restringiendo el uso ahora en lugar de enfrentar remediación de cumplimiento más tarde.
Propiedad intelectual: El riesgo que ningún contrato resuelve
El cumplimiento regulatorio representa una categoría de preocupación. La protección de la propiedad intelectual representa otra—y para muchas empresas, la más consecuente.
Secretos comerciales y confidencialidad
La protección de secretos comerciales bajo la Ley de Defensa de Secretos Comerciales y equivalentes estatales requiere que la información permanezca confidencial a través de medidas de protección razonables. Cuando un empleado pega algoritmos propietarios, procesos de fabricación o planes estratégicos en ChatGPT, las medidas de protección de la organización han fallado.
Los tribunales que evalúan reclamos de secretos comerciales examinan si la parte reclamante tomó pasos razonables para mantener el secreto. Permitir que los empleados compartan información confidencial con servicios de IA de terceros socava este requisito. Incluso si la información nunca se filtra de los sistemas de OpenAI, el acto de divulgación en sí mismo puede comprometer la protección legal.
Esta preocupación se extiende más allá del litigio hipotético. Las empresas regularmente afirman reclamos de secretos comerciales contra empleados que se van y competidores. Si el descubrimiento revela que la información “secreta” fue previamente compartida con ChatGPT—accesible a millones de usuarios a través del potencial entrenamiento del modelo—el reclamo se debilita sustancialmente.
Código fuente y activos técnicos
Las empresas de software enfrentan una exposición particular. Los desarrolladores naturalmente quieren usar herramientas de IA para depurar código, generar plantillas y acelerar el desarrollo. Pero el código fuente representa el activo central de un negocio de software. Una vez transmitido a ChatGPT, ese código existe fuera del control organizacional.
La preocupación sobre los datos de entrenamiento no es teórica. Los modelos de lenguaje grandes aprenden de sus entradas. Mientras OpenAI afirma que los clientes Enterprise y API pueden optar por no contribuir al entrenamiento, el producto de consumo no lleva tal garantía. El código compartido por un desarrollador puede influir en las completaciones mostradas a otro—potencialmente en una empresa competidora.
La advertencia interna de Amazon a los empleados citó específicamente el riesgo de que las respuestas de ChatGPT pudieran parecerse a información confidencial de Amazon, sugiriendo que datos similares ya habían sido incorporados al modelo. Si esto representaba código real de Amazon en datos de entrenamiento o simplemente patrones similares permanece incierto. La ambigüedad misma impulsó la política restrictiva.
Información de clientes y consumidores
Las firmas de servicios profesionales—consultores, contadores, abogados, arquitectos—trabajan con información de clientes que pertenece a esos clientes, no al proveedor del servicio. Compartir datos de clientes con ChatGPT puede violar cartas de compromiso, acuerdos de confidencialidad y reglas de ética profesional.
Un consultor que sube las proyecciones financieras de un cliente a ChatGPT para análisis ha compartido la información confidencial de ese cliente con un tercero. La firma del consultor puede enfrentar reclamos por incumplimiento de contrato, disciplina profesional y pérdida de relaciones con clientes si se descubre.
Estas preocupaciones se aplican igualmente a cualquier negocio que maneje datos de clientes. Un representante de ventas que pega correspondencia de clientes en ChatGPT para redactar una respuesta ha transmitido comunicaciones de clientes a OpenAI. Dependiendo de la industria y los acuerdos aplicables, esto puede violar compromisos de manejo de datos de clientes.

La insuficiencia de los acuerdos empresariales de IA
OpenAI ofrece ChatGPT Enterprise específicamente para abordar las preocupaciones corporativas. Microsoft proporciona Azure OpenAI Service con características de seguridad empresarial. Estos productos mejoran las ofertas de consumo pero no eliminan las preocupaciones fundamentales para casos de uso de alta sensibilidad.
Lo que proporcionan los acuerdos empresariales
ChatGPT Enterprise incluye varias mejoras significativas:
- Los datos no se usan para entrenamiento del modelo
- Certificación de cumplimiento SOC 2 Tipo 2
- Cifrado de datos en reposo y en tránsito
- Integración SSO y controles administrativos
- Controles de retención de datos
Estas características satisfacen los requisitos para muchos casos de uso corporativo. Un equipo de marketing que redacta textos de campaña enfrenta un riesgo mínimo. Un departamento de servicio al cliente que genera plantillas de respuesta opera dentro de parámetros aceptables.
Lo que los acuerdos empresariales no pueden proporcionar
Para industrias reguladas y propiedad intelectual sensible, los acuerdos empresariales se quedan cortos de maneras fundamentales.
Primero, los datos aún se procesan en infraestructura que usted no controla. Su información reside en servidores de OpenAI, gestionados por empleados de OpenAI, sujetos a las prácticas de seguridad de OpenAI. Usted confía en su implementación. Confía en su verificación de personal. Confía en su respuesta a incidentes. Esta confianza puede estar justificada, pero es confianza de todos modos—no verificación.
Segundo, los datos permanecen sujetos a proceso legal. Una citación judicial servida a OpenAI podría obligar a la divulgación de sus conversaciones. Una investigación gubernamental sobre otro cliente podría potencialmente exponer infraestructura compartida. Las cartas de seguridad nacional y las órdenes de la corte FISA operan bajo requisitos de secreto que impedirían a OpenAI notificarle del acceso.
Tercero, la superficie de ataque incluye toda la organización de OpenAI. Su perímetro de seguridad ya no termina en el límite de su red. Cada empleado de OpenAI con acceso al sistema, cada proveedor con acceso a la infraestructura, cada vulnerabilidad de seguridad en los sistemas de OpenAI se convierte en parte de su perfil de riesgo.
Cuarto, la salida y la portabilidad permanecen restringidas. Su historial de conversaciones, comportamientos ajustados finamente y conocimiento organizacional acumulado en ChatGPT pertenecen a interacciones con el sistema de OpenAI. La migración a una alternativa requiere reconstruir desde cero.
Para una empresa farmacéutica que desarrolla compuestos novedosos, un contratista de defensa que maneja investigación casi clasificada, o una institución financiera con algoritmos de trading que representan miles de millones en valor potencial, estas limitaciones importan. Los acuerdos empresariales reducen el riesgo. No lo eliminan.
La alternativa de pesos abiertos
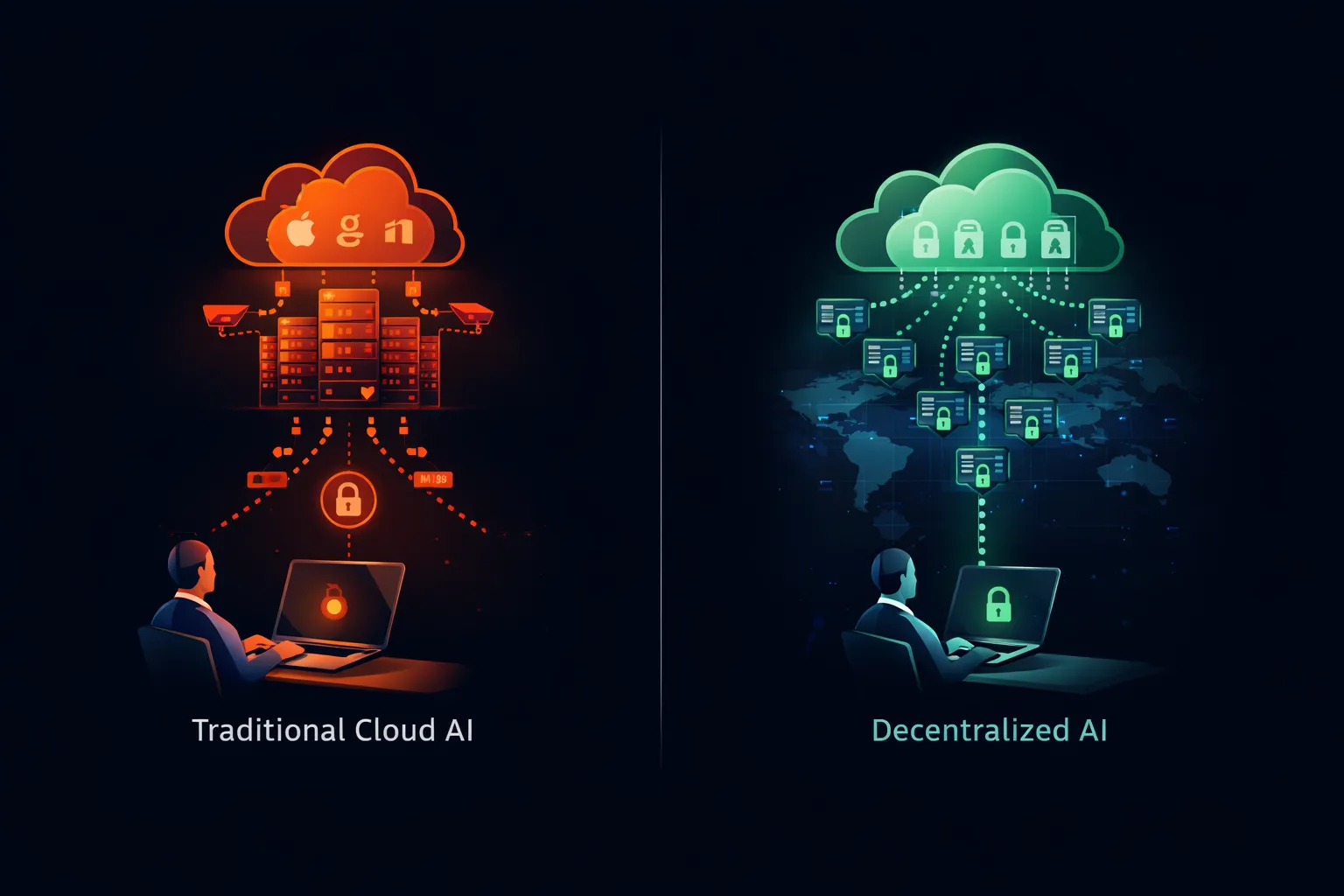
