
Если вы читаете это руководство, вероятно, у вас есть датасет, который вы не можете — или не готовы — загружать в OpenAI.
Вы не одиноки. Для многих компаний и независимых разработчиков удобство ChatGPT уступает риску утечки данных, который невозможно считать приемлемым. Будь то медицинские записи, подпадающие под требования HIPAA, проприетарные кодовые базы, представляющие годы инженерных инвестиций, или чувствительные финансовые модели, способные повлиять на рынки, использование облачного ИИ часто означает передачу самой ценной интеллектуальной собственности третьей стороне.
Когда этой стороной является технологическая корпорация с историей использования клиентских данных для обучения будущих моделей, слово «доверие» становится проблематичным.
Решение не в том, чтобы отказаться от ИИ. Решение — контролировать инфраструктуру.
Fine-tuning моделей с открытыми весами на оборудовании под вашим контролем больше не является академической нишей. Это практическая необходимость для организаций, ориентированных на приватность. Модели вроде Llama, Mistral, Qwen и десятков других доступны для коммерческого использования без API‑платежей и без требований к передаче данных. Проблемой всегда оставался доступ к вычислительным ресурсам. Покупка кластеров NVIDIA H100 требует многомиллионных инвестиций. Аренда в AWS предполагает верификацию личности, корпоративные соглашения и почасовые ставки, делающие длительные обучения экономически нецелесообразными.
Это руководство предлагает третий путь. Вы узнаете, как выполнять fine‑tuning языковой модели с открытыми весами, используя аренду децентрализованных GPU — оборудование, принадлежащее частным владельцам по всему миру и доступное через peer‑to‑peer маркетплейс. Мы рассмотрим настройку окружения, протоколы безопасности при работе на публичных узлах и полный цикл выполнения обучения.
В примерах используется Llama‑3.1‑8B как конкретный рабочий ориентир, однако описанный процесс применим к любой модели, совместимой с Hugging Face. Достаточно заменить идентификатор модели, чтобы выполнить fine‑tuning Mistral‑7B, Qwen2‑7B или другой open‑weights модели, соответствующей вашим задачам.
Все это возможно без KYC, без долгосрочных контрактов и по стоимости, в разы ниже традиционных облачных провайдеров.
Экономика приватного Fine-Tuning
Прежде чем переходить к технической реализации, необходимо определить финансовый контекст.
Обучение модели в AWS связано с дефицитом подходящих инстансов. Инстанс p4d.24xlarge (8×A100) стоит 32,77 доллара в час — при условии, что его вообще удаётся получить. Lambda Labs предлагает более выгодные тарифы, но часто с листами ожидания на недели. Обе платформы требуют кредитную карту, подтверждение личности и формируют детализированные отчёты о расходах, связывающие вашу деятельность в области ИИ с юридической идентичностью.
В децентрализованном маркетплейсе вы арендуете вычислительные мощности напрямую у владельцев оборудования. Это peer‑to‑peer инфраструктура, работающая на блокчейн‑платежах. Последствия очевидны:
Снижение затрат: RTX 4090 обычно стоит от 0,40 до 0,60 доллара в час на большинстве децентрализованных платформ. Для моделей с 8B параметрами и использованием QLoRA одной 4090 с 24GB VRAM достаточно, чтобы завершить fine‑tuning за 2–6 часов. Общая стоимость вычислений составляет от трёх до восьми долларов.
Приватность по архитектуре: Оплата производится через stablecoin‑транзакции в сетях вроде Polygon. Кредитная карта не связывает аренду с вашей личностью. Смарт‑контракт маркетплейса управляет escrow, как подробно описано в нашем объяснении смарт‑контрактного escrow, гарантируя защиту обеих сторон.
Отсутствие посредников: Вам не требуется одобрение корпоративного отдела продаж. Вы не подписываете политики использования, позволяющие провайдеру проверять ваши рабочие нагрузки. Вы подключаете кошелёк и арендуете оборудование.
Для сравнения: аналогичный процесс fine‑tuning в AWS с использованием одного A10G инстанса (самый доступный вариант с достаточным объёмом VRAM) стоит около 1,50 доллара в час. С учётом времени настройки, простаивающих вычислений и невозможности анонимной оплаты реальная стоимость может достигать 150–300 долларов — за то, что в децентрализованной среде обходится менее чем в десять долларов.
Подробное сравнение приведено в нашем сравнении цен на аренду GPU 2026.
