
המזכר אינו מספק איש אך משנה הכל.
כאשר חטיבת המוליכים למחצה של Samsung גילתה שמהנדסים העלו עיצובי שבבים קנייניים ל-ChatGPT, התגובה הייתה מיידית ומוחלטת. איסור ברמת החברה כולה. ללא חריגים. ללא הליך ערעור. הכלי שהפך לשם נרדף לפרודוקטיביות AI נאסר כעת בכל רשתות החברה.
Samsung לא הייתה לבד. תוך חודשים, הכרזות דומות צצו מ-JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank ועשרות ארגונים אחרים. משרדי עורכי דין המייעצים לחברות Fortune 500 אסרו על עורכי דין להשתמש בשירות. מערכות בריאות חסמו גישה ברמת חומת האש. סוכנויות ממשלתיות הוציאו הנחיות שהסירו למעשה כל עמימות לגבי שימוש מקובל.
הדפוס חשף משהו שחובבי הטכנולוגיה התעלמו ממנו בהתלהבותם מיכולות ה-AI: אימוץ ארגוני פועל תחת מגבלות שאימוץ צרכני אינו כפוף להן.
מאמר זה בוחן מדוע מדיניות AI ארגונית מתהדקת, אילו סיכונים ספציפיים מניעים החלטות אלה וכיצד ארגונים יכולים לשמור על יכולות AI מבלי לקבל חשיפת נתונים בלתי מקובלת. הדרך קדימה אינה דורשת נטישת AI. היא דורשת הבנה שהתשתית חשובה לא פחות מהאינטליגנציה.

האירועים ששינו הכל
איסורי AI ארגוניים לא צמחו מהערכות סיכון תיאורטיות. הם עקבו אחר אירועים ממשיים שבהם מידע סודי נמלט משליטה ארגונית.
פרצת המוליכים למחצה של Samsung
בתחילת 2023, עובדי Samsung Electronics השתמשו ב-ChatGPT לניפוי באגים בקוד מקור ולאופטימיזציה של תהליכי ייצור מוליכים למחצה. מהנדסים הדביקו קוד קנייני ישירות בממשק הצ’אט. אחרים העלו רשימות פגישות המכילות דיונים על תכנון אסטרטגי. תוך שלושה שבועות מאז אושר ChatGPT לשימוש פנימי, צוות אבטחת המידע של Samsung זיהה מקרים מרובים של העברת נתונים סודיים לשרתי OpenAI.
תעשיית המוליכים למחצה פועלת עם שולי רווח הנמדדים בננומטרים ויתרונות תחרותיים הנמדדים בחודשים. האפשרות שתהליכי הייצור של Samsung שוכנים כעת בקורפוס האימון של OpenAI—עלולים להיות נגישים למתחרים המשתמשים באותו שירות—הייתה בלתי מקובלת. Samsung יישמה איסור מוחלט והחלה לפתח כלי AI פנימיים שלעולם לא יעבירו נתונים כלפי חוץ.
תגובת תעשיית השירותים הפיננסיים
JPMorgan Chase הגביל גישה ל-ChatGPT לפני כל אירוע מפורסם, תוך הכרה פרואקטיבית בהשלכות הרגולטוריות. כאשר עובדי בנק מנתחים תיקי לקוחות, דנים באסטרטגיות מיזוג או מעריכים סיכוני אשראי, הם מטפלים במידע הכפוף לתקנות SEC, חוקי סודיות בנקאית וחובות נאמנות. העברת מידע כזה לשירות AI של צד שלישי—ללא קשר למדיניות הפרטיות המוצהרת של אותו שירות—יוצרת חשיפת ציות שאף יועץ משפטי כללי לא יקבל.
Goldman Sachs, Citigroup, Bank of America ו-Deutsche Bank עקבו עם הגבלות דומות. התגובה המתואמת של תעשיית השירותים הפיננסיים שיקפה לא פרנויה אלא הבנה מקצועית של אחריות רגולטורית. פרצת נתונים שמקורה בשימוש עובדים ב-ChatGPT תדרוש גילוי, תעורר חקירה רגולטורית ועלולה להוביל לפעולות אכיפה.
השלכות על התעשייה המשפטית
לשכת עורכי הדין האמריקאית לא הוציאה איסור גורף על כלי AI, אך ההשפעה המעשית של דרישות חיסיון עורך דין-לקוח מתקרבת לכך. כאשר עורך דין דן בעניינים של לקוחות עם ChatGPT, השיחה עשויה לוותר על הגנת החיסיון. מידע שנחשף לצדדים שלישיים—אפילו מערכות AI—עלול לאבד את הסודיות שהופכת ייעוץ משפטי למוגן.
משרדי עורכי דין גדולים כולל Davis Polk, Cravath ו-Sullivan & Cromwell יישמו הגבלות הנעות מאיסורים מוחלטים ועד מדיניות שימוש מאושר בלבד הדורשת אישור שותף. תגובת המקצוע המשפטי הדגימה שסיכוני AI מתרחבים מעבר לאבטחת נתונים לשאלות יסודיות של אחריות מקצועית.
