
मेमो किसी को संतुष्ट नहीं करता लेकिन सब कुछ बदल देता है।
जब Samsung की सेमीकंडक्टर डिवीजन ने पता लगाया कि इंजीनियरों ने मालिकाना चिप डिजाइन ChatGPT पर अपलोड कर दिए थे, तो प्रतिक्रिया तत्काल और पूर्ण थी। कंपनी-व्यापी प्रतिबंध। कोई अपवाद नहीं। कोई अपील प्रक्रिया नहीं। वह टूल जो AI उत्पादकता का पर्याय बन गया था, अब सभी कॉर्पोरेट नेटवर्क पर प्रतिबंधित था।
Samsung अकेली नहीं थी। महीनों के भीतर, JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank और दर्जनों अन्य उद्यमों से समान घोषणाएं आईं। Fortune 500 कंपनियों को सलाह देने वाली कानूनी फर्मों ने एसोसिएट्स को सेवा का उपयोग करने से मना कर दिया। स्वास्थ्य सेवा प्रणालियों ने फ़ायरवॉल स्तर पर एक्सेस ब्लॉक कर दिया। सरकारी एजेंसियों ने मार्गदर्शन जारी किया जिसने स्वीकार्य उपयोग के बारे में किसी भी अस्पष्टता को प्रभावी रूप से समाप्त कर दिया।
इस पैटर्न ने कुछ ऐसा उजागर किया जिसे प्रौद्योगिकी उत्साही लोगों ने AI क्षमताओं के बारे में अपने उत्साह में अनदेखा कर दिया था: एंटरप्राइज अपनाना उन बाधाओं के तहत संचालित होता है जो उपभोक्ता अपनाना नहीं करता।
यह लेख जांच करता है कि कॉर्पोरेट AI नीतियां क्यों कड़ी हो रही हैं, कौन से विशिष्ट जोखिम इन निर्णयों को प्रेरित करते हैं, और संगठन अस्वीकार्य डेटा एक्सपोजर को स्वीकार किए बिना AI क्षमताओं को कैसे बनाए रख सकते हैं। आगे का रास्ता AI को छोड़ने की आवश्यकता नहीं है। इसके लिए यह समझने की आवश्यकता है कि बुनियादी ढांचा उतना ही मायने रखता है जितना कि बुद्धिमत्ता।

वे घटनाएं जिन्होंने सब कुछ बदल दिया
कॉर्पोरेट AI प्रतिबंध सैद्धांतिक जोखिम आकलन से उत्पन्न नहीं हुए। वे वास्तविक घटनाओं का अनुसरण करते थे जहां गोपनीय जानकारी संगठनात्मक नियंत्रण से बच गई।
Samsung सेमीकंडक्टर उल्लंघन
2023 की शुरुआत में, Samsung Electronics के कर्मचारियों ने सोर्स कोड डीबग करने और सेमीकंडक्टर विनिर्माण प्रक्रियाओं को अनुकूलित करने के लिए ChatGPT का उपयोग किया। इंजीनियरों ने मालिकाना कोड सीधे चैट इंटरफेस में पेस्ट किया। अन्य ने रणनीतिक योजना चर्चाओं वाले मीटिंग नोट्स अपलोड किए। आंतरिक उपयोग के लिए ChatGPT की अनुमति के तीन सप्ताह के भीतर, Samsung की सूचना सुरक्षा टीम ने OpenAI सर्वरों पर गोपनीय डेटा ट्रांसमिशन के कई उदाहरणों की पहचान की।
सेमीकंडक्टर उद्योग नैनोमीटर में मापे गए मार्जिन और महीनों में मापे गए प्रतिस्पर्धी लाभों पर संचालित होता है। यह संभावना कि Samsung की निर्माण प्रक्रियाएं अब OpenAI के प्रशिक्षण कॉर्पस में रहती थीं—संभावित रूप से उसी सेवा का उपयोग करने वाले प्रतियोगियों के लिए सुलभ—अस्वीकार्य थी। Samsung ने पूर्ण प्रतिबंध लागू किया और आंतरिक AI टूल विकसित करना शुरू किया जो कभी भी बाहरी रूप से डेटा ट्रांसमिट नहीं करेंगे।
वित्तीय सेवा उद्योग प्रतिक्रिया
JPMorgan Chase ने किसी भी प्रचारित घटना से पहले ChatGPT एक्सेस को प्रतिबंधित किया, सक्रिय रूप से नियामक निहितार्थों को पहचानते हुए। जब बैंक कर्मचारी ग्राहक पोर्टफोलियो का विश्लेषण करते हैं, विलय रणनीतियों पर चर्चा करते हैं, या क्रेडिट जोखिमों का मूल्यांकन करते हैं, तो वे SEC नियमों, बैंकिंग गोपनीयता कानूनों और प्रत्ययी कर्तव्यों के अधीन जानकारी संभालते हैं। ऐसी जानकारी को तृतीय-पक्ष AI सेवा को प्रेषित करना—उस सेवा की घोषित गोपनीयता नीतियों की परवाह किए बिना—अनुपालन जोखिम पैदा करता है जिसे कोई भी जनरल काउंसल स्वीकार नहीं करेगा।
Goldman Sachs, Citigroup, Bank of America और Deutsche Bank ने समान प्रतिबंधों का पालन किया। वित्तीय सेवा उद्योग की समन्वित प्रतिक्रिया पैरानोइया नहीं बल्कि नियामक दायित्व की पेशेवर समझ को दर्शाती थी। कर्मचारी ChatGPT उपयोग से उत्पन्न डेटा उल्लंघन के लिए प्रकटीकरण की आवश्यकता होगी, नियामक जांच शुरू होगी, और संभावित रूप से प्रवर्तन कार्रवाई हो सकती है।
कानूनी उद्योग निहितार्थ
अमेरिकन बार एसोसिएशन ने AI टूल पर कोई व्यापक प्रतिबंध जारी नहीं किया है, लेकिन अटॉर्नी-क्लाइंट विशेषाधिकार आवश्यकताओं का व्यावहारिक प्रभाव इसके करीब आता है। जब एक वकील ChatGPT के साथ क्लाइंट मामलों पर चर्चा करता है, तो बातचीत विशेषाधिकार सुरक्षा को माफ कर सकती है। तीसरे पक्षों को प्रकट की गई जानकारी—यहां तक कि AI सिस्टम—वह गोपनीयता खो सकती है जो कानूनी सलाह को संरक्षित बनाती है।
Davis Polk, Cravath और Sullivan & Cromwell सहित प्रमुख कानूनी फर्मों ने पूर्ण प्रतिबंधों से लेकर पार्टनर प्राधिकरण की आवश्यकता वाली केवल-स्वीकृत-उपयोग नीतियों तक के प्रतिबंध लागू किए। कानूनी पेशे की प्रतिक्रिया ने प्रदर्शित किया कि AI जोखिम डेटा सुरक्षा से परे पेशेवर जिम्मेदारी के मौलिक प्रश्नों तक फैले हुए हैं।
क्लाउड AI डेटा हैंडलिंग की तकनीकी वास्तविकता
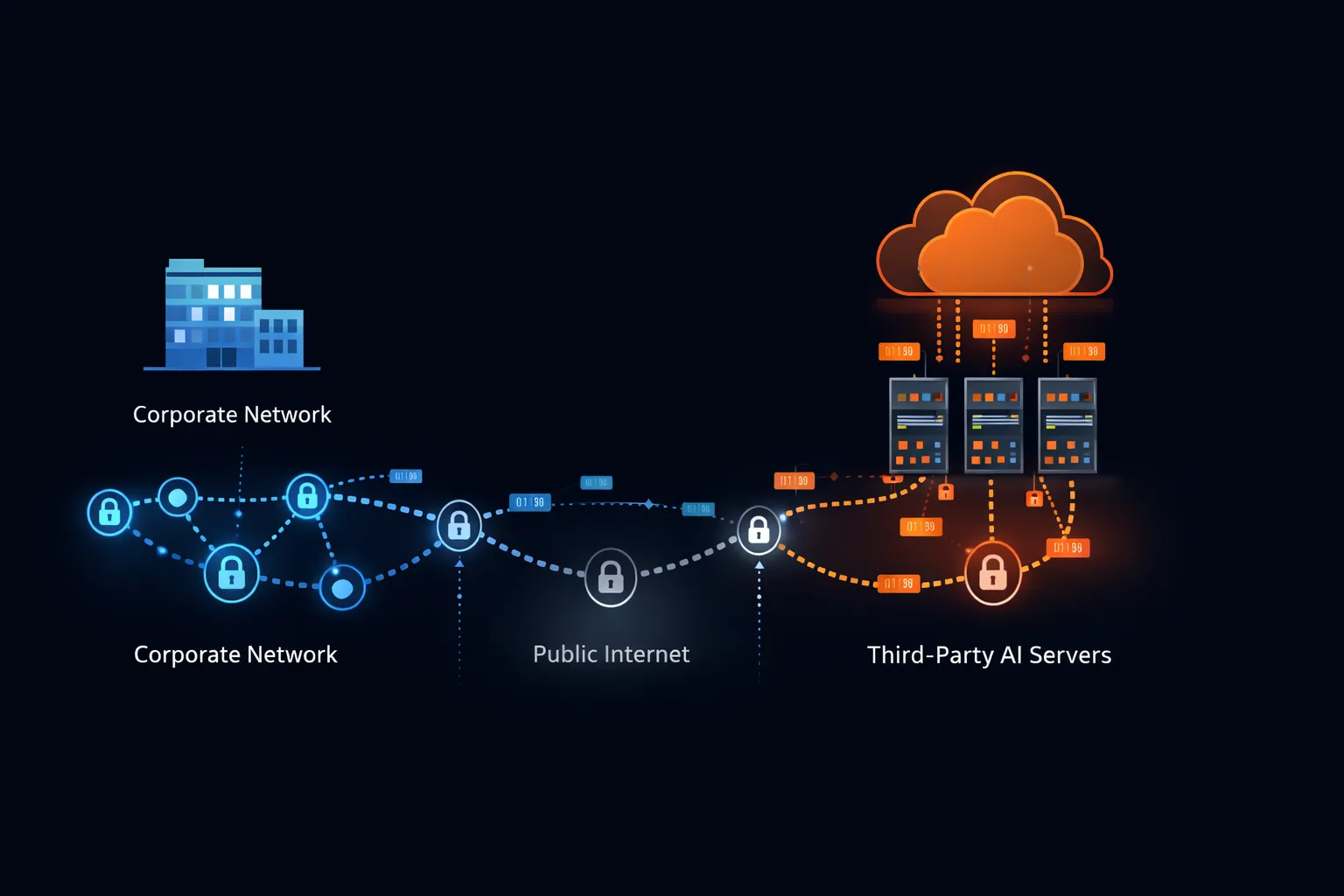
यह समझने के लिए कि उद्यम ChatGPT पर प्रतिबंध क्यों लगाते हैं, यह जांचना आवश्यक है कि जब आप क्लाउड AI सेवा को संदेश भेजते हैं तो वास्तव में क्या होता है।
डेटा ट्रांसमिशन पथ
जब आप ChatGPT में एक प्रॉम्प्ट टाइप करते हैं, तो आपका टेक्स्ट आपके डिवाइस से आपके कॉर्पोरेट नेटवर्क के माध्यम से, सार्वजनिक इंटरनेट के पार, OpenAI के बुनियादी ढांचे तक यात्रा करता है। OpenAI मुख्य रूप से Microsoft Azure पर संचालित होता है, जिसका अर्थ है कि आपका डेटा Microsoft के नेटवर्क से होकर गुजरता है और Microsoft-प्रबंधित सर्वरों पर रहता है।
यह ट्रांसमिशन सामग्री संवेदनशीलता की परवाह किए बिना होता है। सिस्टम कविता लिखने के अनुरोध और गोपनीय विलय शर्तों का विश्लेषण करने के अनुरोध के बीच अंतर नहीं कर सकता। आपके द्वारा दर्ज किया गया प्रत्येक अक्षर उसी पथ पर उसी गंतव्य तक जाता है।
डेटा प्रतिधारण नीतियां
OpenAI की डेटा उपयोग नीतियां समय के साथ विकसित हुई हैं, लेकिन कुछ मूलभूत बातें सुसंगत रहती हैं। उपयोगकर्ता इनपुट लॉग किए जाते हैं। बातचीत संग्रहीत की जाती है। भंडारण की अवधि और उद्देश्य आपके सदस्यता स्तर और विशिष्ट समझौतों पर निर्भर करता है।
फ्री-टियर और Plus सब्सक्राइबर्स के लिए, OpenAI स्पष्ट रूप से मॉडल सुधार के लिए इनपुट का उपयोग करने का अधिकार सुरक्षित रखता है। आपके प्रॉम्प्ट प्रशिक्षण डेटा बन जाते हैं। समस्या को डीबग करने के लिए आपने जो गोपनीय कोड पेस्ट किया था वह भविष्य के उपयोगकर्ताओं को मॉडल कैसे प्रतिक्रिया देता है इसे प्रभावित कर सकता है—संभावित रूप से आपके प्रतियोगियों सहित।
API उपयोगकर्ता और Enterprise सब्सक्राइबर प्रशिक्षण डेटा योगदान से ऑप्ट आउट कर सकते हैं, लेकिन उनके इनपुट अभी भी OpenAI बुनियादी ढांचे पर संसाधित होते हैं। डेटा अभी भी उन सर्वरों पर मौजूद है जिन्हें आप नियंत्रित नहीं करते, उन कर्मचारियों द्वारा प्रबंधित जिन्हें आपने जांचा नहीं है, उन कानूनी प्रक्रियाओं के अधीन जिन्हें आप प्रभावित नहीं कर सकते।
तृतीय-पक्ष समस्या
एंटरप्राइज सुरक्षा आर्किटेक्चर प्रथम-पक्ष सिस्टम (जो बुनियादी ढांचा आप स्वामित्व और संचालित करते हैं), द्वितीय-पक्ष सिस्टम (प्रत्यक्ष अनुबंध संबंधों और ऑडिटेड सुरक्षा नियंत्रणों वाले विक्रेता), और तृतीय-पक्ष सिस्टम (विस्तृत सुरक्षा एकीकरण के बिना एक्सेस की गई सेवाएं) के बीच अंतर करते हैं।
ChatGPT, अधिकांश उपयोगकर्ताओं के लिए, एक गैर-ऑडिटेड तृतीय पक्ष के रूप में संचालित होता है। जब तक आपके संगठन ने सुरक्षा परिशिष्ट, पेनिट्रेशन टेस्टिंग अधिकार और आपकी आवश्यकताओं से मैप किए गए अनुपालन प्रमाणपत्रों के साथ एक विशिष्ट एंटरप्राइज समझौते पर बातचीत नहीं की है, ChatGPT आपके सुरक्षा परिधि के बाहर बैठता है जिसमें जो भी डेटा कर्मचारी साझा करना चुनते हैं उस तक पहुंच है।
यह आर्किटेक्चरल वास्तविकता बताती है कि सुरक्षा टीमें ChatGPT को Microsoft Office या Salesforce से अलग क्यों मानती हैं। वे सिस्टम, क्लाउड-आधारित होने के बावजूद, परिभाषित सुरक्षा नियंत्रणों, ऑडिट अधिकारों और दायित्व शर्तों के साथ एंटरप्राइज समझौतों के तहत संचालित होते हैं। $20/माह सदस्यता वाले उपयोगकर्ता के लिए ChatGPT उनमें से कोई भी सुरक्षा प्रदान नहीं करता।
एंटरप्राइज सावधानी को प्रेरित करने वाले नियामक ढांचे
कॉर्पोरेट AI नीतियां शून्य में मौजूद नहीं हैं। वे कानूनी आवश्यकताओं का जवाब देती हैं जो ChatGPT से पहले मौजूद थीं और इसके बाद भी जारी रहेंगी।
GDPR और यूरोपीय डेटा संरक्षण
जनरल डेटा प्रोटेक्शन रेगुलेशन EU निवासियों के व्यक्तिगत डेटा के प्रसंस्करण पर सख्त आवश्यकताएं लगाता है। जब एक कर्मचारी ChatGPT में ग्राहक जानकारी पेस्ट करता है, तो वह US-आधारित प्रोसेसर को डेटा ट्रांसफर शुरू करता है। इस ट्रांसफर के लिए कानूनी आधार की आवश्यकता होती है—या तो पर्याप्तता निर्णय, मानक संविदात्मक खंड, या बाध्यकारी कॉर्पोरेट नियम।
OpenAI के डेटा प्रोसेसिंग समझौते कुछ उपयोग मामलों के लिए GDPR आवश्यकताओं को पूरा कर सकते हैं, लेकिन उपभोक्ता उत्पाद का उपयोग करने वाले अधिकांश कर्मचारियों के पास ऐसा कोई समझौता नहीं है। वे बस बिना प्राधिकरण के एक विदेशी निगम को व्यक्तिगत डेटा प्रेषित कर रहे हैं।
इटालियन नियामकों ने 2023 में विशेष रूप से GDPR चिंताओं के कारण ChatGPT पर अस्थायी रूप से प्रतिबंध लगा दिया। हालांकि OpenAI द्वारा अनुपालन समायोजन करने के बाद सेवा फिर से शुरू हुई, घटना ने नियामक कार्रवाई करने की इच्छा का प्रदर्शन किया। यूरोपीय उद्यमों को कर्मचारी कार्यों के लिए सीधे दायित्व का सामना करना पड़ता है जो GDPR का उल्लंघन करते हैं, जो प्रतिबंधात्मक नीतियों के लिए मजबूत प्रोत्साहन बनाता है।
HIPAA और स्वास्थ्य सेवा डेटा
हेल्थ इंश्योरेंस पोर्टेबिलिटी एंड अकाउंटेबिलिटी एक्ट विशिष्ट अधिकृत परिस्थितियों को छोड़कर संरक्षित स्वास्थ्य जानकारी (PHI) के प्रकटीकरण को प्रतिबंधित करता है। एक स्वास्थ्य सेवा कार्यकर्ता जो ChatGPT के साथ रोगी मामलों पर चर्चा करता है वह एक अनधिकृत प्राप्तकर्ता को PHI का खुलासा करता है।
विशिष्ट स्वास्थ्य सेवा संगठनों और OpenAI के बीच कोई बिजनेस एसोसिएट एग्रीमेंट मौजूद नहीं है। किसी भी सुरक्षा ऑडिट ने HIPAA तकनीकी सुरक्षा उपायों के साथ ChatGPT के अनुपालन को सत्यापित नहीं किया है। कोई कानूनी ढांचा प्रकटीकरण को अधिकृत नहीं करता।
स्वास्थ्य सेवा संगठन जो पाते हैं कि कर्मचारियों ने ChatGPT के माध्यम से PHI साझा किया है, उन्हें उल्लंघन अधिसूचना आवश्यकताओं, संभावित OCR जांच और प्रति वर्ष प्रति उल्लंघन श्रेणी $1.5 मिलियन तक पहुंचने वाले दंड का सामना करना पड़ता है। ये परिणाम बताते हैं कि अस्पताल सिस्टम नीति अनुपालन पर निर्भर रहने के बजाय नेटवर्क स्तर पर ChatGPT को ब्लॉक क्यों करते हैं।
वित्तीय नियम
बैंक, ब्रोकर-डीलर और निवेश सलाहकार SEC, FINRA, OCC और फेडरल रिजर्व नियमों के तहत संचालित होते हैं जो व्यावसायिक संचार की रिकॉर्डकीपिंग और पर्यवेक्षण को अनिवार्य करते हैं। जब एक विश्लेषक क्लाइंट पत्राचार का मसौदा तैयार करने के लिए ChatGPT का उपयोग करता है, तो उस बातचीत को अनुपालन अभिलेखागार में कैप्चर किया जाना चाहिए।
ChatGPT एंटरप्राइज आर्काइविंग सिस्टम के साथ कोई एकीकरण प्रदान नहीं करता। कोई पर्यवेक्षण उपकरण संभावित समस्याग्रस्त उपयोग को फ्लैग नहीं करता। बातचीत केवल OpenAI के सर्वर और कर्मचारी के डिवाइस पर मौजूद है—जिनमें से कोई भी नियामक रिकॉर्डकीपिंग आवश्यकताओं को पूरा नहीं करता।
रिकॉर्डकीपिंग से परे, वित्तीय नियामक AI-जनित निवेश सलाह, क्रेडिट निर्णयों में AI भागीदारी और AI विश्लेषण के बारे में चिंता व्यक्त करते हैं जो बाजार हेरफेर का गठन कर सकता है। नियामक परिदृश्य अनिश्चित रहता है, और अनुपालन अधिकारी स्पष्टता की प्रतीक्षा में इसे अनुमति देने के बजाय उपयोग को प्रतिबंधित करके अनिश्चितता का जवाब देते हैं।
उभरता AI-विशिष्ट विनियमन
यूरोपीय AI अधिनियम, जो 2025 और 2026 के दौरान उत्तरोत्तर प्रभावी होने की उम्मीद है, AI सिस्टम परिनियोजन पर अतिरिक्त आवश्यकताएं लगाएगा। उच्च-जोखिम AI अनुप्रयोग—जिनमें रोजगार, क्रेडिट और शिक्षा को प्रभावित करने वाले शामिल हैं—के लिए अनुरूपता आकलन, दस्तावेज़ीकरण और मानव निरीक्षण की आवश्यकता होती है।
इन संदर्भों में ChatGPT का उपयोग करने वाले संगठन पा सकते हैं कि नियम प्रभावी होने के बाद वे गैर-अनुपालन AI सिस्टम संचालित कर रहे हैं। सक्रिय उद्यम बाद में अनुपालन सुधार का सामना करने के बजाय अभी उपयोग को प्रतिबंधित कर रहे हैं।
बौद्धिक संपदा: वह जोखिम जिसे कोई अनुबंध हल नहीं करता
नियामक अनुपालन चिंता की एक श्रेणी का प्रतिनिधित्व करता है। बौद्धिक संपदा संरक्षण एक अन्य का प्रतिनिधित्व करता है—और कई उद्यमों के लिए, अधिक महत्वपूर्ण।
व्यापार रहस्य और गोपनीयता
डिफेंड ट्रेड सीक्रेट्स एक्ट और राज्य समकक्षों के तहत व्यापार रहस्य संरक्षण के लिए आवश्यक है कि जानकारी उचित सुरक्षात्मक उपायों के माध्यम से गोपनीय रहे। जब एक कर्मचारी मालिकाना एल्गोरिदम, विनिर्माण प्रक्रियाएं या रणनीतिक योजनाएं ChatGPT में पेस्ट करता है, तो संगठन के सुरक्षात्मक उपाय विफल हो गए हैं।
व्यापार रहस्य दावों का मूल्यांकन करने वाली अदालतें जांचती हैं कि क्या दावा करने वाली पार्टी ने गोपनीयता बनाए रखने के लिए उचित कदम उठाए। कर्मचारियों को तृतीय-पक्ष AI सेवाओं के साथ गोपनीय जानकारी साझा करने की अनुमति देना इस आवश्यकता को कमजोर करता है। भले ही जानकारी कभी भी OpenAI के सिस्टम से लीक न हो, प्रकटीकरण का कार्य स्वयं कानूनी सुरक्षा से समझौता कर सकता है।
यह चिंता काल्पनिक मुकदमेबाजी से परे फैली हुई है। कंपनियां नियमित रूप से जाने वाले कर्मचारियों और प्रतियोगियों के खिलाफ व्यापार रहस्य दावे करती हैं। यदि खोज से पता चलता है कि “गुप्त” जानकारी पहले ChatGPT के साथ साझा की गई थी—संभावित मॉडल प्रशिक्षण के माध्यम से लाखों उपयोगकर्ताओं के लिए सुलभ—तो दावा काफी कमजोर हो जाता है।
सोर्स कोड और तकनीकी संपत्तियां
सॉफ्टवेयर कंपनियों को विशेष जोखिम का सामना करना पड़ता है। डेवलपर्स स्वाभाविक रूप से कोड डीबग करने, बॉयलरप्लेट जनरेट करने और विकास में तेजी लाने के लिए AI टूल का उपयोग करना चाहते हैं। लेकिन सोर्स कोड एक सॉफ्टवेयर व्यवसाय की मुख्य संपत्ति का प्रतिनिधित्व करता है। एक बार ChatGPT को प्रेषित होने के बाद, वह कोड संगठनात्मक नियंत्रण के बाहर मौजूद है।
प्रशिक्षण डेटा चिंता सैद्धांतिक नहीं है। बड़े भाषा मॉडल अपने इनपुट से सीखते हैं। जबकि OpenAI बताता है कि Enterprise और API ग्राहक प्रशिक्षण योगदान से ऑप्ट आउट कर सकते हैं, उपभोक्ता उत्पाद ऐसी कोई गारंटी नहीं देता। एक डेवलपर द्वारा साझा किया गया कोड दूसरे को दिखाई गई पूर्णताओं को प्रभावित कर सकता है—संभावित रूप से एक प्रतिस्पर्धी कंपनी में।
Amazon की कर्मचारियों को आंतरिक चेतावनी ने विशेष रूप से इस जोखिम का हवाला दिया कि ChatGPT प्रतिक्रियाएं Amazon गोपनीय जानकारी से मिलती-जुलती हो सकती हैं, यह सुझाव देते हुए कि समान डेटा पहले ही मॉडल में शामिल किया जा चुका था। क्या यह प्रशिक्षण डेटा में वास्तविक Amazon कोड का प्रतिनिधित्व करता था या बस समान पैटर्न अस्पष्ट रहता है। अस्पष्टता ने ही प्रतिबंधात्मक नीति को प्रेरित किया।
क्लाइंट और ग्राहक जानकारी
पेशेवर सेवा फर्म—सलाहकार, लेखाकार, वकील, आर्किटेक्ट—क्लाइंट जानकारी के साथ काम करते हैं जो उन क्लाइंट्स की है, सेवा प्रदाता की नहीं। ChatGPT के साथ क्लाइंट डेटा साझा करना एंगेजमेंट लेटर, गोपनीयता समझौतों और पेशेवर नैतिकता नियमों का उल्लंघन कर सकता है।
एक सलाहकार जो विश्लेषण के लिए क्लाइंट की वित्तीय प्रक्षेपण ChatGPT पर अपलोड करता है, उसने उस क्लाइंट की गोपनीय जानकारी तीसरे पक्ष के साथ साझा की है। सलाहकार की फर्म को अनुबंध उल्लंघन दावों, पेशेवर अनुशासन और क्लाइंट संबंधों के नुकसान का सामना करना पड़ सकता है यदि खोजा जाता है।
ये चिंताएं ग्राहक डेटा को संभालने वाले किसी भी व्यवसाय पर समान रूप से लागू होती हैं। एक बिक्री प्रतिनिधि जो प्रतिक्रिया का मसौदा तैयार करने के लिए ChatGPT में ग्राहक पत्राचार पेस्ट करता है, उसने ग्राहक संचार OpenAI को प्रेषित किया है। उद्योग और लागू समझौतों के आधार पर, यह ग्राहक डेटा हैंडलिंग प्रतिबद्धताओं का उल्लंघन कर सकता है।

एंटरप्राइज AI समझौतों की अपर्याप्तता
OpenAI विशेष रूप से कॉर्पोरेट चिंताओं को संबोधित करने के लिए ChatGPT Enterprise प्रदान करता है। Microsoft एंटरप्राइज सुरक्षा सुविधाओं के साथ Azure OpenAI Service प्रदान करता है। ये उत्पाद उपभोक्ता प्रस्तावों पर सुधार करते हैं लेकिन उच्च-संवेदनशीलता उपयोग मामलों के लिए मौलिक चिंताओं को समाप्त नहीं करते।
एंटरप्राइज समझौते क्या प्रदान करते हैं
ChatGPT Enterprise में कई सार्थक सुधार शामिल हैं:
- डेटा का उपयोग मॉडल प्रशिक्षण के लिए नहीं किया जाता
- SOC 2 Type 2 अनुपालन प्रमाणन
- आराम और पारगमन में डेटा एन्क्रिप्शन
- SSO एकीकरण और प्रशासनिक नियंत्रण
- डेटा प्रतिधारण नियंत्रण
ये सुविधाएं कई कॉर्पोरेट उपयोग मामलों के लिए आवश्यकताओं को पूरा करती हैं। अभियान कॉपी का मसौदा तैयार करने वाली मार्केटिंग टीम न्यूनतम जोखिम का सामना करती है। प्रतिक्रिया टेम्पलेट तैयार करने वाला ग्राहक सेवा विभाग स्वीकार्य मापदंडों के भीतर संचालित होता है।
एंटरप्राइज समझौते क्या प्रदान नहीं कर सकते
विनियमित उद्योगों और संवेदनशील बौद्धिक संपदा के लिए, एंटरप्राइज समझौते मौलिक तरीकों से कम पड़ते हैं।
पहला, डेटा अभी भी उस बुनियादी ढांचे पर संसाधित होता है जिसे आप नियंत्रित नहीं करते। आपकी जानकारी OpenAI सर्वरों पर रहती है, OpenAI कर्मचारियों द्वारा प्रबंधित, OpenAI की सुरक्षा प्रथाओं के अधीन। आप उनके कार्यान्वयन पर भरोसा करते हैं। आप उनकी कार्मिक जांच पर भरोसा करते हैं। आप उनकी घटना प्रतिक्रिया पर भरोसा करते हैं। यह विश्वास उचित हो सकता है, लेकिन यह फिर भी विश्वास है—सत्यापन नहीं।
दूसरा, डेटा कानूनी प्रक्रिया के अधीन रहता है। OpenAI को दिया गया सम्मन आपकी बातचीत के प्रकटीकरण को मजबूर कर सकता है। किसी अन्य ग्राहक में सरकारी जांच संभावित रूप से साझा बुनियादी ढांचे को उजागर कर सकती है। राष्ट्रीय सुरक्षा पत्र और FISA अदालत के आदेश गोपनीयता आवश्यकताओं के तहत संचालित होते हैं जो OpenAI को आपको एक्सेस के बारे में सूचित करने से रोकेंगे।
तीसरा, हमले की सतह में पूरा OpenAI संगठन शामिल है। आपकी सुरक्षा परिधि अब आपकी नेटवर्क सीमा पर समाप्त नहीं होती। सिस्टम एक्सेस वाला हर OpenAI कर्मचारी, बुनियादी ढांचे तक पहुंच वाला हर विक्रेता, OpenAI के सिस्टम में हर सुरक्षा भेद्यता आपके जोखिम प्रोफाइल का हिस्सा बन जाती है।
चौथा, निकास और पोर्टेबिलिटी प्रतिबंधित रहती है। आपका बातचीत इतिहास, फाइन-ट्यून किए गए व्यवहार और ChatGPT में संचित संगठनात्मक ज्ञान OpenAI के सिस्टम के साथ इंटरैक्शन से संबंधित है। किसी विकल्प पर माइग्रेशन के लिए खरोंच से पुनर्निर्माण की आवश्यकता होती है।
नए यौगिकों को विकसित करने वाली एक फार्मास्युटिकल कंपनी, वर्गीकृत-समीप अनुसंधान को संभालने वाले एक रक्षा ठेकेदार, या संभावित मूल्य में अरबों का प्रतिनिधित्व करने वाले ट्रेडिंग एल्गोरिदम वाले एक वित्तीय संस्थान के लिए, ये सीमाएं मायने रखती हैं। एंटरप्राइज समझौते जोखिम को कम करते हैं। वे इसे समाप्त नहीं करते।
ओपन-वेट्स विकल्प
कॉर्पोरेट ChatGPT प्रतिबंधों को प्रेरित करने वाले प्रतिबंध सामान्य रूप से AI पर लागू नहीं होते। वे विशेष रूप से क्लाउड AI सेवाओं पर लागू होते हैं जहां डेटा संगठनात्मक नियंत्रण छोड़ता है। एक अलग आर्किटेक्चर इन चिंताओं को पूरी तरह से समाप्त करता है।
ओपन-वेट्स मॉडल क्या प्रदान करते हैं
ओपन-वेट्स मॉडल—Meta से Llama, Mistral AI से Mistral, Alibaba से Qwen और दर्जनों अन्य—डाउनलोड करने योग्य मॉडल फाइलें प्रदान करते हैं जो किसी भी संगत हार्डवेयर पर चलती हैं। मॉडल वेट सार्वजनिक हैं। इनफरेंस कोड ओपन सोर्स है। आप पूरी प्रणाली उस बुनियादी ढांचे पर निष्पादित कर सकते हैं जिसका आप स्वामित्व और संचालन करते हैं।
जब आप अपने सर्वर पर Llama चलाते हैं, तो आपके प्रॉम्प्ट कभी भी आपके नेटवर्क को नहीं छोड़ते। कोई तृतीय पक्ष आपका डेटा प्राप्त नहीं करता। कोई क्लाउड सेवा आपकी क्वेरीज़ को लॉग नहीं करती। कोई प्रशिक्षण पाइपलाइन आपके इनपुट को शामिल नहीं करती। मॉडल स्थानीय रूप से चलता है, स्थानीय रूप से प्रोसेस करता है, और आप जो स्पष्ट रूप से कॉन्फ़िगर करते हैं उससे परे कुछ भी संग्रहीत नहीं करता।
यह आर्किटेक्चर हर उस चिंता को संतुष्ट करता है जो ChatGPT प्रतिबंधों को प्रेरित करती है:
-
नियामक अनुपालन: डेटा आपकी सुरक्षा परिधि के भीतर रहता है, आपके नियंत्रणों के अधीन, आपकी नीतियों द्वारा शासित। GDPR डेटा ट्रांसफर नहीं होते क्योंकि डेटा ट्रांसफर नहीं होता। HIPAA चिंताएं समाप्त हो जाती हैं क्योंकि अनधिकृत पक्षों को कोई प्रकटीकरण नहीं होता।
-
बौद्धिक संपदा संरक्षण: व्यापार रहस्य गुप्त रहते हैं। सोर्स कोड कभी भी आपके सिस्टम को नहीं छोड़ता। क्लाइंट गोपनीयता बनी रहती है क्योंकि कोई तृतीय पक्ष क्लाइंट जानकारी प्राप्त नहीं करता।
-
सुरक्षा नियंत्रण: आपकी हमले की सतह आपकी अपनी रहती है। आप अपनी सुरक्षा प्रथाओं को सत्यापित करते हैं। आप अपने कर्मियों की जांच करते हैं। आप अपनी घटना प्रतिक्रिया को नियंत्रित करते हैं। किसी बाहरी संगठन की भेद्यताएं आपके डेटा को प्रभावित नहीं करतीं।
-
ऑडिट और अनुपालन: हर क्वेरी, हर प्रतिक्रिया, हर मॉडल इंटरैक्शन आपकी आवश्यकताओं के अनुसार लॉग किया जा सकता है। नियामक रिकॉर्डकीपिंग आपके मौजूदा आर्काइव सिस्टम के साथ एकीकृत होती है।
क्षमता तुलना
स्वाभाविक प्रश्न यह है कि क्या ओपन-वेट्स मॉडल ChatGPT की क्षमताओं से मेल खाते हैं। ईमानदार जवाब: यह उपयोग के मामले पर निर्भर करता है।
सामान्य ज्ञान क्वेरीज़ के लिए, इंटरनेट-स्केल डेटा पर ChatGPT का प्रशिक्षण एक व्यापकता प्रदान करता है जिसे छोटे ओपन मॉडल मैच नहीं कर सकते। जटिल समस्याओं पर GPT-4 की तर्क क्षमताएं Llama-3-8B की उपलब्धियों से अधिक हैं।
लेकिन एंटरप्राइज उपयोग के मामलों को शायद ही कभी इंटरनेट-स्केल ज्ञान की आवश्यकता होती है। अनुबंधों का विश्लेषण करने वाली एक कानूनी टीम को दस्तावेज़ समझ और सटीक भाषा पीढ़ी की आवश्यकता होती है—क्षमताएं जहां फाइन-ट्यून किए गए ओपन मॉडल उत्कृष्ट हैं। कोड डीबग करने वाली एक डेवलपमेंट टीम को विशिष्ट कोडबेस के भीतर पैटर्न पहचान की आवश्यकता होती है—एक कार्य जहां कस्टम प्रशिक्षण जेनेरिक मॉडल से नाटकीय रूप से बेहतर प्रदर्शन करता है।
महत्वपूर्ण अंतर्दृष्टि यह है कि फाइन-ट्यूनिंग जेनेरिक मॉडल को डोमेन विशेषज्ञों में बदल देती है। आपके संगठन के दस्तावेजों, कोडिंग मानकों और संचार पैटर्न पर फाइन-ट्यून किया गया Llama-3-8B मॉडल पूर्ण डेटा अलगाव बनाए रखते हुए आपके विशिष्ट कार्यों के लिए GPT-4 से बेहतर प्रदर्शन करेगा।
विकेंद्रीकृत GPUs पर निजी LLM फाइन-ट्यूनिंग पर हमारा पिलर गाइड इस प्रक्रिया के लिए पूर्ण तकनीकी वर्कफ़्लो प्रदान करता है।
निजी AI परिनियोजन के लिए बुनियादी ढांचा विकल्प
ओपन-वेट्स मॉडल चलाने के लिए GPU कंप्यूट की आवश्यकता होती है। संगठनों के पास इस क्षमता को प्राप्त करने के लिए कई विकल्प हैं।
ऑन-प्रिमाइसेस हार्डवेयर
आंतरिक डेटा सेंटरों के लिए NVIDIA GPUs खरीदना अधिकतम नियंत्रण प्रदान करता है। हार्डवेयर आपकी सुविधा में बैठता है, आपके स्टाफ द्वारा प्रबंधित, आपके नेटवर्क से जुड़ा। किसी बाहरी पक्ष की कोई पहुंच नहीं है।
चुनौती पूंजीगत व्यय और लीड टाइम है। एक NVIDIA H100 GPU की कीमत लगभग $30,000 है। प्रशिक्षण के लिए एक सार्थक क्लस्टर को कई इकाइयों की आवश्यकता होती है। खरीद समयसीमा महीनों तक फैली हुई है। चल रहे रखरखाव के लिए विशेष विशेषज्ञता की आवश्यकता होती है।
मौजूदा डेटा सेंटर संचालन वाले बड़े उद्यमों के लिए, ऑन-प्रिमाइसेस AI बुनियादी ढांचा एक प्राकृतिक विस्तार का प्रतिनिधित्व करता है। छोटे संगठनों या GPU विशेषज्ञता के बिना उनके लिए, बाधाएं पर्याप्त हैं।
निजी क्लाउड इंस्टेंस
AWS, GCP और Azure GPU इंस्टेंस प्रदान करते हैं जो SaaS AI उत्पादों की तुलना में अधिक नियंत्रण प्रदान करते हैं। आप वातावरण को कॉन्फ़िगर करते हैं। आप एक्सेस को नियंत्रित करते हैं। आपका डेटा साझा सेवाओं के बजाय समर्पित इंस्टेंस पर प्रोसेस होता है।
यह दृष्टिकोण ChatGPT के आर्किटेक्चर पर सुधार करता है लेकिन क्लाउड प्रदाता की भागीदारी बनाए रखता है। आपका डेटा अभी भी उस बुनियादी ढांचे पर रहता है जिसे आप भौतिक रूप से नियंत्रित नहीं करते। पर्याप्त एक्सेस वाले क्लाउड प्रदाता कर्मचारी सैद्धांतिक रूप से आपके सिस्टम तक पहुंच सकते हैं। क्लाउड प्रदाता को दी गई कानूनी प्रक्रिया आपके डेटा तक पहुंच सकती है।
इसके अतिरिक्त, निजी क्लाउड GPU इंस्टेंस महत्वपूर्ण लागत वहन करते हैं। AWS p4d.24xlarge इंस्टेंस (8x A100 GPUs) लगभग $32 प्रति घंटे चलते हैं। विस्तारित प्रशिक्षण रन या निरंतर इनफरेंस सेवाएं पर्याप्त मासिक खर्च उत्पन्न करती हैं। उपलब्धता प्रतिबंधित है—GPU इंस्टेंस अक्सर प्रतीक्षा सूची या सीमित क्षेत्रीय उपलब्धता दिखाते हैं।
विकेंद्रीकृत GPU किराये
एक तीसरा विकल्प पूंजीगत व्यय और क्लाउड प्रदाता भागीदारी दोनों को बायपास करता है। विकेंद्रीकृत GPU मार्केटप्लेस उपयोगकर्ताओं को सीधे हार्डवेयर मालिकों से जोड़ते हैं। आप पीयर-टू-पीयर कंप्यूट क्षमता किराए पर लेते हैं, क्रिप्टोकरेंसी से भुगतान करते हैं, बिना पहचान सत्यापन या क्लाउड प्रदाता मध्यस्थता के।
यह मॉडल गोपनीयता-सचेत संगठनों के लिए कई फायदे प्रदान करता है:
-
कोई KYC आवश्यकताएं नहीं: आप एक वॉलेट कनेक्ट करते हैं और हार्डवेयर किराए पर लेते हैं। कोई कॉर्पोरेट अकाउंट नहीं। कोई एंटरप्राइज सेल्स प्रोसेस नहीं। कोई पहचान दस्तावेज़ नहीं जो आपके संगठन को विशिष्ट AI गतिविधियों से जोड़ता है।
-
कोई क्लाउड प्रदाता भागीदारी नहीं: आपका डेटा व्यक्तियों के स्वामित्व वाले हार्डवेयर पर प्रोसेस होता है, कानूनी विभागों, सरकारी अनुबंधों और कानून प्रवर्तन संबंधों वाले निगमों द्वारा नहीं।
-
लागत दक्षता: RTX 4090 किराये $0.40 से $0.60 प्रति घंटे चलते हैं, तुलनीय क्लाउड इंस्टेंस की लागत का लगभग दसवां हिस्सा। हमारी GPU किराया मूल्य तुलना अर्थशास्त्र का विवरण देती है।
-
वैश्विक उपलब्धता: विकेंद्रीकृत आपूर्ति का मतलब है कोई क्षेत्रीय बाधाएं नहीं। हार्डवेयर तब उपलब्ध है जब आपको इसकी आवश्यकता होती है, दुनिया भर के अधिकार क्षेत्रों में वितरित।
उन संगठनों के लिए जो GPU हार्डवेयर पर पूंजीगत व्यय को उचित नहीं ठहरा सकते लेकिन क्लाउड प्रदाताओं की पेशकश से अधिक मजबूत गोपनीयता गारंटी की आवश्यकता है, विकेंद्रीकृत किराये एक व्यावहारिक मध्य मार्ग प्रदान करते हैं।
वर्कफ़्लो में एन्क्रिप्टेड SSH कनेक्शन के माध्यम से सीधे किराये के नोड पर अपना डेटा ट्रांसफर करना, अपना प्रशिक्षण या इनफरेंस जॉब चलाना, परिणाम डाउनलोड करना और डिस्कनेक्ट करने से पहले रिमोट वातावरण को सैनिटाइज़ करना शामिल है। सार्वजनिक GPU नोड पर अपने डेटासेट को सुरक्षित करने पर हमारा गाइड परिचालन सुरक्षा प्रथाओं को विस्तार से कवर करता है।

रणनीतिक अनिवार्यता
जो संगठन AI नीति को केवल जोखिम शमन के नजरिए से देखते हैं, वे बड़ी तस्वीर से चूक जाते हैं। आज ChatGPT पर प्रतिबंध लगाने वाले उद्यम AI को नहीं छोड़ रहे हैं। वे स्थायी लाभ के लिए पुनर्स्थापित हो रहे हैं।
डेटा के माध्यम से प्रतिस्पर्धी भेदभाव
सबसे मूल्यवान AI क्षमताएं मालिकाना डेटा से उभरती हैं। इंटरनेट टेक्स्ट पर प्रशिक्षित एक जेनेरिक भाषा मॉडल सभी के लिए उपलब्ध जेनेरिक क्षमताएं प्रदान करता है। आपके ग्राहक इंटरैक्शन, आपके परिचालन डेटा और आपके संस्थागत ज्ञान पर फाइन-ट्यून किया गया मॉडल आपके संगठन के लिए अद्वितीय क्षमताएं प्रदान करता है।
इस भेदभाव के लिए मालिकाना डेटा को मालिकाना रखना आवश्यक है। जो संगठन अपने प्रतिस्पर्धी लाभों को क्लाउड AI सेवाओं में फीड करते हैं, वे उन मॉडलों में योगदान करते हैं जो सभी उपयोगकर्ताओं को लाभ पहुंचाते हैं—प्रतियोगियों सहित। जो संगठन निजी AI परिनियोजित करते हुए डेटा नियंत्रण बनाए रखते हैं, वे ऐसे लाभ जमा करते हैं जो समय के साथ संयुक्त होते हैं।
नियामक प्रक्षेपवक्र
AI विनियमन कड़ा हो रहा है, ढीला नहीं। EU AI अधिनियम मिसाल स्थापित करता है जिसका अन्य अधिकार क्षेत्र पालन करेंगे। FTC, SEC और बैंकिंग नियामकों सहित अमेरिकी एजेंसियां AI-विशिष्ट मार्गदर्शन विकसित कर रही हैं। चीन ने मॉडल प्रशिक्षण और परिनियोजन को प्रभावित करने वाले AI नियम लागू किए हैं।
अभी निजी AI बुनियादी ढांचा बनाने वाले संगठन उन नियामक वातावरणों के लिए तैयारी कर रहे हैं जो क्लाउड AI उपयोग को तेजी से प्रतिबंधित करेंगे। अनुपालन आर्किटेक्चर में निवेश अधिक मूल्यवान हो जाता है जैसे-जैसे अनुपालन आवश्यकताएं तीव्र होती हैं।
आपूर्ति श्रृंखला विचार
एकल AI प्रदाता पर निर्भरता रणनीतिक भेद्यता पैदा करती है। OpenAI की कीमतें, नीतियां और क्षमताएं उनके विवेकानुसार बदलती हैं। सेवा व्यवधान सभी ग्राहकों को एक साथ प्रभावित करते हैं। नीति परिवर्तन रातोंरात पहले स्वीकार्य उपयोग के मामलों को प्रतिबंधित कर सकते हैं।
निजी AI परिनियोजन एकल-विक्रेता निर्भरता को समाप्त करता है। ओपन-वेट्स मॉडल डाउनलोड करने योग्य और स्थायी रूप से उपलब्ध हैं। परिनियोजन के लिए कई हार्डवेयर विकल्प मौजूद हैं। संगठन बाहरी निर्णयों पर निर्भर होने के बजाय अपनी AI आपूर्ति श्रृंखला को नियंत्रित करता है।
कार्यान्वयन रोडमैप
ChatGPT प्रतिबंधों से परे निजी AI क्षमता की ओर बढ़ने के लिए तैयार संगठनों के लिए, हम एक चरणबद्ध दृष्टिकोण की सिफारिश करते हैं।
तत्काल कार्रवाइयां (सप्ताह 1-2)
- पूरे संगठन में वर्तमान AI उपयोग का ऑडिट
- संवेदनशीलता और नियामक आवश्यकताओं के आधार पर डेटा प्रकारों का वर्गीकरण
- दस्तावेज़ करें कि किन उपयोग के मामलों के लिए निजी बुनियादी ढांचे की आवश्यकता है बनाम स्वीकार्य क्लाउड उपयोग
- निषिद्ध और अनुमत गतिविधियों को स्पष्ट करने वाली अंतरिम नीति स्थापित करें
अल्पकालिक विकास (माह 1-3)
- संवेदनशीलता आवश्यकताओं और बजट के आधार पर बुनियादी ढांचा विकल्पों का मूल्यांकन
- निजी AI परिनियोजन के लिए प्रारंभिक उपयोग के मामलों का चयन
- मॉडल अनुकूलन के लिए प्रशिक्षण डेटा स्रोतों की पहचान
- यदि लागू हो तो बाहरी GPU उपयोग के लिए सुरक्षा प्रोटोकॉल स्थापित करें
मध्यम अवधि परिनियोजन (माह 3-6)
- हमारी तकनीकी गाइड का पालन करते हुए संगठनात्मक डेटा पर मॉडल फाइन-ट्यून करें
- उचित एक्सेस नियंत्रणों के साथ इनफरेंस बुनियादी ढांचा परिनियोजित करें
- मौजूदा अनुपालन और ऑडिट सिस्टम के साथ एकीकृत करें
- स्वीकृत वर्कफ़्लो और टूल पर उपयोगकर्ताओं को प्रशिक्षित करें
चल रहे संचालन
- नए प्रशिक्षण डेटा को शामिल करते हुए नियमित मॉडल अपडेट
- AI बुनियादी ढांचे का सुरक्षा मूल्यांकन
- नियामक परिवर्तनों को दर्शाती नीति अपडेट
- अतिरिक्त उपयोग के मामलों में क्षमता विस्तार
निष्कर्ष
ChatGPT पर कॉर्पोरेट प्रतिबंध तर्कसंगत जोखिम प्रबंधन को दर्शाते हैं, तकनीकी भय नहीं। जब Samsung ने टूल पर प्रतिबंध लगाया जब पता चला कि मालिकाना सेमीकंडक्टर डिज़ाइन अपलोड किए गए थे, तो उन्होंने सही निर्णय लिया। जब JPMorgan ने सक्रिय रूप से एक्सेस प्रतिबंधित किया, तो उन्होंने उचित नियामक जागरूकता का प्रदर्शन किया। जब स्वास्थ्य सेवा प्रणालियां फ़ायरवॉल स्तर पर एक्सेस ब्लॉक करती हैं, तो वे कानून द्वारा आवश्यक रोगी गोपनीयता की रक्षा करती हैं।
लेकिन निषेध रणनीति नहीं है। जो संगठन “नहीं” पर रुक जाते हैं, वे उत्पादकता लाभ छोड़ देते हैं जो उनके प्रतियोगी हासिल करेंगे। जो उद्यम फलेंगे-फूलेंगे वे वो होंगे जो पहचानते हैं कि एक तीसरा रास्ता मौजूद है।
निजी बुनियादी ढांचे पर चलने वाले ओपन-वेट्स मॉडल डेटा एक्सपोजर के बिना AI क्षमता प्रदान करते हैं। मॉडल अभी उपलब्ध हैं। बुनियादी ढांचा सुलभ है। तकनीकी वर्कफ़्लो प्रलेखित हैं। एकमात्र बाधा कार्यान्वयन के लिए संगठनात्मक इच्छाशक्ति है।
आपके प्रतियोगी जो अपने मालिकाना डेटा पर मॉडल फाइन-ट्यून कर रहे हैं—ऐसे सिस्टम प्रशिक्षित कर रहे हैं जो उनके ग्राहकों, उनके उत्पादों और उनके संचालन को समझते हैं—ऐसे लाभ बना रहे हैं जिन्हें आप एक जेनेरिक सेवा की सदस्यता लेकर दोहरा नहीं सकते। जब आप नीति पर बहस कर रहे हैं, वे क्षमता परिनियोजित कर रहे हैं।
आज आप जो बुनियादी ढांचा निर्णय लेते हैं वह निर्धारित करता है कि AI आपका प्रतिस्पर्धी लाभ बनता है या आपके प्रतियोगियों का आप पर लाभ। क्लाउड AI सेवाएं आपके डेटा को साझा संसाधनों में बदल देती हैं। निजी AI परिनियोजन आपके डेटा को अद्वितीय क्षमता में बदल देता है।
विकल्प यह नहीं है कि AI का उपयोग करना है या नहीं। विकल्प यह है कि इसे नियंत्रित करना है या नहीं।
संबंधित संसाधन
यह लेख एंटरप्राइज AI निर्णयों के लिए रणनीतिक और नियामक संदर्भ को संबोधित करता है। निम्नलिखित संसाधन तकनीकी कार्यान्वयन मार्गदर्शन प्रदान करते हैं:
कोर कार्यान्वयन गाइड
- विकेंद्रीकृत GPUs पर निजी LLM फाइन-ट्यूनिंग की अंतिम गाइड — कस्टम मॉडल प्रशिक्षण के लिए पूर्ण तकनीकी वर्कफ़्लो
सुरक्षा और संचालन
- सार्वजनिक GPU नोड पर अपने डेटासेट को कैसे सुरक्षित करें — विकेंद्रीकृत कंप्यूट के लिए परिचालन सुरक्षा प्रथाएं
- KYC के बिना GPU कैसे किराए पर लें — गोपनीयता-संवेदनशील परिनियोजनों के लिए अनाम किराया वर्कफ़्लो
प्लेटफ़ॉर्म और अर्थशास्त्र
- GPU किराया मूल्य तुलना 2026 — परिनियोजन विकल्पों में लागत विश्लेषण
- स्मार्ट कॉन्ट्रैक्ट एस्क्रो समझाया गया — विकेंद्रीकृत भुगतान दोनों पक्षों की रक्षा कैसे करते हैं
- GPU किराये के लिए भुगतान करने का सबसे स्मार्ट तरीका स्टेबलकॉइन हैं — विकेंद्रीकृत बुनियादी ढांचे के लिए भुगतान तंत्र
तकनीकी तुलनाएं
- Ollama vs vLLM vs TGI: कंज्यूमर GPUs पर इनफरेंस स्पीड का बेंचमार्किंग — परिनियोजन के लिए इनफरेंस सर्वर चयन
- RunPod vs Vast.ai तुलना — GPU किराये के लिए मार्केटप्लेस मूल्यांकन