Предварительные требования
Данное руководство предполагает уверенное владение командной строкой Linux. Степень в области машинного обучения не требуется, но вы должны свободно ориентироваться в файловой системе, редактировать текстовые файлы и интерпретировать сообщения об ошибках.
Требования к оборудованию:
- GPU: минимум 24GB VRAM. Подходят RTX 3090, RTX 4090 или A10G. Для модели с 70B параметрами потребуется 48GB и более (A6000, пара A100 или H100).
- Оперативная память: 32GB или выше. При загрузке модели веса временно размещаются в системной памяти.
- Хранилище: не менее 100GB NVMe SSD. Базовые веса Llama‑3 8B занимают около 16GB. Датасет, чекпойнты и итоговый адаптер потребуют дополнительного места.
Примечание о выборе модели: В данном руководстве используется Meta Llama‑3.1‑8B, поскольку это крупнейший класс модели, помещающийся в 24GB GPU при использовании QLoRA‑квантования. Llama 4 Scout и Maverick основаны на архитектуре Mixture of Experts с 109B и 400B параметрами соответственно и требуют мульти‑GPU конфигураций, выходящих за рамки аренды одного узла. Описанный здесь процесс применим к Mistral‑7B, Qwen2‑7B, Gemma‑2‑9B и другим моделям, совместимым с Hugging Face, если они соответствуют ограничениям VRAM арендованного оборудования.
Требования к программному обеспечению:
- Python 3.10 или новее
- Базовое понимание PyTorch
- Аккаунт Hugging Face (необходим для загрузки моделей с ограниченным доступом, таких как Llama, требующих принятия лицензии)
- Криптовалютный кошелёк (MetaMask или аналогичный) с USDC или MATIC в сети Polygon
Если вы ещё не настроили кошелёк для аренды децентрализованных GPU, сначала выполните наш гайд по настройке MetaMask и Polygon для аренды GPU. Процесс занимает около пятнадцати минут.
Шаг 1: Обеспечение безопасности вычислительного узла
Первый шаг — получение оборудования. В централизованных облачных платформах это означает создание аккаунта, загрузку документов для подтверждения личности, ожидание одобрения и добавление способа оплаты. Здесь процесс значительно проще.
Перейдите на маркетплейс GPUFlow. Подключите кошелёк с помощью кнопки в правом верхнем углу. Интерфейс отобразит доступные машины с характеристиками, почасовой ставкой и показателем надёжности.
Отфильтруйте по следующим параметрам:
- GPU: RTX 4090 (24GB VRAM) или RTX 6000 Ada (48GB VRAM)
- RAM: минимум 32GB
- Хранилище: 100GB или больше доступного пространства
- Надёжность: показатель аптайма 95% и выше
Выберите узел и начните аренду. Смарт‑контракт запросит депозит, покрывающий предполагаемое использование. Механизм escrow подробно объяснён в нашем объяснении смарт‑контрактного escrow.
Соображения безопасности при работе с публичными узлами:
При аренде удалённой машины вы работаете на оборудовании, физически контролируемом третьим лицом. Виртуализация обеспечивает изоляцию, однако необходимо соблюдать осторожность:
-
Не храните приватные ключи на удалённой машине. Ваш криптокошелёк, SSH‑ключи других систем и API‑токены продакшн‑сред не должны находиться на арендованном узле.
-
Считайте файловую систему потенциально небезопасной. Теоретически данные на диске могут быть восстановлены после завершения аренды. В шаге 6 описана процедура безопасного удаления.
-
Шифруйте чувствительные данные при передаче. Это рассматривается в шаге 3.
-
Не используйте повторно пароли. Если предоставлены стандартные учётные данные, немедленно замените их или создайте новую пару SSH‑ключей.
После подтверждения аренды вы получите данные для подключения. Команда SSH будет выглядеть примерно так:
ssh -p 22345 [email protected]Откройте локальный терминал и выполните эту команду. Подтвердите отпечаток ключа хоста при запросе. Теперь вы подключены к арендованному GPU‑узлу.
Проверьте соответствие оборудования:
nvidia-smiВывод должен содержать модель GPU, объём памяти и версию драйвера. Если параметры не соответствуют заказу, немедленно отключитесь и сообщите о проблеме через систему разрешения споров маркетплейса.
