
本記事を読んでいるということは、OpenAIにアップロードできない、あるいはアップロードしたくないデータセットをお持ちである可能性が高いでしょう。
それは珍しいことではありません。多くの企業や独立系開発者にとって、ChatGPTの利便性は、データ漏洩という受け入れがたいリスクの前では二の次になります。HIPAAの対象となる医療記録、長年のエンジニアリング投資の成果であるプロプライエタリなコードベース、市場に影響を与え得る機密性の高い金融モデルなどを扱う場合、クラウドAIの利用は自社の最も重要な知的財産を第三者に委ねることを意味します。
その第三者が、過去に顧客データを将来のモデル学習に活用してきた実績を持つ巨大テクノロジー企業である場合、「信頼」という言葉は容易には使えません。
解決策はAIを放棄することではありません。解決策はインフラを自ら保有することです。
オープンウェイトモデルを自ら管理するハードウェア上でfine-tuningすることは、もはや一部の研究者だけの取り組みではありません。プライバシーを重視する組織にとっては、実務上の要件です。Llama、Mistral、Qwenをはじめとする多数のモデルは、API料金やデータ共有義務なしで商用利用が可能です。課題は常に計算資源へのアクセスでした。NVIDIA H100クラスターの購入には多額の資本投資が必要です。AWSからのレンタルは本人確認や企業契約を伴い、長時間のトレーニング実行には高額な時間単価が発生します。
本ガイドでは第三の選択肢を提示します。分散型GPUレンタルを利用し、オープンウェイト言語モデルをfine-tuningする方法を解説します。これは、世界中の個人が所有するハードウェアをpeer‑to‑peerマーケットプレイス経由で利用する仕組みです。本記事では、環境構築、公開ノード上での運用におけるセキュリティ対策、そしてトレーニング実行までを網羅します。
コード例ではLlama‑3.1‑8Bを具体例として使用しますが、ワークフローはHugging Face互換の任意のモデルに適用可能です。モデル識別子を変更するだけで、Mistral‑7BやQwen2‑7Bなど、用途に適したオープンウェイトモデルをfine-tuningできます。
これらはすべて、KYCなし、長期契約なし、そして従来のクラウドプロバイダーよりも大幅に低コストで実現可能です。
プライベートFine-Tuningの経済性
技術的な実装に入る前に、まずコスト構造を確認しておきましょう。
AWSでモデルをトレーニングする場合、インスタンスの確保自体が課題になります。p4d.24xlarge(A100 GPU ×8)は1時間あたり32.77ドルで、入手できる場合に限られます。Lambda Labsは比較的低価格ですが、数週間に及ぶ待機リストが発生することもあります。いずれもクレジットカード登録、本人確認、詳細な請求記録を伴い、AI関連の活動が法的身元と結び付けられます。
分散型マーケットプレイスでは、ハードウェア所有者から直接計算資源を借り受けます。これはブロックチェーンベースの決済基盤上で動作するpeer‑to‑peerインフラです。その意味は明確です。
コスト削減: 多くの分散型プラットフォームでは、RTX 4090は1時間あたり0.40〜0.60ドルでレンタル可能です。QLoRAを使用した8Bパラメータモデルであれば、24GB VRAMを搭載した単一の4090で2〜6時間程度でfine-tuningを完了できます。総計算コストは3〜8ドル程度です。
アーキテクチャによるプライバシー: 支払いはPolygonなどのネットワーク上でのstablecoin決済によって行われます。クレジットカードで本人情報が紐付けられることはありません。マーケットプレイスのスマートコントラクトがエスクローを管理し、その仕組みはスマートコントラクトエスクローの解説で詳述しています。
承認不要: クラウドプロバイダーの営業承認は不要です。ワークロードの監査権を含む利用規約に同意する必要もありません。ウォレットを接続し、ハードウェアを借りるだけです。
比較として、AWSのA10Gインスタンス(必要十分なVRAMを持つ最も安価な選択肢)は1時間あたり約1.50ドルです。環境構築中のアイドル時間や匿名決済不可という点を考慮すると、実質コストは150〜300ドルに達します。同等の処理が分散型インフラでは10ドル未満で実行可能です。
詳細はGPUレンタル価格比較2026で確認できます。
前提条件
本チュートリアルはLinuxコマンドラインの基本操作に慣れていることを前提としています。機械学習の学位は不要ですが、ファイルシステムの操作、テキストファイル編集、エラーメッセージの理解ができる必要があります。
ハードウェア要件:
- GPU: 最低24GB VRAM。RTX 3090、RTX 4090、A10Gが該当します。70Bモデルの場合は48GB以上(A6000、デュアルA100、H100など)が必要です。
- システムRAM: 32GB以上。モデル読み込み時に重みは一時的にシステムメモリに配置されます。
- ストレージ: NVMe SSD 100GB以上。Llama‑3 8Bのベース重みは約16GBを使用します。データセットやチェックポイントでさらに容量が必要になります。
モデル選択について: 本ガイドではMeta Llama‑3.1‑8Bを使用します。これはQLoRA量子化を用いた場合、24GB GPUに収まる最大クラスのモデルであるためです。Llama 4 ScoutやMaverickは109Bおよび400BパラメータのMixture of Experts構成であり、単一ノードレンタルの範囲を超えるマルチGPU構成が必要です。本ワークフローは、Mistral‑7B、Qwen2‑7B、Gemma‑2‑9Bなど、VRAM制約内に収まる任意のHugging Face互換モデルに適用可能です。
ソフトウェア要件:
- Python 3.10以上
- PyTorchの基本的な理解
- Hugging Faceアカウント(Llamaなどのライセンス承認が必要なモデルをダウンロードするため)
- Polygonネットワーク上でUSDCまたはMATICを保有する暗号資産ウォレット(MetaMaskなど)
分散型GPUレンタル用のウォレット設定がまだの場合は、先にMetaMaskとPolygonのセットアップガイドを完了してください。所要時間は約15分です。
ステップ1: 計算ノードの確保と安全対策
最初のステップはハードウェアの確保です。中央集権型クラウドでは、アカウント作成、本人確認書類の提出、承認待ち、支払い方法の登録といった手順が必要になります。分散型マーケットプレイスでは、手続きはより直接的です。
GPUFlowマーケットプレイスにアクセスし、右上のボタンからウォレットを接続します。利用可能なマシンの仕様、時間単価、信頼性スコアが表示されます。
以下の条件でフィルタリングしてください。
- GPU: RTX 4090(24GB VRAM)またはRTX 6000 Ada(48GB VRAM)
- RAM: 32GB以上
- ストレージ: 100GB以上の空き
- 信頼性: 稼働率95%以上
ノードを選択し、レンタルを開始します。スマートコントラクトは推定使用時間をカバーするデポジットを要求します。このエスクローの仕組みについてはスマートコントラクトエスクローの解説をご参照ください。
公開ノード利用時のセキュリティ注意点:
レンタルマシンは物理的に第三者が管理しています。仮想化により分離は確保されていますが、以下の対策を徹底してください。
- 秘密鍵を保存しない。 暗号資産ウォレット、他システム用のSSH鍵、プロダクションAPIトークンは保存しないでください。
- ファイルシステムを信頼しない。 ディスク上のデータは理論上復元可能です。後述のステップ6で安全な削除方法を説明します。
- 転送時は暗号化する。 詳細はステップ3で説明します。
- パスワードを使い回さない。 デフォルト認証情報が提供された場合は即時変更するか、新しいSSH鍵を生成してください。
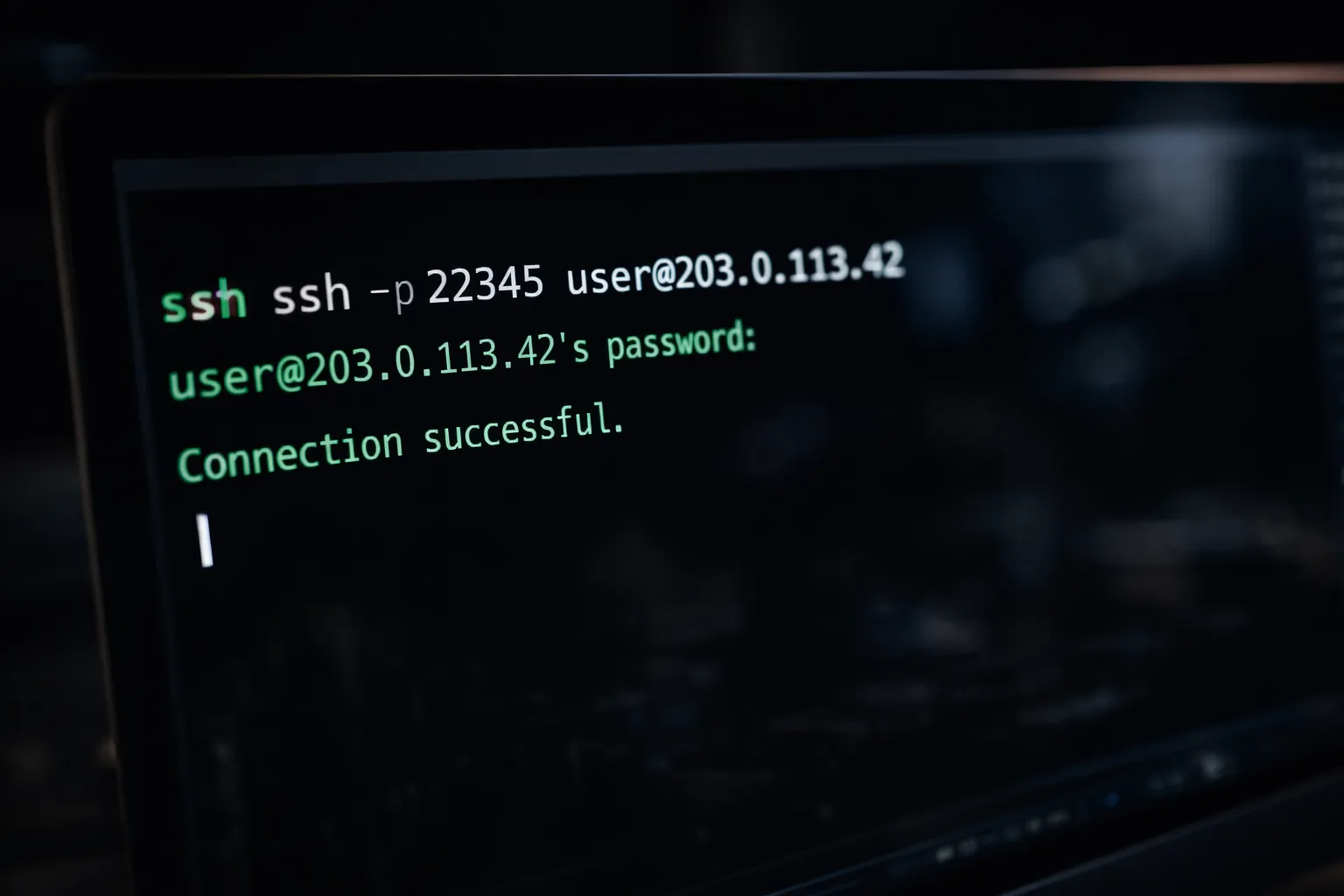
レンタル確定後、SSH接続情報が表示されます。例:
ssh -p 22345 [email protected]ローカル端末から実行し、ホストキーを承認してください。
ハードウェア確認:
nvidia-smiGPUモデル、VRAM容量、ドライバーバージョンを確認してください。仕様が一致しない場合は直ちに切断し、マーケットプレイスに報告してください。
ステップ2: 環境構築
クリーンなPython環境を作成します。システムパッケージへの依存は避けてください。
mkdir ~/llama3-finetune
cd ~/llama3-finetune
python3 -m venv venv
source venv/bin/activateCUDA確認:
nvcc --version必要に応じて:
source /etc/profile.d/cuda.shCUDA 12.1の場合のPyTorchインストール例:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121必要ライブラリのインストール:
pip install transformers==4.40.0 datasets==2.19.0 peft==0.10.0 bitsandbytes==0.43.1 trl==0.8.6 accelerate==0.29.0バージョン固定は重要です。
Hugging Face認証:
huggingface-cli loginトークンは ~/.cache/huggingface/token に保存されます。

ステップ3: 安全なデータ転送
クラウドストレージを介さず、SSH経由で直接転送します。
ローカル端末で:
scp -P 22345 /path/to/your/dataset.jsonl [email protected]:~/llama3-finetune/大容量データの場合:
gzip -k dataset.jsonl
scp -P 22345 dataset.jsonl.gz [email protected]:~/llama3-finetune/
gunzip dataset.jsonl.gz追加暗号化例:
age -p dataset.jsonl > dataset.jsonl.age
scp -P 22345 dataset.jsonl.age [email protected]:~/llama3-finetune/
age -d dataset.jsonl.age > dataset.jsonl
rm dataset.jsonl.ageSSHはAES‑256暗号化を使用しています。
ステップ4: Fine-Tuningスクリプト
JSONL形式:
- 1行につき1JSONオブジェクト
- 改行は
\n - 引用符は
\" - UTF‑8エンコード
スクリプト作成:
cd ~/llama3-finetune
nano train.py元の英語版と同じコードを貼り付けてください。
実行:
python train.py初回実行時に約16GBのベースモデルがダウンロードされ、その後トレーニングが開始されます。
ステップ5: トレーニングの監視
トレーニング実行中はGPUの状態を監視してください。VRAMが上限に達したり、温度が安全域を超えたりすると、プロセスが停止する可能性があります。レンタル時間を無駄にしないためにも、定期的な確認は不可欠です。
ローカル端末から別のSSHセッションを開きます。
ssh -p 22345 [email protected]リアルタイム監視:
watch -n 1 nvidia-smi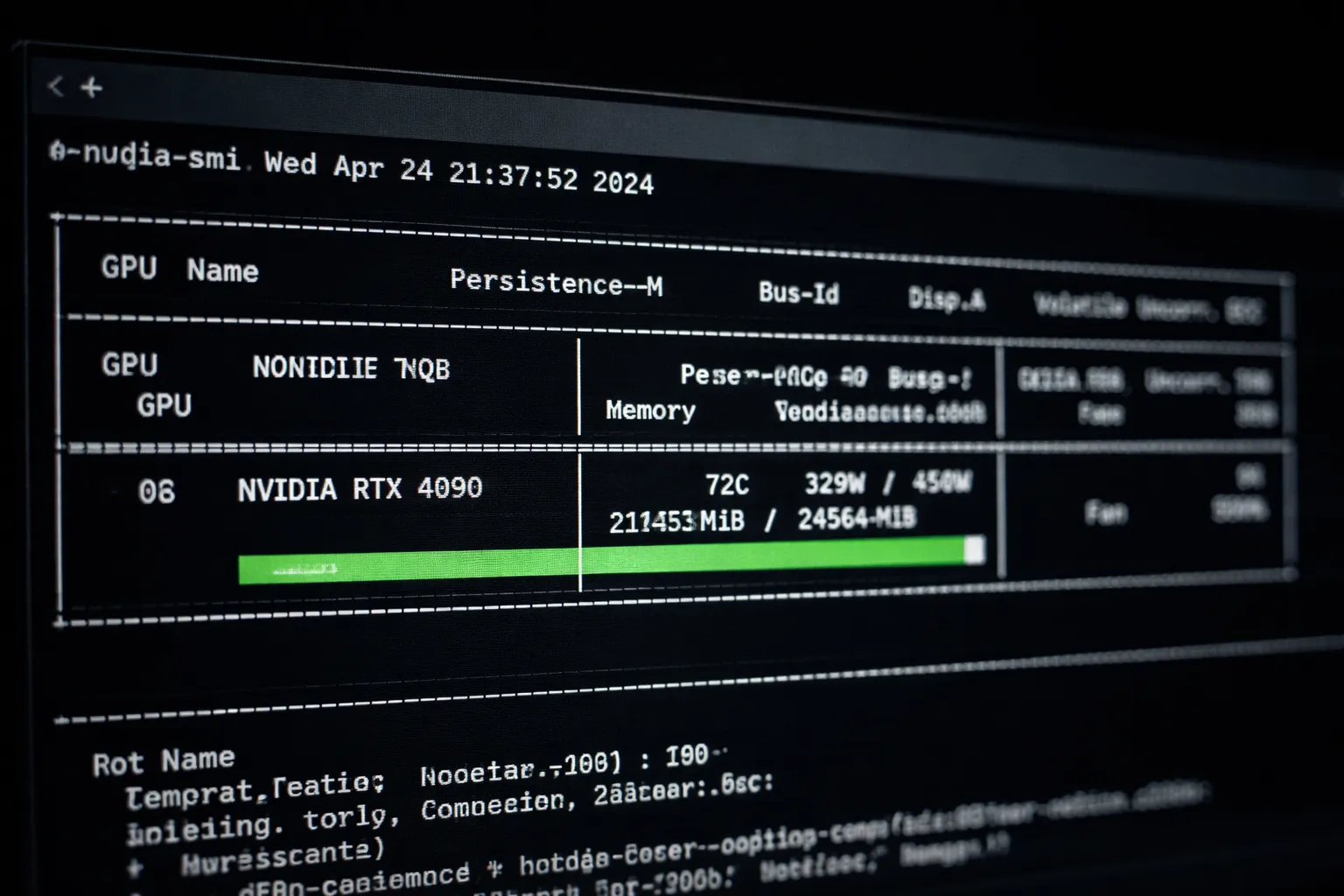
RTX 4090で本ガイドの設定を使用した場合の目安:
- メモリ使用量: 18GB〜22GB(24GB中)
- GPU使用率: 90%〜100%
- 温度: 60°C〜80°C
問題への対処:
- VRAMが上限に近い場合 →
BATCH_SIZEを2または1に変更 - 温度が85°Cを超える場合 → ノード変更を検討
- Lossが減少しない場合 → learning rate調整
1,000サンプルのトレーニングは約30〜60分、10,000サンプルでは5〜10時間が目安です。
ステップ6: モデル取得と環境のサニタイズ
トレーニング完了後、LoRAアダプターは指定ディレクトリに保存されます。
確認:
ls -la ~/llama3-finetune/llama-3-8b-custom/ダウンロード:
scp -r -P 22345 [email protected]:~/llama3-finetune/llama-3-8b-custom ./その後、必ずリモート環境を削除してください。
rm -rf ~/llama3-finetune
rm -rf ~/.cache/huggingface
rm -rf ~/.cache/pip
history -c
cat /dev/null > ~/.bash_history
syncより厳密な削除:
find ~/llama3-finetune -type f -exec shred -u {} \;
rm -rf ~/llama3-finetuneレンタルを正式に終了してください。
Inference実行例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
quantization_config=bnb_config,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, "./llama-3-8b-custom")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
prompt = "### Instruction: 契約条項を要約してください。\n\n### Input: The Licensee shall not reverse engineer, decompile, or disassemble the Software.\n\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)本番環境ではFastAPIやvLLMなどを活用してください。
結論
あなたは、第三者にデータを渡すことなく、最先端のLLMをfine-tuningしました。KYCも契約も不要です。
コストは数ドル程度。AWSでは数百ドル規模になる可能性があります。
しかし重要なのはコストではなく、制御権です。データもモデルも、あなたの管理下にあります。