המציאות הטכנית של טיפול בנתוני AI בענן
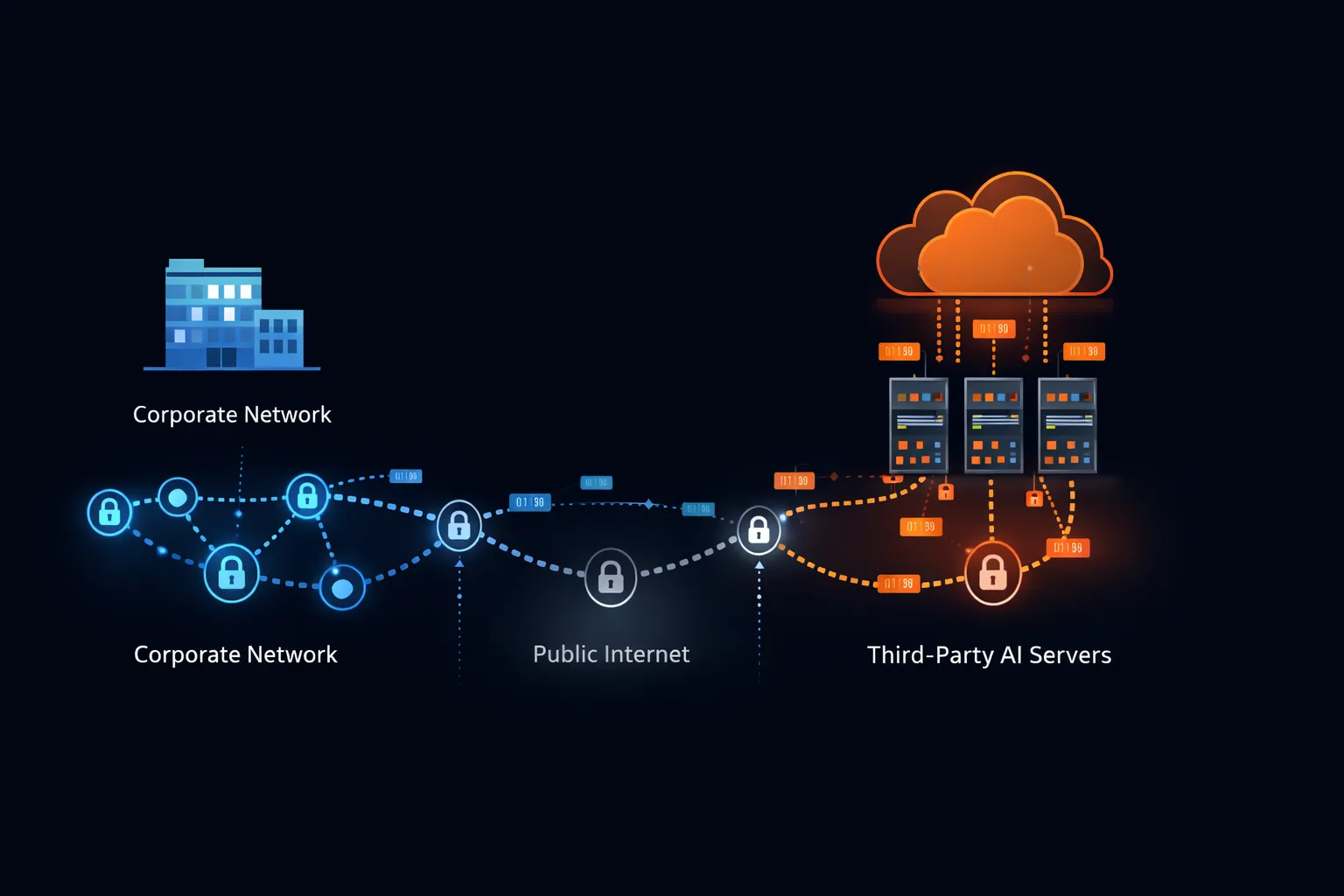
הבנת מדוע ארגונים אוסרים על ChatGPT דורשת בחינה של מה שקורה בפועל כאשר אתם שולחים הודעה לשירות AI בענן.
נתיב העברת נתונים
כאשר אתם מקלידים הנחיה ב-ChatGPT, הטקסט שלכם נוסע מהמכשיר שלכם דרך רשת החברה שלכם, דרך האינטרנט הציבורי, לתשתית של OpenAI. OpenAI פועלת בעיקר על Microsoft Azure, מה שאומר שהנתונים שלכם עוברים ברשת של Microsoft ושוכנים על שרתים המנוהלים על ידי Microsoft.
העברה זו מתרחשת ללא קשר לרגישות התוכן. המערכת אינה יכולה להבחין בין בקשה לכתוב שיר לבין בקשה לנתח תנאי מיזוג סודיים. כל תו שאתם מזינים עוקב אחר אותו נתיב לאותו יעד.
מדיניות שמירת נתונים
מדיניות השימוש בנתונים של OpenAI התפתחה לאורך זמן, אך יסודות מסוימים נשארים עקביים. קלטי משתמשים נרשמים. שיחות נשמרות. משך ומטרת האחסון תלויים ברמת המנוי שלכם ובהסכמים ספציפיים.
עבור מנויי רמה חינמית ו-Plus, OpenAI שומרת במפורש על הזכות להשתמש בקלטים לשיפור המודל. ההנחיות שלכם הופכות לנתוני אימון. הקוד הסודי שהדבקתם כדי לנפות באג עשוי להשפיע על אופן התגובה של המודל למשתמשים עתידיים—עלול לכלול את המתחרים שלכם.
משתמשי API ומנויי Enterprise יכולים לבחור שלא לתרום לנתוני אימון, אך הקלטים שלהם עדיין מעובדים על תשתית OpenAI. הנתונים עדיין קיימים על שרתים שאינכם שולטים בהם, מנוהלים על ידי עובדים שלא בדקתם, כפופים להליכים משפטיים שאינכם יכולים להשפיע עליהם.
בעיית הצד השלישי
ארכיטקטורות אבטחה ארגוניות מבחינות בין מערכות צד ראשון (תשתית שאתם מחזיקים ומפעילים), מערכות צד שני (ספקים עם קשרים חוזיים ישירים ובקרות אבטחה מבוקרות), ומערכות צד שלישי (שירותים הנגישים ללא אינטגרציית אבטחה מפורטת).
ChatGPT, עבור רוב המשתמשים, פועל כצד שלישי לא מבוקר. אלא אם הארגון שלכם ניהל משא ומתן על הסכם ארגוני ספציפי עם נספחי אבטחה, זכויות בדיקת חדירה והסמכות ציות הממופות לדרישות שלכם, ChatGPT יושב מחוץ להיקף האבטחה שלכם עם גישה לכל נתון שהעובדים בוחרים לשתף.
מציאות ארכיטקטונית זו מסבירה מדוע צוותי אבטחה מתייחסים ל-ChatGPT באופן שונה מ-Microsoft Office או Salesforce. מערכות אלה, למרות שהן מבוססות ענן, פועלות תחת הסכמים ארגוניים עם בקרות אבטחה מוגדרות, זכויות ביקורת ותנאי אחריות. ChatGPT, עבור משתמש עם מנוי של 20$/חודש, אינו מציע אף אחת מההגנות הללו.
מסגרות רגולטוריות המניעות זהירות ארגונית
מדיניות AI ארגונית אינה קיימת בחלל ריק. היא מגיבה לדרישות משפטיות שקדמו ל-ChatGPT וישרדו אותו.
GDPR והגנת נתונים אירופית
תקנת הגנת הנתונים הכללית מטילה דרישות קפדניות על עיבוד נתונים אישיים של תושבי האיחוד האירופי. כאשר עובד מדביק מידע לקוחות ב-ChatGPT, הוא מתחיל העברת נתונים למעבד מבוסס ארה”ב. העברה זו דורשת בסיס משפטי—או החלטות התאמה, סעיפים חוזיים סטנדרטיים או כללים ארגוניים מחייבים.
הסכמי עיבוד הנתונים של OpenAI עשויים לעמוד בדרישות GDPR עבור מקרי שימוש מסוימים, אך רוב העובדים המשתמשים במוצר הצרכני אין להם הסכם כזה. הם פשוט מעבירים נתונים אישיים לתאגיד זר ללא הרשאה.
רגולטורים איטלקיים אסרו זמנית על ChatGPT ב-2023 במיוחד בשל חששות GDPR. אמנם השירות התחדש לאחר ש-OpenAI ביצעה התאמות ציות, האירוע הדגים נכונות רגולטורית לפעול. ארגונים אירופיים מתמודדים עם אחריות ישירה לפעולות עובדים שמפרות את ה-GDPR, ויוצרים תמריצים חזקים למדיניות מגבילה.
HIPAA ונתוני בריאות
חוק ניידות ואחריות ביטוח הבריאות אוסר על חשיפת מידע בריאותי מוגן (PHI) למעט בנסיבות מורשות ספציפיות. עובד בריאות הדן במקרי מטופלים עם ChatGPT חושף PHI לנמען לא מורשה.
לא קיים הסכם שותף עסקי בין ארגוני בריאות טיפוסיים ל-OpenAI. שום ביקורת אבטחה לא אימתה את ציות ChatGPT להגנות הטכניות של HIPAA. שום מסגרת משפטית אינה מאשרת את החשיפה.
ארגוני בריאות שמגלים שעובדים שיתפו PHI דרך ChatGPT מתמודדים עם דרישות הודעה על הפרה, חקירת OCR פוטנציאלית וקנסות המגיעים ל-1.5 מיליון דולר לקטגוריית הפרה בשנה. תוצאות אלה מסבירות מדוע מערכות בתי חולים חוסמות ChatGPT ברמת הרשת במקום להסתמך על ציות למדיניות.
תקנות פיננסיות
בנקים, ברוקרים ויועצי השקעות פועלים תחת תקנות SEC, FINRA, OCC והפדרל ריזרב המחייבות שמירת רשומות ופיקוח על תקשורת עסקית. כאשר אנליסט משתמש ב-ChatGPT לניסוח התכתבות עם לקוחות, שיחה זו צריכה להילכד בארכיוני ציות.
ChatGPT אינו מספק אינטגרציה עם מערכות ארכיון ארגוניות. שום כלי פיקוח אינו מסמן שימוש בעייתי פוטנציאלי. השיחה קיימת רק על שרתי OpenAI ומכשיר העובד—אף אחד מהם אינו עומד בדרישות שמירת רשומות רגולטוריות.
מעבר לשמירת רשומות, רגולטורים פיננסיים מביעים דאגה לגבי ייעוץ השקעות שנוצר על ידי AI, מעורבות AI בהחלטות אשראי וניתוחי AI שעלולים להוות מניפולציה בשוק. הנוף הרגולטורי נשאר לא ודאי, וקציני ציות מגיבים לאי-ודאות על ידי הגבלת השימוש במקום לאפשר אותו עד להבהרה.
רגולציה מתהווה ספציפית ל-AI
חוק ה-AI של האיחוד האירופי, הצפוי להיכנס לתוקף בהדרגה במהלך 2025 ו-2026, יטיל דרישות נוספות על פריסת מערכות AI. יישומי AI בסיכון גבוה—כולל אלה המשפיעים על תעסוקה, אשראי וחינוך—דורשים הערכות התאמה, תיעוד ופיקוח אנושי.
ארגונים המשתמשים ב-ChatGPT בהקשרים אלה עלולים למצוא עצמם מפעילים מערכות AI לא תואמות ברגע שהתקנות ייכנסו לתוקף. ארגונים פרואקטיביים מגבילים שימוש עכשיו במקום להתמודד עם תיקון ציות מאוחר יותר.
קניין רוחני: הסיכון שאף חוזה אינו פותר
ציות רגולטורי מייצג קטגוריה אחת של דאגה. הגנה על קניין רוחני מייצגת אחרת—ועבור ארגונים רבים, הנושא המשמעותי יותר.
סודות מסחריים וסודיות
הגנת סודות מסחריים תחת חוק הגנת סודות מסחריים והמקבילות המדינתיות דורשת שהמידע יישאר סודי באמצעות אמצעי הגנה סבירים. כאשר עובד מדביק אלגוריתמים קנייניים, תהליכי ייצור או תוכניות אסטרטגיות ב-ChatGPT, אמצעי ההגנה של הארגון נכשלו.
בתי משפט המעריכים תביעות סודות מסחריים בוחנים האם הצד התובע נקט צעדים סבירים לשמור על הסודיות. מתן אפשרות לעובדים לשתף מידע סודי עם שירותי AI של צדדים שלישיים מערער דרישה זו. גם אם המידע לעולם אינו דולף ממערכות OpenAI, מעשה החשיפה עצמו עשוי לפגוע בהגנה המשפטית.
דאגה זו מתרחבת מעבר להתדיינות היפותטית. חברות טוענות באופן קבוע לסודות מסחריים נגד עובדים עוזבים ומתחרים. אם הגילוי חושף שהמידע ה”סודי” שותף בעבר עם ChatGPT—נגיש למיליוני משתמשים דרך אימון מודל פוטנציאלי—התביעה נחלשת משמעותית.
קוד מקור ונכסים טכניים
חברות תוכנה מתמודדות עם חשיפה מיוחדת. מפתחים רוצים באופן טבעי להשתמש בכלי AI לניפוי באגים בקוד, יצירת תבניות והאצת פיתוח. אך קוד מקור מייצג את הנכס המרכזי של עסק תוכנה. ברגע שהועבר ל-ChatGPT, קוד זה קיים מחוץ לשליטה ארגונית.
הדאגה לגבי נתוני אימון אינה תיאורטית. מודלים לשוניים גדולים לומדים מהקלטים שלהם. בעוד OpenAI מציינת שלקוחות Enterprise ו-API יכולים לבחור שלא לתרום לאימון, המוצר הצרכני אינו נושא ערבות כזו. קוד ששיתף מפתח אחד עשוי להשפיע על השלמות המוצגות לאחר—אולי בחברה מתחרה.
האזהרה הפנימית של Amazon לעובדים ציינה במפורש את הסיכון שתגובות ChatGPT עלולות להידמות למידע סודי של Amazon, מה שמרמז שנתונים דומים כבר שולבו במודל. האם זה ייצג קוד Amazon ממשי בנתוני אימון או פשוט דפוסים דומים נותר לא ברור. העמימות עצמה הניעה את המדיניות המגבילה.
מידע לקוחות וצרכנים
חברות שירותים מקצועיים—יועצים, רואי חשבון, עורכי דין, אדריכלים—עובדות עם מידע לקוחות ששייך לאותם לקוחות, לא לספק השירות. שיתוף נתוני לקוחות עם ChatGPT עשוי להפר מכתבי התקשרות, הסכמי סודיות וכללי אתיקה מקצועית.
יועץ שמעלה תחזיות פיננסיות של לקוח ל-ChatGPT לניתוח שיתף את המידע הסודי של אותו לקוח עם צד שלישי. חברת היועץ עלולה להתמודד עם תביעות הפרת חוזה, משמעת מקצועית ואובדן קשרי לקוחות אם הדבר מתגלה.
דאגות אלה חלות באופן שווה על כל עסק המטפל בנתוני לקוחות. נציג מכירות שמדביק התכתבות לקוחות ב-ChatGPT לניסוח תגובה העביר תקשורת לקוחות ל-OpenAI. בהתאם לתעשייה ולהסכמים הרלוונטיים, הדבר עשוי להפר התחייבויות לטיפול בנתוני לקוחות.

אי-ספיקת הסכמי AI ארגוניים
OpenAI מציעה ChatGPT Enterprise במיוחד כדי לטפל בדאגות ארגוניות. Microsoft מספקת Azure OpenAI Service עם תכונות אבטחה ארגוניות. מוצרים אלה משתפרים על פני הצעות צרכניות אך אינם מבטלים דאגות יסודיות עבור מקרי שימוש ברגישות גבוהה.
מה מספקים הסכמים ארגוניים
ChatGPT Enterprise כולל מספר שיפורים משמעותיים:
- נתונים אינם משמשים לאימון מודל
- הסמכת ציות SOC 2 Type 2
- הצפנת נתונים במנוחה ובמעבר
- אינטגרציית SSO ובקרות מנהליות
- בקרות שמירת נתונים
תכונות אלה מספקות דרישות עבור מקרי שימוש ארגוניים רבים. צוות שיווק המנסח טקסט קמפיין מתמודד עם סיכון מינימלי. מחלקת שירות לקוחות המייצרת תבניות תגובה פועלת בתוך פרמטרים מקובלים.
מה הסכמים ארגוניים אינם יכולים לספק
עבור תעשיות מוסדרות וקניין רוחני רגיש, הסכמים ארגוניים נופלים בדרכים יסודיות.
ראשית, נתונים עדיין מעובדים על תשתית שאינכם שולטים בה. המידע שלכם שוכן על שרתי OpenAI, מנוהל על ידי עובדי OpenAI, כפוף לנוהלי האבטחה של OpenAI. אתם סומכים על היישום שלהם. סומכים על בדיקת העובדים שלהם. סומכים על תגובת האירועים שלהם. אמון זה עשוי להיות מוצדק, אך זה אמון בכל זאת—לא אימות.
שנית, נתונים נשארים כפופים להליך משפטי. צו הזמנה שהוגש ל-OpenAI יכול לכפות חשיפת השיחות שלכם. חקירה ממשלתית בלקוח אחר עלולה לחשוף תשתית משותפת. מכתבי ביטחון לאומי וצווי בית משפט FISA פועלים תחת דרישות סודיות שימנעו מ-OpenAI להודיע לכם על גישה.
שלישית, שטח ההתקפה כולל את כל ארגון OpenAI. היקף האבטחה שלכם כבר לא מסתיים בגבול הרשת שלכם. כל עובד OpenAI עם גישה למערכת, כל ספק עם גישה לתשתית, כל פגיעות אבטחה במערכות OpenAI הופכת לחלק מפרופיל הסיכון שלכם.
רביעית, יציאה וניידות נשארות מוגבלות. היסטוריית השיחות שלכם, התנהגויות מכווננות וידע ארגוני שנצבר ב-ChatGPT שייכים לאינטראקציות עם מערכת OpenAI. מעבר לחלופה דורש בנייה מחדש מאפס.
עבור חברת תרופות המפתחת תרכובות חדשניות, קבלן ביטחוני המטפל במחקר כמעט מסווג, או מוסד פיננסי עם אלגוריתמי מסחר המייצגים מיליארדים בערך פוטנציאלי, מגבלות אלה חשובות. הסכמים ארגוניים מפחיתים סיכון. הם אינם מבטלים אותו.
החלופה של משקולות פתוחות
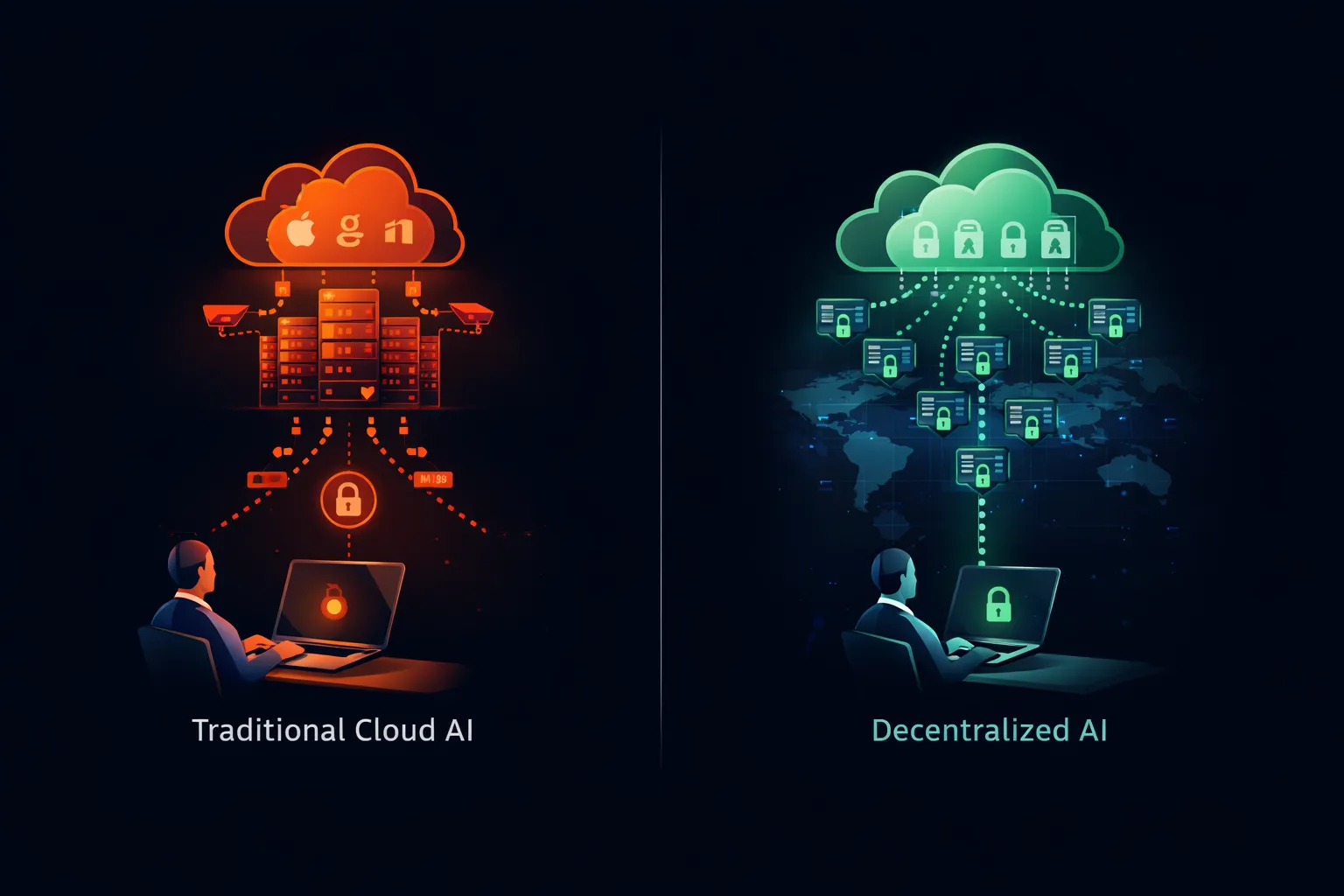
ההגבלות המניעות איסורי ChatGPT ארגוניים אינן חלות על AI בכלל. הן חלות במיוחד על שירותי AI בענן שבהם נתונים עוזבים שליטה ארגונית. ארכיטקטורה שונה מבטלת דאגות אלה לחלוטין.
מה מספקים מודלים פתוחי משקולות
מודלים פתוחי משקולות—Llama מ-Meta, Mistral מ-Mistral AI, Qwen מ-Alibaba ועשרות אחרים—מספקים קבצי מודל להורדה הפועלים על כל חומרה תואמת. משקולות המודל ציבוריות. קוד ההסקה הוא קוד פתוח. אתם יכולים להפעיל את המערכת כולה על תשתית שאתם מחזיקים ומפעילים.
כאשר אתם מריצים Llama על השרת שלכם, ההנחיות שלכם לעולם אינן עוזבות את הרשת שלכם. שום צד שלישי אינו מקבל את הנתונים שלכם. שום שירות ענן אינו רושם את השאילתות שלכם. שום צינור אימון אינו משלב את הקלטים שלכם. המודל רץ מקומית, מעבד מקומית ואינו מאחסן דבר מעבר למה שאתם מגדירים במפורש.
ארכיטקטורה זו מספקת כל דאגה שמניעה איסורי ChatGPT:
-
ציות רגולטורי: נתונים נשארים בתוך היקף האבטחה שלכם, כפופים לבקרות שלכם, נשלטים על ידי המדיניות שלכם. העברות נתונים של GDPR אינן מתרחשות כי נתונים אינם מועברים. דאגות HIPAA מתפוגגות כי אין חשיפה לצדדים לא מורשים.
-
הגנת קניין רוחני: סודות מסחריים נשארים סודיים. קוד מקור לעולם אינו עוזב את המערכות שלכם. סודיות לקוח נשמרת כי שום צד שלישי אינו מקבל מידע לקוח.
-
בקרת אבטחה: שטח ההתקפה שלכם נשאר שלכם. אתם מאמתים את נוהלי האבטחה שלכם. בודקים את הצוות שלכם. שולטים בתגובת האירועים שלכם. פגיעויות של שום ארגון חיצוני אינן משפיעות על הנתונים שלכם.
-
ביקורת וציות: כל שאילתה, כל תגובה, כל אינטראקציה עם המודל יכולה להירשם בהתאם לדרישות שלכם. שמירת רשומות רגולטורית משתלבת עם מערכות הארכיון הקיימות שלכם.
השוואת יכולות
השאלה הטבעית היא האם מודלים פתוחי משקולות משתווים ליכולות ChatGPT. התשובה הכנה: זה תלוי במקרה השימוש.
עבור שאילתות ידע כללי, אימון ChatGPT על נתונים בקנה מידה אינטרנטי מספק רוחב שמודלים פתוחים קטנים יותר אינם יכולים להשתוות לו. יכולות החשיבה של GPT-4 בבעיות מורכבות עולות על מה ש-Llama-3-8B משיג.
אך מקרי שימוש ארגוניים רק לעתים רחוקות דורשים ידע בקנה מידה אינטרנטי. צוות משפטי המנתח חוזים זקוק להבנת מסמכים ויצירת שפה מדויקת—יכולות שבהן מודלים פתוחים מכווננים מצטיינים. צוות פיתוח המנפה באגים בקוד זקוק לזיהוי דפוסים בתוך בסיסי קוד ספציפיים—משימה שבה אימון מותאם אישית עולה באופן דרמטי על מודלים גנריים.
התובנה הקריטית היא שכיוונון הופך מודלים גנריים למומחי תחום. מודל Llama-3-8B מכוונן על מסמכי הארגון שלכם, סטנדרטי קידוד ודפוסי תקשורת יעלה על GPT-4 עבור המשימות הספציפיות שלכם תוך שמירה על בידוד נתונים מלא.
המדריך הראשי שלנו על כיוונון LLM פרטי על GPUs מבוזרים מספק את זרימת העבודה הטכנית המלאה לתהליך זה.
אפשרויות תשתית לפריסת AI פרטית
הפעלת מודלים פתוחי משקולות דורשת חישוב GPU. לארגונים יש מספר אפשרויות לרכישת יכולת זו.
חומרה מקומית
רכישת GPUs של NVIDIA למרכזי נתונים פנימיים מספקת שליטה מרבית. החומרה יושבת במתקן שלכם, מנוהלת על ידי הצוות שלכם, מחוברת לרשת שלכם. לשום גורם חיצוני אין גישה כלשהי.
האתגר הוא הוצאה הונית וזמן אספקה. GPU NVIDIA H100 עולה כ-30,000 דולר. אשכול משמעותי לאימון דורש יחידות מרובות. לוחות זמנים לרכש מתרחבים לחודשים. תחזוקה שוטפת דורשת מומחיות מתמחה.
עבור ארגונים גדולים עם פעולות מרכז נתונים קיימות, תשתית AI מקומית מייצגת הרחבה טבעית. עבור ארגונים קטנים יותר או אלה ללא מומחיות GPU, המחסומים משמעותיים.
מופעי ענן פרטיים
AWS, GCP ו-Azure מציעים מופעי GPU המספקים יותר שליטה מאשר מוצרי AI SaaS. אתם מגדירים את הסביבה. שולטים בגישה. הנתונים שלכם מעובדים על מופעים ייעודיים במקום שירותים משותפים.
גישה זו משפרת על ארכיטקטורת ChatGPT אך שומרת על מעורבות ספק ענן. הנתונים שלכם עדיין שוכנים על תשתית שאינכם שולטים בה פיזית. עובדי ספק ענן עם גישה מספקת יכולים תיאורטית לגשת למערכות שלכם. הליך משפטי שהוגש לספק הענן יכול להגיע לנתונים שלכם.
בנוסף, מופעי GPU ענן פרטיים נושאים עלויות משמעותיות. מופעי AWS p4d.24xlarge (8x A100 GPUs) עולים כ-32 דולר לשעה. ריצות אימון מורחבות או שירותי הסקה מתמשכים מייצרים הוצאות חודשיות משמעותיות. הזמינות מוגבלת—מופעי GPU מציגים לעתים קרובות רשימות המתנה או זמינות אזורית מוגבלת.
השכרות GPU מבוזרות
אפשרות שלישית עוקפת הן הוצאה הונית והן מעורבות ספק ענן. שווקי GPU מבוזרים מחברים משתמשים ישירות עם בעלי חומרה. אתם שוכרים קיבולת חישוב עמית-לעמית, משלמים במטבע קריפטוגרפי, ללא אימות זהות או תיווך ספק ענן.
מודל זה מספק מספר יתרונות לארגונים מודעי פרטיות:
-
אין דרישות KYC: אתם מחברים ארנק ושוכרים חומרה. אין חשבונות ארגוניים. אין תהליך מכירות ארגוני. אין תיעוד זהות המקשר את הארגון שלכם לפעילויות AI ספציפיות.
-
אין מעורבות ספק ענן: הנתונים שלכם מעובדים על חומרה בבעלות אנשים פרטיים, לא תאגידים עם מחלקות משפטיות, חוזים ממשלתיים וקשרים עם רשויות אכיפת חוק.
-
יעילות עלות: השכרות RTX 4090 עולות 0.40 עד 0.60 דולר לשעה, כעשירית מעלות מופעי ענן דומים. השוואת מחירי השכרת GPU שלנו מפרטת את הכלכלה.
-
זמינות גלובלית: היצע מבוזר פירושו אין מגבלות אזוריות. חומרה זמינה כשאתם צריכים אותה, מופצת על פני תחומי שיפוט ברחבי העולם.
עבור ארגונים שאינם יכולים להצדיק הוצאה הונית על חומרת GPU אך דורשים ערבויות פרטיות חזקות יותר ממה שספקי ענן מציעים, השכרות מבוזרות מספקות נתיב ביניים מעשי.
זרימת העבודה כוללת העברת הנתונים שלכם ישירות לצומת ההשכרה דרך חיבור SSH מוצפן, הרצת עבודת האימון או ההסקה שלכם, הורדת תוצאות וסניטציה של הסביבה המרוחקת לפני ניתוק. המדריך שלנו על כיצד לאבטח את מערך הנתונים שלכם על צומת GPU ציבורי מכסה את נוהלי האבטחה התפעוליים בפירוט.
יישום אסטרטגיית AI תואמת
ארגונים העוברים מאיסורי ChatGPT לפריסת AI פרטית צריכים לגשת למעבר באופן שיטתי.
שלב 1: פיתוח מדיניות
התחילו בניסוח מה מדיניות ה-AI שלכם אוסרת ומה היא מתירה בפועל. איסורי ChatGPT ראשוניים רבים היו תגובתיים—איסורים גורפים שיושמו במהירות לעצירת סיכון מיידי. מדיניות בשלה מבחינה בין:
- קטגוריות נתונים שלעולם אינן יכולות להיות מעובדות על ידי מערכות AI חיצוניות
- מקרי שימוש שבהם שירותי AI בענן מקובלים עם בקרות מתאימות
- כלים ופלטפורמות מאושרים לרמות רגישות שונות
- תהליכי אישור לאימוץ כלי AI חדשים
- דרישות דיווח על אירועים להפרות מדיניות
מסגרת זו מאפשרת לשימוש ב-AI להמשיך היכן שזה מתאים תוך הגנה על פעולות רגישות.
שלב 2: הערכת תשתית
הערכו את האפשרויות שלכם לפריסת AI פרטית על בסיס משאבים ודרישות ארגוניות:
-
משאבי GPU קיימים: לארגונים רבים יש תחנות עבודה או שרתים עם GPUs של NVIDIA המשמשים למטרות אחרות (הדמיה, רינדור, חישוב מדעי) שיכולים לתמוך בעומסי עבודה של AI.
-
תקציב ענן וסובלנות סיכון: אם צוות האבטחה שלכם מקבל מעורבות ספק ענן עם בקרות מתאימות, מופעי GPU ענן פרטיים מציעים תפעול פשוט יותר מאפשרויות מקומיות או מבוזרות.
-
דרישות פרטיות: אם מקרה השימוש שלכם כולל נתונים שאינם יכולים לגעת בתשתית ספק ענן בשום נסיבות, חומרה מקומית או השכרות מבוזרות הופכות הכרחיות.
-
היקף ותדירות: עבודות כיוונון מדי פעם מתאימות למודלי השכרה. שירות הסקה מתמשך עשוי להצדיק השקעה הונית.
שלב 3: בחירת מודל והתאמה אישית
מודלים גנריים פתוחי משקולות מספקים נקודת התחלה, אך ערך ארגוני מגיע מהתאמה אישית. כיוונון על הנתונים שלכם יוצר מודלים שמבינים את התחום שלכם, הטרמינולוגיה שלכם והדרישות שלכם.
שקלו אילו מקרי שימוש מציעים את הערך הגבוה ביותר:
- ניתוח מסמכים: חוזים משפטיים, הגשות רגולטוריות, מדיניות פנימית
- סיוע קוד: פיתוח בתוך המסגרות והסטנדרטים הספציפיים שלכם
- תקשורת לקוחות: תגובות המשקפות את קול המותג שלכם וידע המוצר
- ידע פנימי: שאילתת תיעוד ארגוני וידע מוסדי
כל מקרה שימוש עשוי להצדיק מודל מכוונן נפרד, או מודל יחיד שאומן על נתוני ארגון מגוונים עשוי לשרת מטרות מרובות.
שלב 4: אינטגרציה תפעולית
פריסת AI פרטית דורשת יכולות תפעוליות שמוצרי SaaS מפשיטים:
-
תשתית הגשת מודל: הרצת הסקה בקנה מידה דורשת משאבי GPU, איזון עומסים וממשקי API. כלים כמו vLLM, Text Generation Inference ו-Ollama מפשטים פריסה.
-
בקרות גישה: מי יכול לשאול את המודל? איזה רישום מתרחש? כיצד אתם מבקרים שימוש?
-
נהלי עדכון: כיצד אתם משלבים נתוני אימון חדשים? כיצד אתם פורסים גרסאות מודל משופרות?
-
תגובת אירועים: מה קורה אם מודל מייצר פלטים בעייתיים? מי בוחן מקרי קצה?
ארגונים הרגילים לפשטות SaaS עשויים לזלזל בעומס תפעולי זה. תקצבו בהתאם לתחזוקה שוטפת, לא רק לפריסה ראשונית.
מקרה בוחן: ארכיטקטורת ציות לשירותים פיננסיים
בנק אזורי עם 50 מיליארד דולר בנכסים התמודד עם דילמה מוכרת. מנהלי קשרי לקוחות רצו סיוע AI בניסוח תקשורת עם לקוחות וניתוח מיקומי תיקים. קציני ציות הכירו בכך שהעברת נתוני לקוחות פיננסיים ל-ChatGPT הפרה הן דרישות רגולטוריות והן חובות נאמנות.
ארכיטקטורת הפתרון ממחישה כיצד ארגונים יכולים לספק את שני הצדדים.
סיווג נתונים
הבנק הקים שלוש רמות של נתונים המותרים ל-AI:
-
רמה 1 (ציבורי): חומרי שיווק, תוכן חינוך פיננסי ציבורי, תיאורי מוצר כלליים. שירותי AI בענן מותרים עם הנחיות שימוש מקובל סטנדרטיות.
-
רמה 2 (פנימי): מדיניות פנימית, חומרי הדרכה, נהלי תפעול. שירותי AI בענן מותרים עם הסכמים ארגוניים ונספחי טיפול בנתונים.
-
רמה 3 (מוגבל): נתוני לקוחות, מידע תיק, פרטי עסקאות, תכנון אסטרטגי. אין עיבוד AI חיצוני בשום נסיבות.
סיווג זה אפשר אימוץ AI היכן שהסיכון היה מקובל תוך שמירה על הגנה מוחלטת על קטגוריות רגישות.
פריסת תשתית פרטית
עבור מקרי שימוש ברמה 3, הבנק פרס מודל Llama מכוונן על שרתי GPU מקומיים בתוך מרכז הנתונים הקיים שלהם. המודל אומן על:
- תקשורת לקוחות היסטורית אנונימית (עם הסכמת לקוח)
- הנחיות ציות פנימיות ופרשנויות רגולטוריות
- תיעוד מוצר ומחקר השקעות
- תבניות תקשורת מאושרות על ידי ציות
המודל המתקבל הבין טרמינולוגיה בנקאית, מגבלות רגולטוריות וסטנדרטי תקשורת ארגוניים. מנהלי קשרי לקוחות יכלו לנסח מכתבים ללקוחות עם סיוע AI, בידיעה שאין נתוני לקוח עוזבים את היקף האבטחה של הבנק.
בקרות תפעוליות
כל אינטראקציה עם המודל נרשמה במערכת ארכיון הציות הקיימת של הבנק. מפקחים יכלו לבחון תקשורת בסיוע AI לצד התכתבות מסורתית. נתיבי ביקורת סיפקו דרישות שמירת רשומות רגולטוריות.
המודל עצמו פעל בתוך מעקות המונעות פלטים מסוימים—המלצות השקעה, שפת ערבות או הצהרות שעלולות להוות ייעוץ הדורש רישוי ספציפי. מגבלות אלה יושמו בשכבת היישום, מבלי להסתמך על התנהגות המודל בלבד.
תוצאות מדודות
שישה חודשים לאחר הפריסה, הבנק דיווח על:
- הפחתה של 40% בזמן המוקדש לניסוח תקשורת שגרתית עם לקוחות
- אפס אירועי ציות הקשורים לשימוש ב-AI
- בחינה רגולטורית מוצלחת ללא ממצאים הקשורים לפריסת AI
- עלייה בציוני שביעות רצון מנהלי קשרי לקוחות
ההשקעה בתשתית פרטית—כ-200,000 דולר כולל חומרה, פיתוח ואינטגרציה—הניבה החזרים בתוך השנה הראשונה דרך רווחי פרודוקטיביות בלבד.
מקרה בוחן: מוסד מחקר בריאות
מרכז רפואי אקדמי גדול המבצע מחקר קליני התמודד עם מגבלות HIPAA שהפכו כל שימוש ב-AI בענן עם נתוני מטופלים לבעייתי מבחינה משפטית. חוקרים רצו להשתמש ב-AI לסקירת ספרות, פיתוח פרוטוקולים וניתוח נתונים.
הגישה ההיברידית
במקום לבחור בין איסור מוחלט לסיכון בלתי מקובל, המוסד יישם ארכיטקטורה היברידית:
-
משימות מחקר ציבוריות (סקירת ספרות, שאלות מתודולוגיה, גישות סטטיסטיות) השתמשו בשירותי AI בענן עם מדיניות ברורה האוסרת על כל קלט נתוני מטופלים.
-
ניתוח נתוני מטופלים השתמש במודלים שנפרסו מקומית על תחנות עבודה מבודדות אוויר בתוך סביבת המחקר המאובטחת. למכונות אלה לא היה חיבור לאינטרנט. נתונים לא יכלו לצאת ללא קשר להתנהגות המשתמש.
אימון מבוזר
למוסד לא היה תקציב הוני לחומרת GPU מסוגלת אימון אך הוא נזקק למודלים מכווננים על ספרות רפואית ופרוטוקולי מחקר. הם השתמשו בהשכרות GPU מבוזרות לריצות אימון תוך שימוש רק בספרות רפואית ציבורית ומערכי נתונים מופקעי זיהוי ללא השלכות HIPAA.
זרימת העבודה לאימון עקבה אחר נוהלי האבטחה המתוארים במדריך אבטחת מערך נתונים שלנו:
- העברת נתוני אימון לא רגישים בלבד לצמתי השכרה
- הרצת עבודות כיוונון
- הורדת משקולות המודל המתקבלות
- סניטציה מלאה של סביבות מרוחקות
- פריסת מודלים מאומנים על תשתית פנימית מבודדת
גישה זו סיפקה יכולות AI רפואיות מותאמות אישית מבלי לחשוף מידע בריאותי מוגן למערכות חיצוניות.
אימות רגולטורי
ועדת ה-IRB של המוסד בחנה את פריסת ה-AI כחלק מתיקוני פרוטוקול מחקר. ההפרדה הברורה בין אימון נתונים ציבוריים (חיצוני) לבין הסקת נתוני מטופלים (פנימי, מבודד) סיפקה את דרישות הפרטיות. קציני ציות HIPAA אישרו את הארכיטקטורה לאחר הערכת אבטחה.

ההכרח האסטרטגי
ארגונים הרואים מדיניות AI רק דרך עדשת הפחתת סיכונים מפספסים את התמונה הגדולה יותר. הארגונים שאוסרים על ChatGPT היום אינם נוטשים AI. הם ממקמים מחדש ליתרון בר-קיימא.
בידול תחרותי באמצעות נתונים
יכולות ה-AI היקרות ביותר צומחות מנתונים קנייניים. מודל שפה גנרי שאומן על טקסט אינטרנט מספק יכולות גנריות הזמינות לכולם. מודל מכוונן על אינטראקציות הלקוחות שלכם, הנתונים התפעוליים שלכם והידע המוסדי שלכם מספק יכולות ייחודיות לארגון שלכם.
בידול זה דורש שמירה על נתונים קנייניים כקנייניים. ארגונים שמזינים את היתרונות התחרותיים שלהם לשירותי AI בענן תורמים למודלים שמועילים לכל המשתמשים—כולל מתחרים. ארגונים השומרים על שליטה בנתונים תוך פריסת AI פרטית צוברים יתרונות שמתרכבים לאורך זמן.
מסלול רגולטורי
רגולציית AI מתהדקת, לא מתרופפת. חוק ה-AI של האיחוד האירופי קובע תקדים שתחומי שיפוט אחרים יעקבו אחריו. סוכנויות אמריקאיות כולל FTC, SEC ורגולטורים בנקאיים מפתחים הנחיות ספציפיות ל-AI. סין יישמה תקנות AI המשפיעות על אימון ופריסת מודלים.
ארגונים הבונים תשתית AI פרטית עכשיו מתכוננים לסביבות רגולטוריות שיגבילו יותר ויותר שימוש ב-AI בענן. ההשקעה בארכיטקטורה תואמת הופכת יקרה יותר ככל שדרישות הציות מתעצמות.
שיקולי שרשרת אספקה
תלות בספק AI יחיד יוצרת פגיעות אסטרטגית. התמחור, המדיניות והיכולות של OpenAI משתנים לפי שיקול דעתם. הפסקות שירות משפיעות על כל הלקוחות בו-זמנית. שינויי מדיניות יכולים לאסור מקרי שימוש שהיו מקובלים בעבר בן לילה.
פריסת AI פרטית מבטלת תלות בספק יחיד. מודלים פתוחי משקולות זמינים להורדה וזמינים לצמיתות. אפשרויות חומרה מרובות קיימות לפריסה. הארגון שולט בשרשרת אספקת ה-AI שלו במקום להיות תלוי בהחלטות חיצוניות.
מפת דרכים ליישום
עבור ארגונים מוכנים לעבור מעבר לאיסורי ChatGPT ליכולת AI פרטית, אנו ממליצים על גישה מדורגת.
פעולות מיידיות (שבוע 1-2)
- ביקורת שימוש נוכחי ב-AI ברחבי הארגון
- סיווג סוגי נתונים לפי רגישות ודרישות רגולטוריות
- תיעוד אילו מקרי שימוש דורשים תשתית פרטית לעומת שימוש ענן מקובל
- קביעת מדיניות ביניים המבהירה פעילויות אסורות ומותרות
פיתוח לטווח קצר (חודש 1-3)
- הערכת אפשרויות תשתית על בסיס דרישות רגישות ותקציב
- בחירת מקרי שימוש ראשוניים לפריסת AI פרטית
- זיהוי מקורות נתוני אימון להתאמת מודל
- קביעת פרוטוקולי אבטחה לשימוש ב-GPU חיצוני אם רלוונטי
פריסה לטווח בינוני (חודש 3-6)
- כיוונון מודלים על נתונים ארגוניים בעקבות המדריך הטכני שלנו
- פריסת תשתית הסקה עם בקרות גישה מתאימות
- אינטגרציה עם מערכות ציות וביקורת קיימות
- הדרכת משתמשים על זרימות עבודה וכלים מאושרים
תפעול שוטף
- עדכוני מודל קבועים המשלבים נתוני אימון חדשים