Шаг 2: Настройка окружения
После установления SSH‑соединения следующим шагом является создание изолированного Python‑окружения. Хотя большинство узлов уже содержат драйверы NVIDIA и CUDA, использование системных пакетов Python может привести к конфликтам зависимостей.
Создайте виртуальное окружение:
mkdir ~/llama3-finetune
cd ~/llama3-finetune
python3 -m venv venv
source venv/bin/activateВ приглашении командной строки должно появиться (venv).
Проверьте версию CUDA:
nvcc --versionЗапишите номер версии (обычно 11.8 или 12.1). Если nvcc недоступен:
source /etc/profile.d/cuda.shУстановите PyTorch, соответствующий версии CUDA. Пример для CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Затем установите необходимые библиотеки для эффективного fine‑tuning:
pip install transformers==4.40.0 datasets==2.19.0 peft==0.10.0 bitsandbytes==0.43.1 trl==0.8.6 accelerate==0.29.0Фиксация версий критически важна. Экосистема Hugging Face активно развивается, и установка без указания версий часто приводит к несовместимости.
Авторизуйтесь в Hugging Face. Веса Llama‑3 доступны только после принятия лицензии. Перейдите на Hugging Face, примите условия лицензии и создайте токен доступа.
huggingface-cli loginВставьте токен при запросе. Он будет сохранён в ~/.cache/huggingface/token.

Шаг 3: Безопасная передача данных
Основная причина аренды децентрализованных вычислительных ресурсов — суверенитет данных.
Стандартный облачный процесс предполагает загрузку датасета в S3, Google Cloud Storage или Azure Blob, а затем скачивание его на вычислительный инстанс. Это создаёт несколько копий чувствительной информации.
Мы полностью обойдём этот этап, используя прямую зашифрованную передачу.
Откройте новое окно терминала на локальном компьютере (не закрывая активную SSH‑сессию) и выполните:
scp -P 22345 /path/to/your/dataset.jsonl [email protected]:~/llama3-finetune/Флаг -P (с заглавной буквы) указывает номер порта.
Для датасетов объёмом более 1GB рекомендуется предварительное сжатие:
# На локальной машине
gzip -k dataset.jsonl
scp -P 22345 dataset.jsonl.gz [email protected]:~/llama3-finetune/
# На удалённом узле
cd ~/llama3-finetune
gunzip dataset.jsonl.gzДля дополнительной защиты можно зашифровать файл с помощью age:
# На локальной машине
age -p dataset.jsonl > dataset.jsonl.age
scp -P 22345 dataset.jsonl.age [email protected]:~/llama3-finetune/
# На удалённом узле
age -d dataset.jsonl.age > dataset.jsonl
rm dataset.jsonl.ageПротокол SSH использует шифрование AES‑256, чего достаточно для большинства практических задач.
Шаг 4: Скрипт Fine-Tuning
Для выполнения supervised fine‑tuning используется класс SFTTrainer из библиотеки TRL.
Требования к формату датасета:
Скрипт ожидает файл JSONL, где каждая строка содержит JSON‑объект с полем text.
Критически важно:
- Каждый JSON‑объект должен быть на одной строке.
- Переводы строк внутри поля
textдолжны быть экранированы как\n. - Кавычки внутри текста должны быть экранированы как
\". - Файл должен быть в кодировке UTF‑8.
Если исходные данные находятся в формате CSV или другом формате, их необходимо предварительно преобразовать.
Создайте файл скрипта на удалённом узле:
cd ~/llama3-finetune
nano train.pyВставьте полный код обучения из оригинальной версии, изменяя только идентификатор модели при необходимости.
Запустите обучение:
python train.pyПри первом запуске будет загружена базовая модель (около 16GB для модели 8B). В дальнейшем веса будут использоваться из кэша. Во время обучения вы будете видеть значения loss через заданные интервалы.
Шаг 5: Мониторинг процесса обучения
Во время выполнения скрипта необходимо контролировать состояние GPU. Если VRAM будет полностью заполнена или температура превысит безопасные значения, процесс может завершиться с ошибкой — что приведёт к потере времени аренды и возможной порче чекпойнтов.
Откройте второе окно терминала на локальной машине и установите дополнительное SSH‑соединение с тем же узлом:
ssh -p 22345 [email protected]Для мониторинга в реальном времени выполните:
watch -n 1 nvidia-smi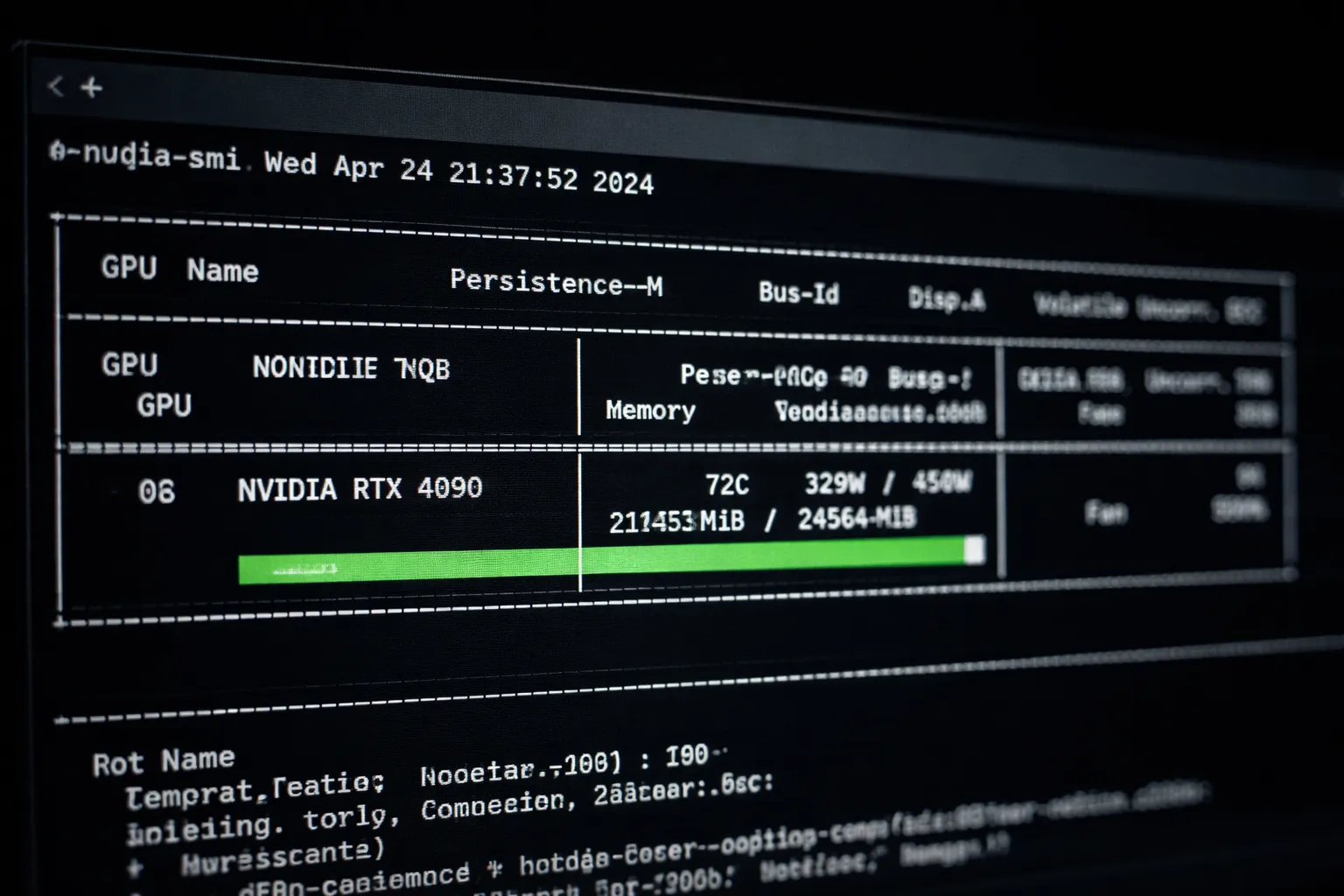
Команда обновляется каждую секунду и отображает:
- Использование памяти
- Процент загрузки GPU
- Температуру
Для RTX 4090 с конфигурацией, описанной в этом руководстве, ожидаемые показатели:
- Использование памяти: 18–22GB из доступных 24GB
- Загрузка GPU: 90–100% во время активных шагов обучения
- Температура: 60–80°C в зависимости от системы охлаждения
Типичные проблемы и решения:
Память приближается к 24GB: уменьшите BATCH_SIZE до 2 или 1. Альтернативно снизьте MAX_SEQ_LENGTH до 256. После изменения перезапустите обучение.
Загрузка GPU близка к 0%: возможно узкое место при загрузке данных. В этом случае рассмотрите предварительную обработку датасета в более эффективный формат.
Температура выше 85°C: при длительном перегреве возможен троттлинг. В таком случае разумно завершить аренду и выбрать другой узел.
Интерпретация значения loss:
Loss отражает степень ошибки модели — чем ниже, тем лучше.
Обычно наблюдается:
- Начальный loss: 1.5–3.0
- Тенденция: постепенное снижение
- Финальный loss: 0.5–1.5 при корректной конфигурации
Если loss не уменьшается после примерно 100 шагов, вероятно, learning rate слишком низкий. Если loss резко возрастает (например, выше 10), возможно, learning rate слишком высокий или датасет содержит ошибки форматирования.
Обучение на 1 000 примерах обычно занимает 30–60 минут на RTX 4090. Для 10 000 примеров потребуется 5–10 часов, масштабирование примерно линейное.
Шаг 6: Получение модели и очистка среды
После завершения обучения LoRA‑адаптер будет сохранён в директории, указанной в OUTPUT_NAME. Обычно его размер составляет от 100MB до 500MB, что значительно меньше базовой модели.
Проверьте наличие файлов:
ls -la ~/llama3-finetune/llama-3-8b-custom/Вы должны увидеть файлы adapter_config.json, adapter_model.safetensors и связанные файлы токенизатора.
Скачайте адаптер на локальную машину:
scp -r -P 22345 [email protected]:~/llama3-finetune/llama-3-8b-custom ./Убедитесь, что размеры файлов совпадают.
Не объединяйте адаптер с базовой моделью на арендованном узле. Операция merge требует загрузки полной модели в 16‑битном формате, что может превысить доступную VRAM. Выполняйте merge на собственной инфраструктуре или используйте адаптер совместно с базовой моделью при инференсе.
Теперь необходимо полностью очистить удалённую среду.
В SSH‑сессии выполните:
rm -rf ~/llama3-finetune
rm -rf ~/.cache/huggingface
rm -rf ~/.cache/pip
history -c
cat /dev/null > ~/.bash_history
syncДля более тщательного удаления при наличии shred:
find ~/llama3-finetune -type f -exec shred -u {} \;
rm -rf ~/llama3-finetuneЗатем завершите SSH‑соединение:
exitВ панели GPUFlow завершите аренду. Смарт‑контракт автоматически вернёт оставшуюся часть депозита на ваш кошелёк за вычетом фактически использованного времени.
Запуск инференса с вашей fine-tuned моделью
Минимальный пример:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
quantization_config=bnb_config,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, "./llama-3-8b-custom")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
prompt = "### Instruction: Суммируйте договорное положение.\n\n### Input: The Licensee shall not reverse engineer, decompile, or disassemble the Software.\n\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)Для продакшн‑развёртывания рассмотрите использование FastAPI, Flask или серверов инференса, таких как vLLM или Text Generation Inference (TGI).
Заключение
Вы выполнили fine‑tuning современного Large Language Model на собственных данных, не передавая их третьим сторонам. Без корпоративных контрактов. Без верификации личности. Без зависимости от закрытых API.
Если обучение заняло два часа на RTX 4090 по цене 0,45 доллара в час, общая стоимость составила менее одного доллара. Эквивалентный процесс в AWS мог бы обойтись в 100–200 долларов с учётом настройки и простоев.
Однако ключевое преимущество — не только в стоимости, а в контроле. Ни одна корпорация не связывает вашу активность обучения с вашей личностью. Ни одни условия использования не предоставляют провайдеру доступ к вашему датасету.
Эпоха зависимости от закрытых API постепенно уходит. Организации, которым важна приватность, исследователи, ценящие суверенитет, и разработчики, не принимающие тотальный контроль, получают альтернативу.
Ваша fine‑tuned модель теперь находится на инфраструктуре под вашим контролем. Решения о её развёртывании, доступе и назначении принимаете только вы.
Что читать далее
Стоимость и оплата:
- GPU Rental Pricing Comparison 2026
- Stablecoins Are the Smartest Way to Pay for GPU Rental
- How to Rent a GPU Without KYC
Механика платформы:
- Setting Up MetaMask for Polygon GPU Rental
- Smart Contract Escrow Explained
- Hidden Fees in GPU Rental
Сравнение: