
Se você está lendo isto, é provável que possua um dataset que não pode — ou não deseja — enviar para a OpenAI.
Você não está sozinho. Para muitas empresas e desenvolvedores independentes, a conveniência do ChatGPT é superada pelo risco inaceitável de vazamento de dados. Seja ao lidar com registros médicos sujeitos à HIPAA, bases de código proprietárias que representam anos de investimento em engenharia ou modelos financeiros sensíveis capazes de impactar mercados, utilizar IA em nuvem frequentemente significa confiar sua propriedade intelectual mais valiosa a um terceiro.
Quando esse terceiro é um conglomerado tecnológico com histórico de uso de dados de clientes para treinar modelos futuros, a palavra “confiança” deixa de ser confortável.
A solução não é abandonar a IA. A solução é possuir a infraestrutura.
Realizar fine-tuning de modelos com pesos abertos em hardware sob seu controle não é mais uma prática acadêmica de nicho. É uma exigência operacional para organizações que levam privacidade a sério. Modelos como Llama, Mistral, Qwen e diversos outros estão disponíveis para uso comercial sem taxas de API e sem obrigação de compartilhamento de dados. O desafio sempre foi o acesso a poder computacional. A aquisição de clusters NVIDIA H100 exige investimentos de milhões. O aluguel na AWS requer verificação de identidade, contratos corporativos e tarifas por hora que tornam execuções prolongadas economicamente inviáveis.
Este guia apresenta um terceiro caminho. Você aprenderá como realizar fine-tuning de um modelo de linguagem com pesos abertos utilizando GPUs descentralizadas — hardware pertencente a indivíduos ao redor do mundo, acessível por meio de um marketplace peer‑to‑peer. Abordaremos configuração de ambiente, protocolos de segurança para operar em nós públicos e a execução completa do treinamento.
Os exemplos utilizam Llama‑3.1‑8B como referência prática, mas o fluxo de trabalho se aplica igualmente a qualquer modelo compatível com Hugging Face. Basta alterar o identificador do modelo para ajustar Mistral‑7B, Qwen2‑7B ou qualquer outro modelo open‑weights adequado ao seu caso de uso.
Tudo isso sem KYC, sem contratos de longo prazo e por uma fração do custo cobrado por provedores tradicionais de nuvem.
A Economia do Fine-Tuning Privado
Antes de examinar a implementação técnica, é necessário estabelecer o contexto financeiro.
Treinar um modelo na AWS envolve lidar com escassez de instâncias. A instância p4d.24xlarge (8 GPUs A100) custa US$ 32,77 por hora — quando disponível. A Lambda Labs oferece preços mais competitivos, mas frequentemente mantém listas de espera que se estendem por semanas. Ambos exigem cartão de crédito, verificação de identidade e geram registros detalhados que vinculam suas atividades de IA à sua identidade legal.
Em um marketplace descentralizado, você aluga poder computacional diretamente de proprietários de hardware. Trata‑se de infraestrutura peer‑to‑peer operando sobre trilhos de pagamento baseados em blockchain. As implicações são claras:
Redução de custos: Uma RTX 4090 geralmente custa entre US$ 0,40 e US$ 0,60 por hora em plataformas descentralizadas. Para modelos de 8B parâmetros utilizando QLoRA, uma única 4090 com 24GB de VRAM conclui o fine‑tuning em duas a seis horas, dependendo do tamanho do dataset. O custo total de computação varia entre três e oito dólares.
Privacidade por arquitetura: Pagamentos são realizados por meio de stablecoins em redes como Polygon. Não há cartão de crédito vinculando sua identidade à locação. O smart contract do marketplace gerencia o escrow, conforme detalhado em nossa documentação sobre smart contract escrow, garantindo proteção para ambas as partes.
Sem intermediários: Não é necessário obter aprovação de equipes comerciais corporativas. Você não assina políticas de uso que concedem ao provedor direito de inspecionar seus workloads. Basta conectar sua carteira e alugar hardware.
Para comparação, o mesmo fluxo na AWS utilizando uma instância A10G (a opção mais econômica com VRAM suficiente) custa aproximadamente US$ 1,50 por hora. Considerando tempo de configuração, computação ociosa e impossibilidade de pagamento anônimo, o custo real pode chegar a US$ 150–300 para o que pode ser realizado por menos de dez dólares em infraestrutura descentralizada.
Uma análise detalhada está disponível em nosso comparativo de preços de GPU 2026.
Pré-Requisitos
Este tutorial pressupõe familiaridade com a linha de comando Linux. Não é necessário um diploma em machine learning, mas você deve estar confortável navegando pelo sistema de arquivos, editando arquivos de texto e interpretando mensagens de erro.
Requisitos de Hardware:
- GPU: mínimo de 24GB de VRAM. RTX 3090, RTX 4090 e A10G são adequadas. Para o modelo de 70B parâmetros, são necessários 48GB ou mais (A6000, A100 duplas ou H100).
- Memória RAM: 32GB ou superior. O carregamento do modelo utiliza memória do sistema antes da transferência para a GPU.
- Armazenamento: 100GB ou mais em SSD NVMe. Os pesos base do Llama‑3 8B ocupam aproximadamente 16GB. Dataset, checkpoints e adaptadores adicionam espaço adicional.
Nota sobre seleção de modelo: Este guia utiliza Meta Llama‑3.1‑8B como exemplo por representar a maior classe de modelo que cabe confortavelmente em uma GPU de 24GB com quantização QLoRA. A família Llama inclui Llama 4 Scout e Maverick, mas estes utilizam arquitetura Mixture of Experts com 109B e 400B parâmetros, exigindo configurações multi‑GPU além do escopo de um único nó alugado. O fluxo descrito aqui aplica‑se igualmente a Mistral‑7B, Qwen2‑7B, Gemma‑2‑9B e outros modelos compatíveis com Hugging Face que se ajustem aos limites de VRAM do hardware alugado.
Requisitos de Software:
- Python 3.10 ou superior
- Conhecimento básico de PyTorch
- Conta no Hugging Face (necessária para baixar modelos com acesso restrito, como Llama, que exigem aceitação de licença)
- Carteira de criptomoeda (MetaMask ou equivalente) com USDC ou MATIC na rede Polygon
Se você ainda não configurou uma carteira para aluguel de GPU descentralizada, conclua nosso guia de configuração do MetaMask e Polygon para aluguel de GPU antes de prosseguir. O processo leva aproximadamente quinze minutos.
Etapa 1: Protegendo seu Nó de Computação
O primeiro passo é adquirir hardware. Em plataformas de nuvem centralizadas, isso envolve criar uma conta, enviar documentos de identidade, aguardar aprovação e adicionar um método de pagamento. Aqui, o processo é significativamente mais direto.
Acesse o marketplace da GPUFlow. Conecte sua carteira utilizando o botão no canto superior direito. A interface exibirá as máquinas disponíveis com suas especificações, tarifas por hora e índices de confiabilidade.
Filtre pelas seguintes características:
- GPU: RTX 4090 (24GB VRAM) ou RTX 6000 Ada (48GB VRAM)
- RAM: mínimo de 32GB
- Armazenamento: 100GB ou mais disponíveis
- Confiabilidade: 95% ou superior
Selecione um nó e inicie o aluguel. O smart contract solicitará um depósito cobrindo o uso estimado. Você pode revisar como esse mecanismo protege ambas as partes em nossa explicação sobre smart contract escrow.
Considerações de segurança ao utilizar nós públicos:
Ao alugar uma máquina em uma rede remota, você está acessando hardware fisicamente controlado por terceiros. Embora a virtualização forneça isolamento significativo, é necessário adotar boas práticas operacionais:
-
Não armazene chaves privadas no nó remoto. Sua carteira, chaves SSH de outros sistemas e tokens de API de produção não devem existir em uma máquina alugada.
-
Considere o sistema de arquivos como potencialmente não confiável. Em teoria, arquivos gravados em disco podem ser recuperados após o término do contrato. Abordaremos exclusão segura na Etapa 6.
-
Criptografe dados sensíveis durante a transferência. Isso será tratado na Etapa 3.
-
Não reutilize senhas. Caso o sistema forneça credenciais padrão, altere-as imediatamente ou gere um novo par de chaves SSH.
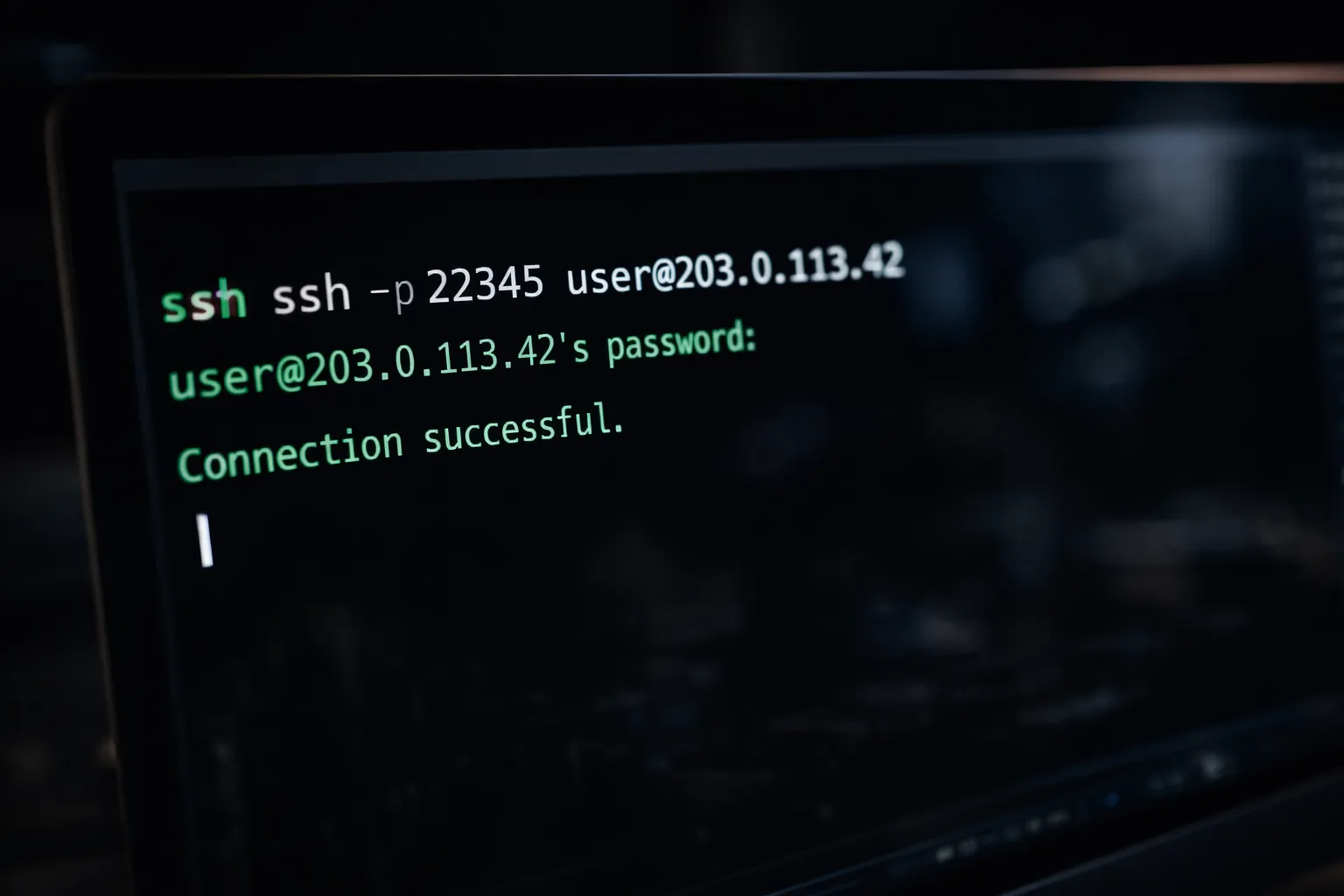
Após confirmar o aluguel, o painel fornecerá os detalhes de conexão. Você receberá um comando semelhante a:
ssh -p 22345 [email protected]Abra seu terminal local e execute o comando. Aceite a impressão digital do host quando solicitado. Agora você está conectado ao nó de GPU alugado.
Verifique se o hardware corresponde ao solicitado:
nvidia-smiA saída deve exibir o modelo da GPU, a capacidade de memória e a versão do driver. Caso haja discrepâncias, desconecte-se imediatamente e reporte o problema pelo sistema da plataforma.
Etapa 2: Configuração do Ambiente
Com a conexão estabelecida, a próxima prioridade é criar um ambiente Python isolado. A maioria dos nós já inclui drivers NVIDIA e CUDA, mas depender de pacotes do sistema pode gerar conflitos de dependência.