Las restricciones que impulsan las prohibiciones corporativas de ChatGPT no se aplican a la IA en general. Se aplican específicamente a los servicios de IA en la nube donde los datos abandonan el control organizacional. Una arquitectura diferente elimina estas preocupaciones por completo.
Lo que proporcionan los modelos de pesos abiertos
Los modelos de pesos abiertos—Llama de Meta, Mistral de Mistral AI, Qwen de Alibaba y docenas más—proporcionan archivos de modelo descargables que se ejecutan en cualquier hardware compatible. Los pesos del modelo son públicos. El código de inferencia es de código abierto. Puede ejecutar todo el sistema en infraestructura que usted posee y opera.
Cuando ejecuta Llama en su propio servidor, sus prompts nunca abandonan su red. Ningún tercero recibe sus datos. Ningún servicio en la nube registra sus consultas. Ningún pipeline de entrenamiento incorpora sus entradas. El modelo se ejecuta localmente, procesa localmente y no almacena nada más allá de lo que usted configure explícitamente.
Esta arquitectura satisface cada preocupación que impulsa las prohibiciones de ChatGPT:
-
Cumplimiento regulatorio: Los datos permanecen dentro de su perímetro de seguridad, sujetos a sus controles, gobernados por sus políticas. Las transferencias de datos del GDPR no ocurren porque los datos no se transfieren. Las preocupaciones de HIPAA se disuelven porque no hay divulgación a partes no autorizadas.
-
Protección de propiedad intelectual: Los secretos comerciales permanecen secretos. El código fuente nunca abandona sus sistemas. Se mantiene la confidencialidad del cliente porque ningún tercero recibe información del cliente.
-
Control de seguridad: Su superficie de ataque sigue siendo la suya. Usted verifica sus prácticas de seguridad. Verifica a su personal. Controla su respuesta a incidentes. Las vulnerabilidades de ninguna organización externa afectan sus datos.
-
Auditoría y cumplimiento: Cada consulta, cada respuesta, cada interacción con el modelo puede registrarse según sus requisitos. El mantenimiento de registros regulatorios se integra con sus sistemas de archivo existentes.
Comparación de capacidades
La pregunta natural es si los modelos de pesos abiertos igualan las capacidades de ChatGPT. La respuesta honesta: depende del caso de uso.
Para consultas de conocimiento general, el entrenamiento de ChatGPT en datos a escala de internet proporciona una amplitud que los modelos abiertos más pequeños no pueden igualar. Las capacidades de razonamiento de GPT-4 en problemas complejos superan lo que logra Llama-3-8B.
Pero los casos de uso empresarial rara vez requieren conocimiento a escala de internet. Un equipo legal que analiza contratos necesita comprensión de documentos y generación de lenguaje preciso—capacidades donde los modelos abiertos ajustados finamente sobresalen. Un equipo de desarrollo que depura código necesita reconocimiento de patrones dentro de bases de código específicas—una tarea donde el entrenamiento personalizado supera dramáticamente a los modelos genéricos.
La perspicacia crítica es que el ajuste fino transforma modelos genéricos en especialistas de dominio. Un modelo Llama-3-8B ajustado finamente en los documentos de su organización, estándares de codificación y patrones de comunicación superará a GPT-4 para sus tareas específicas mientras mantiene el aislamiento completo de datos.
Nuestra guía pilar sobre ajuste fino privado de LLM en GPUs descentralizadas proporciona el flujo de trabajo técnico completo para este proceso.
Opciones de infraestructura para implementación de IA privada
Ejecutar modelos de pesos abiertos requiere cómputo GPU. Las organizaciones tienen varias opciones para adquirir esta capacidad.
Hardware local
Comprar GPUs NVIDIA para centros de datos internos proporciona el máximo control. El hardware se encuentra en sus instalaciones, gestionado por su personal, conectado a su red. Ninguna parte externa tiene ningún acceso.
El desafío es el gasto de capital y el tiempo de entrega. Una GPU NVIDIA H100 cuesta aproximadamente $30,000. Un clúster significativo para entrenamiento requiere múltiples unidades. Los plazos de adquisición se extienden a meses. El mantenimiento continuo requiere experiencia especializada.
Para grandes empresas con operaciones de centro de datos existentes, la infraestructura de IA local representa una extensión natural. Para organizaciones más pequeñas o aquellas sin experiencia en GPU, las barreras son sustanciales.
Instancias de nube privada
AWS, GCP y Azure ofrecen instancias GPU que proporcionan más control que los productos SaaS de IA. Usted configura el entorno. Controla el acceso. Sus datos se procesan en instancias dedicadas en lugar de servicios compartidos.
Este enfoque mejora la arquitectura de ChatGPT pero retiene la participación del proveedor de nube. Sus datos aún residen en infraestructura que usted no controla físicamente. Los empleados del proveedor de nube con acceso suficiente podrían teóricamente acceder a sus sistemas. Los procesos legales servidos al proveedor de nube podrían alcanzar sus datos.
Además, las instancias GPU de nube privada conllevan costos significativos. Las instancias AWS p4d.24xlarge (8x A100 GPUs) cuestan aproximadamente $32 por hora. Las ejecuciones de entrenamiento extendidas o los servicios de inferencia continuos generan gastos mensuales sustanciales. La disponibilidad está restringida—las instancias GPU frecuentemente muestran listas de espera o disponibilidad regional limitada.
Alquileres de GPU descentralizados
Una tercera opción evita tanto el gasto de capital como la participación del proveedor de nube. Los mercados de GPU descentralizados conectan a los usuarios directamente con propietarios de hardware. Usted alquila capacidad de cómputo peer-to-peer, pagando con criptomoneda, sin verificación de identidad ni intermediación del proveedor de nube.
Este modelo proporciona varias ventajas para organizaciones conscientes de la privacidad:
-
Sin requisitos KYC: Conecta una billetera y alquila hardware. Sin cuentas corporativas. Sin proceso de ventas empresariales. Sin documentación de identidad que vincule su organización a actividades específicas de IA.
-
Sin participación del proveedor de nube: Sus datos se procesan en hardware propiedad de individuos, no de corporaciones con departamentos legales, contratos gubernamentales y relaciones con las fuerzas del orden.
-
Eficiencia de costos: Los alquileres de RTX 4090 cuestan $0.40 a $0.60 por hora, aproximadamente una décima parte del costo de instancias de nube comparables. Nuestra comparación de precios de alquiler de GPU detalla la economía.
-
Disponibilidad global: El suministro descentralizado significa sin restricciones regionales. El hardware está disponible cuando lo necesita, distribuido en jurisdicciones de todo el mundo.
Para organizaciones que no pueden justificar el gasto de capital en hardware GPU pero requieren garantías de privacidad más fuertes de las que ofrecen los proveedores de nube, los alquileres descentralizados proporcionan un camino intermedio práctico.
El flujo de trabajo implica transferir sus datos directamente al nodo de alquiler a través de conexión SSH cifrada, ejecutar su trabajo de entrenamiento o inferencia, descargar resultados y sanear el entorno remoto antes de desconectar. Nuestra guía sobre cómo asegurar su conjunto de datos en un nodo GPU público cubre las prácticas de seguridad operativa en detalle.
Implementando una estrategia de IA compatible
Las organizaciones que pasan de prohibiciones de ChatGPT a implementación de IA privada deberían abordar la transición sistemáticamente.
Fase 1: Desarrollo de políticas
Comience articulando qué prohíbe y permite realmente su política de IA. Muchas prohibiciones iniciales de ChatGPT fueron reactivas—prohibiciones generales implementadas rápidamente para detener el riesgo inmediato. Una política madura distingue entre:
- Categorías de datos que nunca pueden ser procesadas por sistemas de IA externos
- Casos de uso donde los servicios de IA en la nube son aceptables con controles apropiados
- Herramientas y plataformas aprobadas para diferentes niveles de sensibilidad
- Procesos de aprobación para la adopción de nuevas herramientas de IA
- Requisitos de reporte de incidentes para violaciones de políticas
Este marco permite que el uso de IA continúe donde sea apropiado mientras protege las operaciones sensibles.
Fase 2: Evaluación de infraestructura
Evalúe sus opciones para implementación de IA privada basándose en los recursos y requisitos organizacionales:
-
Recursos GPU existentes: Muchas organizaciones tienen estaciones de trabajo o servidores con GPUs NVIDIA usadas para otros propósitos (visualización, renderizado, computación científica) que podrían soportar cargas de trabajo de IA.
-
Presupuesto de nube y tolerancia al riesgo: Si su equipo de seguridad acepta la participación del proveedor de nube con controles apropiados, las instancias GPU de nube privada ofrecen operaciones más simples que las opciones locales o descentralizadas.
-
Requisitos de privacidad: Si su caso de uso involucra datos que no pueden tocar la infraestructura del proveedor de nube bajo ninguna circunstancia, el hardware local o los alquileres descentralizados se vuelven necesarios.
-
Escala y frecuencia: Los trabajos de ajuste fino ocasionales se adaptan a los modelos de alquiler. El servicio de inferencia continuo puede justificar la inversión de capital.
Fase 3: Selección y personalización del modelo
Los modelos de pesos abiertos genéricos proporcionan un punto de partida, pero el valor organizacional viene de la personalización. El ajuste fino en sus datos crea modelos que entienden su dominio, su terminología y sus requisitos.
Considere qué casos de uso ofrecen el mayor valor:
- Análisis de documentos: Contratos legales, presentaciones regulatorias, políticas internas
- Asistencia de código: Desarrollo dentro de sus marcos y estándares específicos
- Comunicación con clientes: Respuestas que reflejan la voz de su marca y conocimiento del producto
- Conocimiento interno: Consulta de documentación organizacional y conocimiento institucional
Cada caso de uso puede justificar un modelo ajustado finamente separado, o un solo modelo entrenado en datos organizacionales diversos puede servir múltiples propósitos.
Fase 4: Integración operativa
La implementación de IA privada requiere capacidades operativas que los productos SaaS abstraen:
-
Infraestructura de servicio del modelo: Ejecutar inferencia a escala requiere recursos GPU, balanceo de carga e interfaces API. Herramientas como vLLM, Text Generation Inference y Ollama simplifican la implementación.
-
Controles de acceso: ¿Quién puede consultar el modelo? ¿Qué registro ocurre? ¿Cómo audita el uso?
-
Procedimientos de actualización: ¿Cómo incorpora nuevos datos de entrenamiento? ¿Cómo implementa versiones mejoradas del modelo?
-
Respuesta a incidentes: ¿Qué sucede si un modelo genera salidas problemáticas? ¿Quién revisa los casos límite?
Las organizaciones acostumbradas a la simplicidad de SaaS pueden subestimar esta sobrecarga operativa. Presupueste apropiadamente para mantenimiento continuo, no solo para la implementación inicial.
Caso de estudio: Arquitectura de cumplimiento de servicios financieros
Un banco regional con $50 mil millones en activos enfrentó un dilema familiar. Los gerentes de relaciones querían asistencia de IA para redactar comunicaciones con clientes y analizar posiciones de cartera. Los oficiales de cumplimiento reconocieron que transmitir datos financieros de clientes a ChatGPT violaba tanto los requisitos regulatorios como los deberes fiduciarios.
La arquitectura de solución ilustra cómo las organizaciones pueden satisfacer a ambas partes.
Clasificación de datos
El banco estableció tres niveles de datos permitidos para IA:
-
Nivel 1 (Público): Materiales de marketing, contenido de educación financiera pública, descripciones generales de productos. Servicios de IA en la nube permitidos con pautas de uso aceptable estándar.
-
Nivel 2 (Interno): Políticas internas, materiales de capacitación, procedimientos operativos. Servicios de IA en la nube permitidos con acuerdos empresariales y anexos de manejo de datos.
-
Nivel 3 (Restringido): Datos de clientes, información de cartera, detalles de transacciones, planificación estratégica. Sin procesamiento de IA externo bajo ninguna circunstancia.
Esta clasificación permitió la adopción de IA donde el riesgo era aceptable mientras mantenía protección absoluta para categorías sensibles.
Implementación de infraestructura privada
Para casos de uso de Nivel 3, el banco implementó un modelo Llama ajustado finamente en servidores GPU locales dentro de su centro de datos existente. El modelo fue entrenado en:
- Comunicaciones históricas de clientes anonimizadas (con consentimiento del cliente)
- Pautas de cumplimiento interno e interpretaciones regulatorias
- Documentación de productos e investigación de inversiones
- Plantillas de comunicación aprobadas por cumplimiento
El modelo resultante entendía la terminología bancaria, las restricciones regulatorias y los estándares de comunicación organizacional. Los gerentes de relaciones podían redactar cartas a clientes con asistencia de IA, sabiendo que ningún dato de cliente abandonaba el perímetro de seguridad del banco.
Controles operativos
Cada interacción con el modelo se registró en el sistema de archivo de cumplimiento existente del banco. Los supervisores podían revisar las comunicaciones asistidas por IA junto con la correspondencia tradicional. Las pistas de auditoría satisfacían los requisitos regulatorios de mantenimiento de registros.
El modelo mismo operaba dentro de barandillas que prevenían ciertas salidas—recomendaciones de inversión, lenguaje de garantía o declaraciones que pudieran constituir asesoramiento que requiere licencia específica. Estas restricciones se implementaron en la capa de aplicación, sin depender solo del comportamiento del modelo.
Resultados medidos
Seis meses después de la implementación, el banco reportó:
- 40% de reducción en el tiempo dedicado a redactar comunicaciones rutinarias con clientes
- Cero incidentes de cumplimiento relacionados con el uso de IA
- Examen regulatorio exitoso sin hallazgos relacionados con la implementación de IA
- Aumento en las puntuaciones de satisfacción de los gerentes de relaciones
La inversión en infraestructura privada—aproximadamente $200,000 incluyendo hardware, desarrollo e integración—generó retornos dentro del primer año solo a través de ganancias de productividad.
Caso de estudio: Institución de investigación en salud
Un importante centro médico académico que realiza investigación clínica enfrentó restricciones de HIPAA que hacían cualquier uso de IA en la nube con datos de pacientes legalmente problemático. Los investigadores querían usar IA para revisión de literatura, desarrollo de protocolos y análisis de datos.
El enfoque híbrido
En lugar de elegir entre prohibición completa y riesgo inaceptable, la institución implementó una arquitectura híbrida:
-
Tareas de investigación pública (revisión de literatura, preguntas de metodología, enfoques estadísticos) usaron servicios de IA en la nube con políticas claras que prohibían cualquier entrada de datos de pacientes.
-
Análisis de datos de pacientes usó modelos implementados localmente en estaciones de trabajo aisladas de internet dentro del entorno de investigación seguro. Estas máquinas no tenían conectividad a internet. Los datos no podían salir independientemente del comportamiento del usuario.
Entrenamiento descentralizado
La institución carecía de presupuesto de capital para hardware GPU capaz de entrenar pero necesitaba modelos ajustados finamente en literatura médica y protocolos de investigación. Utilizaron alquileres de GPU descentralizados para ejecuciones de entrenamiento usando solo literatura médica pública y conjuntos de datos desidentificados sin implicaciones de HIPAA.
El flujo de trabajo de entrenamiento siguió las prácticas de seguridad descritas en nuestra guía de seguridad de conjuntos de datos:
- Transferir solo datos de entrenamiento no sensibles a nodos de alquiler
- Ejecutar trabajos de ajuste fino
- Descargar los pesos del modelo resultantes
- Sanear completamente los entornos remotos
- Implementar modelos entrenados en infraestructura interna aislada
Este enfoque proporcionó capacidades de IA médica personalizadas sin exponer ninguna información de salud protegida a sistemas externos.
Validación regulatoria
El IRB de la institución revisó la implementación de IA como parte de las enmiendas del protocolo de investigación. La clara separación entre entrenamiento de datos públicos (externo) e inferencia de datos de pacientes (interno, aislado) satisfizo los requisitos de privacidad. Los oficiales de cumplimiento de HIPAA aprobaron la arquitectura después de la evaluación de seguridad.

El imperativo estratégico
Las organizaciones que ven la política de IA únicamente a través de una lente de mitigación de riesgos pierden el panorama más amplio. Las empresas que prohíben ChatGPT hoy no están abandonando la IA. Se están reposicionando para una ventaja sostenible.
Diferenciación competitiva a través de datos
Las capacidades de IA más valiosas emergen de datos propietarios. Un modelo de lenguaje genérico entrenado en texto de internet proporciona capacidades genéricas disponibles para todos. Un modelo ajustado finamente en sus interacciones con clientes, sus datos operativos y su conocimiento institucional proporciona capacidades únicas para su organización.
Esta diferenciación requiere mantener los datos propietarios como propietarios. Las organizaciones que alimentan sus ventajas competitivas en servicios de IA en la nube contribuyen a modelos que benefician a todos los usuarios—incluyendo competidores. Las organizaciones que mantienen el control de datos mientras implementan IA privada acumulan ventajas que se componen con el tiempo.
Trayectoria regulatoria
La regulación de IA se está endureciendo, no aflojando. La Ley de IA de la UE establece un precedente que otras jurisdicciones seguirán. Las agencias estadounidenses incluyendo la FTC, SEC y reguladores bancarios están desarrollando orientación específica de IA. China ha implementado regulaciones de IA que afectan el entrenamiento y la implementación de modelos.
Las organizaciones que construyen infraestructura de IA privada ahora se están preparando para entornos regulatorios que restringirán cada vez más el uso de IA en la nube. La inversión en arquitectura compatible se vuelve más valiosa a medida que los requisitos de cumplimiento se intensifican.
Consideraciones de cadena de suministro
La dependencia de un único proveedor de IA crea vulnerabilidad estratégica. Los precios, políticas y capacidades de OpenAI cambian a su discreción. Las interrupciones del servicio afectan a todos los clientes simultáneamente. Los cambios de política pueden prohibir casos de uso previamente aceptables de la noche a la mañana.
La implementación de IA privada elimina la dependencia de un solo proveedor. Los modelos de pesos abiertos son descargables y están permanentemente disponibles. Existen múltiples opciones de hardware para la implementación. La organización controla su cadena de suministro de IA en lugar de depender de decisiones externas.
Hoja de ruta de implementación
Para organizaciones listas para pasar más allá de las prohibiciones de ChatGPT hacia la capacidad de IA privada, recomendamos un enfoque por fases.
Acciones inmediatas (Semana 1-2)
- Auditar el uso actual de IA en toda la organización
- Clasificar tipos de datos por sensibilidad y requisitos regulatorios
- Documentar qué casos de uso requieren infraestructura privada versus uso de nube aceptable
- Establecer política provisional que aclare actividades prohibidas y permitidas
Desarrollo a corto plazo (Mes 1-3)
- Evaluar opciones de infraestructura basadas en requisitos de sensibilidad y presupuesto
- Seleccionar casos de uso iniciales para implementación de IA privada
- Identificar fuentes de datos de entrenamiento para personalización del modelo
- Establecer protocolos de seguridad para uso de GPU externo si aplica
Implementación a mediano plazo (Mes 3-6)
- Ajustar finamente modelos en datos organizacionales siguiendo nuestra guía técnica
- Implementar infraestructura de inferencia con controles de acceso apropiados
- Integrar con sistemas de cumplimiento y auditoría existentes
- Capacitar a usuarios en flujos de trabajo y herramientas aprobados
Operaciones continuas
- Actualizaciones regulares del modelo incorporando nuevos datos de entrenamiento
- Evaluaciones de seguridad de la infraestructura de IA
- Actualizaciones de políticas que reflejen cambios regulatorios
- Expansión de capacidades a casos de uso adicionales
Conclusión
Las prohibiciones corporativas de ChatGPT reflejan gestión de riesgos racional, no tecnofobia. Cuando Samsung prohibió la herramienta después de descubrir que se habían subido diseños de semiconductores propietarios, tomaron la decisión correcta. Cuando JPMorgan restringió el acceso proactivamente, demostraron conciencia regulatoria apropiada. Cuando los sistemas de salud bloquean el acceso a nivel de firewall, protegen la privacidad del paciente como lo requiere la ley.
Pero la prohibición no es estrategia. Las organizaciones que se detienen en “no” renuncian a las ventajas de productividad que sus competidores capturarán. Las empresas que prosperarán serán aquellas que reconozcan que existe un tercer camino.
Los modelos de pesos abiertos que se ejecutan en infraestructura privada proporcionan capacidad de IA sin exposición de datos. Los modelos están disponibles ahora. La infraestructura es accesible. Los flujos de trabajo técnicos están documentados. La única barrera es la voluntad organizacional para implementar.
Sus competidores que están ajustando finamente modelos en sus datos propietarios—entrenando sistemas que entienden a sus clientes, sus productos y sus operaciones—están construyendo ventajas que usted no puede replicar suscribiéndose a un servicio genérico. Mientras usted debate políticas, ellos están implementando capacidades.
Las decisiones de infraestructura que tome hoy determinan si la IA se convierte en su ventaja competitiva o en la ventaja de sus competidores sobre usted. Los servicios de IA en la nube convierten sus datos en recursos compartidos. La implementación de IA privada convierte sus datos en capacidad única.
La elección no es si usar IA. La elección es si controlarla.
Recursos relacionados
Este artículo aborda el contexto estratégico y regulatorio para las decisiones empresariales de IA. Los siguientes recursos proporcionan orientación de implementación técnica:
Guía de implementación principal
- La guía definitiva para el ajuste fino privado de LLM en GPUs descentralizadas — Flujo de trabajo técnico completo para entrenar modelos personalizados
Seguridad y operaciones
- Cómo asegurar su conjunto de datos en un nodo GPU público — Prácticas de seguridad operativa para cómputo descentralizado
- Cómo alquilar una GPU sin KYC — Flujos de trabajo de alquiler anónimo para implementaciones sensibles a la privacidad
Plataforma y economía
- Comparación de precios de alquiler de GPU 2026 — Análisis de costos en opciones de implementación
- Escrow de contrato inteligente explicado — Cómo los pagos descentralizados protegen a ambas partes
- Las stablecoins son la forma más inteligente de pagar por alquiler de GPU — Mecánicas de pago para infraestructura descentralizada
Comparaciones técnicas
- Ollama vs vLLM vs TGI: Benchmarking de velocidades de inferencia en GPUs de consumidor — Selección de servidor de inferencia para implementación
- Comparación RunPod vs Vast.ai — Evaluación de marketplace para alquileres de GPU