Crie um ambiente virtual:
mkdir ~/llama3-finetune
cd ~/llama3-finetune
python3 -m venv venv
source venv/bin/activateO prompt deverá exibir (venv).
Verifique a versão do CUDA:
nvcc --versionAnote a versão (geralmente 11.8 ou 12.1). Se necessário:
source /etc/profile.d/cuda.shInstale o PyTorch compatível com sua versão de CUDA. Exemplo para CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Instale as bibliotecas necessárias para o fine-tuning eficiente:
pip install transformers==4.40.0 datasets==2.19.0 peft==0.10.0 bitsandbytes==0.43.1 trl==0.8.6 accelerate==0.29.0Fixar versões é essencial. O ecossistema Hugging Face evolui rapidamente, e instalações sem controle de versão frequentemente resultam em incompatibilidades.
Autentique-se no Hugging Face. Os pesos do Llama‑3 exigem aceitação de licença. Acesse Hugging Face, aceite os termos do modelo e gere um token de acesso.
huggingface-cli loginCole o token quando solicitado. Ele será armazenado em ~/.cache/huggingface/token.

Etapa 3: Transferência Segura de Dados
Este é o principal motivo para utilizar computação descentralizada: soberania de dados.
O fluxo tradicional de nuvem envolve enviar o dataset para serviços como S3 ou Google Drive antes de transferi-lo para a instância de computação. Isso cria múltiplas cópias do seu conteúdo sensível.
Utilizaremos transferência criptografada direta via SSH.
Abra um novo terminal em sua máquina local (mantendo a sessão SSH aberta) e execute:
scp -P 22345 /caminho/para/seu/dataset.jsonl [email protected]:~/llama3-finetune/Observe que o parâmetro -P utiliza P maiúsculo.
Para datasets maiores que 1GB:
# Na máquina local
gzip -k dataset.jsonl
scp -P 22345 dataset.jsonl.gz [email protected]:~/llama3-finetune/
# No nó remoto
cd ~/llama3-finetune
gunzip dataset.jsonl.gzSe desejar uma camada adicional de segurança, utilize criptografia com age:
# Local
age -p dataset.jsonl > dataset.jsonl.age
scp -P 22345 dataset.jsonl.age [email protected]:~/llama3-finetune/
# Remoto
age -d dataset.jsonl.age > dataset.jsonl
rm dataset.jsonl.ageO protocolo SSH utiliza criptografia AES‑256, suficiente para a maioria dos cenários operacionais.
Etapa 4: O Script de Fine-Tuning
Utilizaremos a classe SFTTrainer da biblioteca TRL para realizar fine-tuning supervisionado.
Formato do Dataset:
O script espera um arquivo JSONL onde cada linha contenha um objeto JSON com o campo text.
Requisitos críticos:
- Cada objeto JSON deve estar em uma única linha.
- Quebras de linha internas devem ser escapadas como
\n. - Aspas internas devem ser escapadas como
\". - O arquivo deve estar em UTF‑8.
Caso seus dados estejam em CSV ou outro formato, converta-os antes da transferência.
Crie o script no nó remoto:
cd ~/llama3-finetune
nano train.pyCole o código completo fornecido na versão original. Ajuste apenas o identificador do modelo se necessário.
Execute o treinamento:
python train.pyNa primeira execução, os pesos do modelo (aproximadamente 16GB) serão baixados. Em execuções subsequentes, o cache será reutilizado. Durante o treinamento, valores de loss serão exibidos periodicamente.
Etapa 5: Monitorando o Treinamento
Enquanto o script estiver em execução, é fundamental monitorar o estado da GPU. Se a VRAM atingir o limite ou se a temperatura ultrapassar níveis seguros, o processo pode falhar — potencialmente corrompendo checkpoints e desperdiçando tempo de aluguel.
Abra um segundo terminal local e estabeleça outra conexão SSH com o nó:
ssh -p 22345 [email protected]Execute o seguinte comando para visualizar estatísticas em tempo real:
watch -n 1 nvidia-smi
Esse comando atualiza a cada segundo e mostra:
- Uso de memória
- Percentual de utilização da GPU
- Temperatura
Em uma RTX 4090 com a configuração descrita neste guia, você deve observar:
- Uso de memória: entre 18GB e 22GB (de 24GB disponíveis)
- Utilização da GPU: 90% a 100% durante etapas ativas
- Temperatura: entre 60°C e 80°C, dependendo da refrigeração do host
Soluções para problemas comuns:
Memória próxima de 24GB: reduza o BATCH_SIZE para 2 ou 1. Alternativamente, reduza o MAX_SEQ_LENGTH para 256. Reinicie o treinamento após alterar os parâmetros.
Utilização da GPU próxima de 0%: pode indicar gargalo no carregamento de dados. Em casos extremos, considere pré-processar o dataset para um formato mais eficiente.
Temperatura acima de 85°C: encerre o aluguel e selecione outro nó com melhor ventilação.
Interpretação do loss:
O valor de loss representa o erro do modelo — quanto menor, melhor.
Normalmente você verá:
- Loss inicial: entre 1.5 e 3.0
- Tendência: queda gradual nas primeiras centenas de passos
- Loss final: entre 0.5 e 1.5 em execuções bem configuradas
Se o loss não diminuir após 100 passos, o learning rate pode estar baixo demais. Se oscilar excessivamente ou aumentar abruptamente, pode estar alto demais.
Um treinamento com 1.000 exemplos geralmente leva entre 30 e 60 minutos em uma RTX 4090. Um dataset com 10.000 exemplos pode levar de 5 a 10 horas, aproximadamente de forma linear.
Etapa 6: Recuperando o Modelo e Sanitizando o Ambiente
Após a conclusão do treinamento, seu adapter LoRA estará salvo no diretório especificado por OUTPUT_NAME. O adapter é relativamente compacto (100MB a 500MB), em comparação com o modelo base completo.
Verifique os arquivos:
ls -la ~/llama3-finetune/llama-3-8b-custom/Você deverá ver arquivos como adapter_config.json, adapter_model.safetensors e arquivos do tokenizer.
Baixe o adapter para sua máquina local:
scp -r -P 22345 [email protected]:~/llama3-finetune/llama-3-8b-custom ./Confirme que os tamanhos dos arquivos correspondem.
Agora, limpe o ambiente remoto.
No nó alugado, execute:
rm -rf ~/llama3-finetune
rm -rf ~/.cache/huggingface
rm -rf ~/.cache/pip
history -c
cat /dev/null > ~/.bash_history
syncPara exclusão mais rigorosa com shred:
find ~/llama3-finetune -type f -exec shred -u {} \;
rm -rf ~/llama3-finetuneEncerre a sessão SSH:
exitFinalize formalmente o aluguel no painel da GPUFlow. O smart contract devolverá qualquer saldo restante do depósito para sua carteira.
Executando Inference com o Modelo Ajustado
Exemplo mínimo:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
quantization_config=bnb_config,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, "./llama-3-8b-custom")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
prompt = "### Instruction: Resuma a cláusula contratual.\n\n### Input: The Licensee shall not reverse engineer, decompile, or disassemble the Software.\n\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)Para uso em produção, considere expor o modelo via FastAPI ou Flask, ou utilizar servidores de inferência como vLLM ou Text Generation Inference (TGI).
Conclusão
Você realizou fine-tuning de um Large Language Model de última geração utilizando dados proprietários, sem expor essas informações a terceiros. Sem contratos corporativos. Sem verificação de identidade. Sem dependência de APIs proprietárias.
Considerando um treinamento de duas horas em uma RTX 4090 a US$ 0,45 por hora, o custo total foi inferior a um dólar. O mesmo processo na AWS poderia custar entre US$ 100 e US$ 200, considerando tempo de configuração e encargos adicionais.
Mais importante que o custo é o controle. Nenhum provedor central registra sua execução de treinamento vinculada à sua identidade. Nenhuma política de uso concede acesso aos seus dados.
A dependência de APIs fechadas está diminuindo. Organizações que exigem privacidade, pesquisadores que valorizam soberania e desenvolvedores que rejeitam vigilância agora possuem uma alternativa viável.
Seu modelo ajustado está sob sua própria infraestrutura. As decisões sobre implantação, acesso e finalidade pertencem exclusivamente a você.
O Que Ler a Seguir
Custos e Pagamentos:
- GPU Rental Pricing Comparison 2026
- Stablecoins Are the Smartest Way to Pay for GPU Rental
- How to Rent a GPU Without KYC
Mecânica da Plataforma:
- Setting Up MetaMask for Polygon GPU Rental
- Smart Contract Escrow Explained
- Hidden Fees in GPU Rental
Comparação: