RunPod vs Vast.ai : Comparaison Complète pour les Développeurs IA
Choisir entre RunPod et Vast.ai représente l’une des décisions les plus courantes auxquelles font face les développeurs IA qui ont besoin d’un accès GPU sans les prix du cloud d’entreprise. Les deux plateformes occupent le terrain intermédiaire entre les hyperscalers coûteux et la possession directe de matériel, mais elles abordent le problème de manière suffisamment différente pour que le bon choix dépende fortement de vos circonstances spécifiques.
Cette comparaison examine les deux plateformes à travers les dimensions qui comptent réellement pour la location pratique de GPU : structures de prix, caractéristiques de fiabilité, ensembles de fonctionnalités et les flux de travail que chaque plateforme gère le mieux. J’ai utilisé les deux plateformes de manière extensive pour les charges de travail d’entraînement et d’inférence, et cette analyse reflète cette expérience pratique combinée avec les données actuelles du marché.
La version courte : Vast.ai gagne sur le prix, RunPod gagne sur la commodité et la fiabilité. La version longue nécessite de comprendre les compromis impliqués dans les décisions architecturales de chaque plateforme.
Ce que couvre ce guide :
- Comparaison détaillée des prix avec des calculs de coûts réels
- Analyse de fiabilité basée sur l’architecture de la plateforme et les métriques rapportées par les utilisateurs
- Décomposition fonctionnalité par fonctionnalité des deux plateformes
- Recommandations spécifiques pour différents types de charge de travail
- Conseils pratiques pour commencer avec chaque plateforme
Table des Matières
- Vue d’Ensemble de la Plateforme
- Comparaison des Prix
- Fiabilité et Temps de Disponibilité
- Matériel Disponible
- Expérience Utilisateur et Interface
- Modèles et Environnements Préconfigurés
- Stockage et Transfert de Données
- Options de Paiement
- Support et Documentation
- Considérations de Sécurité
- Comparaison de Performance Réelle
- Meilleurs Cas d’Usage pour Chaque Plateforme
- Considérations de Migration
- Alternatives à Considérer
- Questions Fréquemment Posées
- Recommandations Finales
Vue d’Ensemble de la Plateforme
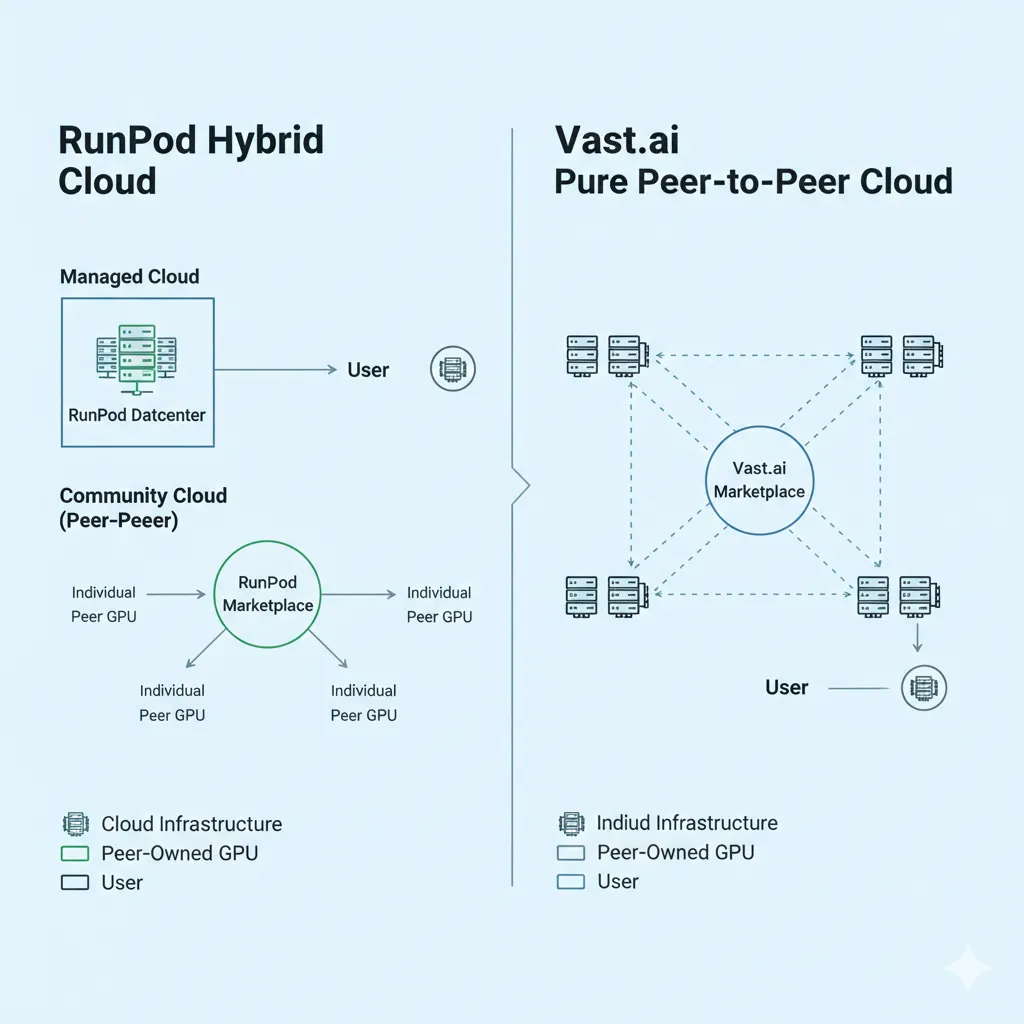
RunPod : Le Marché Géré
RunPod a été lancé en 2022 avec un accent sur la rendre la location de GPU accessible aux développeurs individuels et aux petites équipes. La plateforme fonctionne sur un modèle hybride : un niveau “Secure Cloud” avec du matériel dans des centres de données gérés, et un niveau “Community Cloud” qui agrège les GPU de fournisseurs individuels de manière similaire au modèle de Vast.ai.
L’entreprise a levé des fonds de capital-risque et maintient une équipe d’ingénierie et de support à temps plein. Ce soutien institutionnel se traduit par une expérience utilisateur plus raffinée, des modèles officiels et un service client réactif—des luxes que les plateformes peer-to-peer pures ne peuvent pas facilement fournir.
Le positionnement de RunPod met l’accent sur la facilité d’utilisation. La plateforme cible les utilisateurs qui souhaitent déployer des charges de travail GPU rapidement sans expertise approfondie en infrastructure. Les modèles en un clic pour Stable Diffusion WebUI, les serveurs d’inférence de génération de texte et les notebooks Jupyter réduisent le temps de configuration de quelques heures à quelques minutes.
Caractéristiques clés de RunPod :
- Modèle hybride combinant centre de données géré et GPU communautaires
- Prix fixes et prévisibles sur le niveau Secure Cloud
- Modèles préconstruits étendus pour les charges de travail IA courantes
- Facturation à la seconde élimine le gaspillage d’utilisation partielle par heure
- Communauté Discord active avec support officiel réactif
- Option GPU serverless pour les charges de travail d’inférence
Vast.ai : Le Marché Pur
Vast.ai a été pionnier du modèle de location de GPU peer-to-peer lors de son lancement en 2019. La plateforme connecte les propriétaires individuels de GPU—des amateurs avec des rigs de gaming aux opérateurs gérant de petits centres de données privés—directement avec les utilisateurs qui ont besoin de ressources de calcul.
Cette approche de marché pur produit les prix les plus bas de l’industrie. Sans frais généraux de centre de données ni coûts d’infrastructure gérée, les propriétaires de GPU peuvent louer du matériel de manière rentable à des tarifs qui sous-cotent toutes les autres options. Le compromis est la variabilité : différents fournisseurs offrent différents niveaux de fiabilité, de performance réseau et de qualité matérielle.
Vast.ai attire les utilisateurs soucieux des coûts qui sont à l’aise pour évaluer les fournisseurs individuels en fonction des scores de fiabilité, de l’emplacement géographique et des spécifications matérielles. La plateforme fournit des métriques détaillées pour chaque annonce, permettant des décisions éclairées sur les compromis prix-fiabilité.
Caractéristiques clés de Vast.ai :
- Marché peer-to-peer pur sans infrastructure gérée
- Prix de type enchère basé sur l’offre et la demande
- Prix absolus les plus bas du marché de location de GPU
- Métriques détaillées de fiabilité et notes des fournisseurs
- Large sélection de matériel incluant les GPU grand public les plus récents
- Nécessite plus de sophistication de l’utilisateur pour naviguer efficacement
Comparaison des Prix
Les prix représentent le facteur de différenciation le plus important entre ces plateformes. Les deux sont considérablement moins chères que les clouds d’entreprise, mais l’écart entre elles est significatif pour les projets à budget limité.
Prix des GPU Grand Public
Les GPU grand public comme RTX 4090 et RTX 3090 offrent le meilleur rapport prix-performance pour la plupart des charges de travail IA. Ni AWS, Azure ni GCP n’offrent ces GPU—un avantage majeur pour RunPod et Vast.ai.
| GPU | RunPod Secure Cloud | RunPod Community | Plage Vast.ai | Moyenne Vast.ai |
|---|---|---|---|---|
| RTX 5090 (32GB) | 0,89 $/h | 0,55-0,85 $/h | 0,38-1,08 $/h | 0,65 $/h |
| RTX 4090 (24GB) | 0,59 $/h | 0,44-0,55 $/h | 0,29-0,78 $/h | 0,45 $/h |
| RTX 3090 (24GB) | 0,46 $/h | 0,32-0,40 $/h | 0,18-0,60 $/h | 0,35 $/h |
| RTX A6000 (48GB) | 0,49 $/h | 0,40-0,48 $/h | 0,40-0,70 $/h | 0,52 $/h |
Analyse : Le bas de gamme de Vast.ai bat les prix de RunPod de 30-50%, mais atteindre ces tarifs nécessite de sélectionner des fournisseurs avec des scores de fiabilité plus bas ou des emplacements moins pratiques. Aux prix médians, l’écart se réduit à 15-25%.
Prix des GPU de Centre de Données
Pour les charges de travail nécessitant du matériel de classe centre de données—grands modèles de langage, entraînement multi-GPU, inférence de production—les deux plateformes offrent un accès A100 et H100 avec des réductions substantielles par rapport aux hyperscalers.
| GPU | RunPod Secure Cloud | RunPod Community | Plage Vast.ai | Équivalent AWS |
|---|---|---|---|---|
| A100 40GB | N/A | 1,09-1,29 $/h | 0,80-1,20 $/h | ~4,10 $/h |
| A100 80GB | 1,39-1,49 $/h | 1,19-1,35 $/h | 0,84-1,49 $/h | ~4,10 $/h |
| H100 80GB | 2,39 $/h | 1,89-2,29 $/h | 1,47-2,94 $/h | ~6,90 $/h |
| L4 24GB | 0,39 $/h | 0,29-0,35 $/h | 0,35-0,50 $/h | 0,80 $/h |
Analyse : Les deux plateformes offrent des économies de 60-75% par rapport à AWS pour les GPU de centre de données. La différence entre RunPod et Vast.ai se réduit pour le matériel haut de gamme, où la fiabilité devient plus importante et moins de fournisseurs existent sur le marché.
Différences de Modèle de Prix
Au-delà des tarifs bruts, les modèles de prix diffèrent de manière importante :
RunPod Secure Cloud :
- Prix fixes indépendamment de la demande
- Disponibilité garantie une fois l’instance en cours d’exécution
- Aucune dynamique d’enchères ou d’adjudication
- Coûts prévisibles pour la budgétisation
RunPod Community Cloud :
- Prix variables par fournisseur
- Le fournisseur fixe ses propres tarifs
- Peut être interrompu si le fournisseur a besoin du matériel
- Économie de type instance spot
Vast.ai :
- Prix dynamiques basés sur l’offre et la demande
- Les fournisseurs fixent les prix minimums, le marché détermine les tarifs réels
- Les prix peuvent augmenter pendant les périodes de forte demande
- Économies importantes disponibles pendant les heures creuses
Pour une analyse complète des prix de location de GPU à travers tous les principaux fournisseurs, y compris les options de cloud d’entreprise, consultez notre comparaison complète des prix de location de GPU pour 2026.
Scénario de Coût Réel : Entraîner un Modèle LoRA
Pour illustrer les différences de coûts pratiques, considérez l’entraînement d’un modèle LoRA Stable Diffusion—une charge de travail courante qui prend environ 2 heures sur une RTX 4090.
| Plateforme | Sélection GPU | Tarif Horaire | Total 2 Heures |
|---|---|---|---|
| RunPod Secure | RTX 4090 | 0,59 $ | 1,18 $ |
| RunPod Community | RTX 4090 (médiane) | 0,49 $ | 0,98 $ |
| Vast.ai | RTX 4090 (99%+ fiable) | 0,52 $ | 1,04 $ |
| Vast.ai | RTX 4090 (97%+ fiable) | 0,38 $ | 0,76 $ |
La différence de 0,42 $ entre RunPod Secure et l’option Vast.ai la moins chère s’accumule sur de nombreuses exécutions d’entraînement. Sur 50 sessions d’entraînement, cela représente 21 $ d’économies—significatif pour les développeurs indépendants mais peut-être pas la peine de l’incertitude de fiabilité pour les applications professionnelles.
Pour des conseils détaillés sur les flux de travail d’entraînement LoRA, y compris la sélection de GPU et l’optimisation des coûts, consultez notre guide pour entraîner des modèles LoRA Stable Diffusion pour moins de 10 $.
Fiabilité et Temps de Disponibilité
La fiabilité sépare les plateformes de location de GPU plus que tout autre facteur sauf le prix. Un GPU peu fiable qui coûte moitié prix n’est pas une bonne affaire si votre exécution d’entraînement plante à l’heure 11 d’une tâche de 12 heures.
Architecture de Fiabilité de RunPod
Niveau Secure Cloud : Le Secure Cloud de RunPod exploite du matériel dans des centres de données gérés avec des configurations standardisées. L’entreprise contrôle l’environnement, maintient le matériel et assume la responsabilité du temps de disponibilité. Bien que RunPod ne publie pas de chiffres SLA formels pour Secure Cloud, les rapports d’utilisateurs et mon expérience personnelle suggèrent une disponibilité de 99,5%+.
Le matériel en Secure Cloud est dédié—une fois que vous démarrez une instance, elle reste disponible jusqu’à ce que vous la terminiez. Aucun fournisseur ne peut récupérer le matériel en pleine session.
Niveau Community Cloud : La fiabilité de Community Cloud varie selon le fournisseur, similaire à Vast.ai. Les fournisseurs reçoivent des notes de fiabilité basées sur le temps de disponibilité historique, et les utilisateurs peuvent filtrer pour des fournisseurs mieux notés. La plateforme offre une certaine protection grâce à la vérification des fournisseurs, mais des interruptions peuvent encore survenir.
Architecture de Fiabilité de Vast.ai
Vast.ai est entièrement peer-to-peer, ce qui signifie que la fiabilité dépend entièrement du comportement du fournisseur individuel. La plateforme fournit des métriques détaillées pour aider les utilisateurs à évaluer le risque :
Score de Fiabilité : Pourcentage du temps où la machine était disponible lorsqu’elle était louée. Varie de ~92% à 99,9%.
Historique de Temps de Disponibilité : Représentation visuelle de la disponibilité récente, montrant toutes les pannes ou interruptions.
Ancienneté du Fournisseur : Depuis combien de temps le fournisseur est sur la plateforme. Des antécédents plus longs fournissent plus de données prédictives.
Nombre de Locations : Plus de locations signifie plus de points de données pour l’évaluation de la fiabilité.
Les utilisateurs avertis peuvent obtenir une excellente fiabilité sur Vast.ai en filtrant pour des fournisseurs avec des scores de fiabilité de 99%+, 6+ mois d’ancienneté sur la plateforme et des emplacements dans des régions de réseau électrique stable. Cependant, ce filtrage réduit l’inventaire disponible et élimine souvent les options les moins chères.
Matrice de Comparaison de Fiabilité
| Métrique | RunPod Secure | RunPod Community | Vast.ai (filtre 99%+) | Vast.ai (tous) |
|---|---|---|---|---|
| Temps de Disponibilité Typique | 99,5%+ | 98-99% | 99%+ | 95-99% |
| Risque d’Interruption | Très Faible | Modéré | Faible | Modéré-Élevé |
| Cohérence Matérielle | Élevée | Variable | Variable | Variable |
| Performance Réseau | Cohérente | Variable | Variable | Variable |
Considérations Pratiques de Fiabilité
Pour les exécutions d’entraînement de moins de 4 heures : Les deux plateformes offrent une fiabilité acceptable. Les économies de coûts de Vast.ai l’emportent généralement sur le petit risque d’interruption pour les tâches courtes.
Pour les exécutions d’entraînement de 4-12 heures : RunPod Secure Cloud ou Vast.ai avec filtrage strict de fiabilité (99%+) a du sens. Les conséquences de perdre 8 heures d’entraînement justifient de payer une prime pour la fiabilité.
Pour les exécutions d’entraînement de plus de 12 heures : Le checkpointing devient essentiel quelle que soit la plateforme. Implémentez des sauvegardes de checkpoint toutes les 30-60 minutes, et le coût de l’interruption se réduit au temps depuis le dernier checkpoint plutôt qu’à toute l’exécution.
Pour l’inférence de production : RunPod Secure Cloud est le choix évident à moins que vous n’implémentiez votre propre basculement et vérification de santé. Les systèmes de production nécessitent un temps de disponibilité prévisible que la variabilité du marché ne peut pas garantir.

Matériel Disponible
Les deux plateformes excellent dans la fourniture de matériel non disponible sur les clouds d’entreprise, en particulier les GPU grand public. Cependant, leurs inventaires diffèrent de manière significative.
Disponibilité des GPU Grand Public
| Modèle GPU | Disponibilité RunPod | Disponibilité Vast.ai |
|---|---|---|
| RTX 5090 (32GB) | Bonne | Modérée (GPU plus récent) |
| RTX 4090 (24GB) | Excellente | Excellente |
| RTX 4080 (16GB) | Limitée | Bonne |
| RTX 3090 (24GB) | Bonne | Excellente |
| RTX 3080 (12GB) | Limitée | Bonne |
| RTX 3070 (8GB) | Très Limitée | Modérée |
La base de fournisseurs plus large de Vast.ai offre généralement plus de variété dans le matériel grand public, y compris les modèles plus anciens et moins courants. RunPod se concentre sur les options les plus populaires pour les charges de travail IA, en priorisant l’inventaire RTX 4090 et RTX 3090.
Disponibilité des GPU de Centre de Données
| Modèle GPU | Disponibilité RunPod | Disponibilité Vast.ai |
|---|---|---|
| H100 80GB | Bonne | Modérée |
| H200 140GB | Limitée | Limitée |
| A100 80GB | Excellente | Bonne |
| A100 40GB | Bonne (Community) | Bonne |
| A6000 48GB | Bonne | Bonne |
| L4 24GB | Excellente | Bonne |
| L40S 48GB | Modérée | Limitée |
| A40 48GB | Modérée | Modérée |
RunPod a investi dans du matériel de classe centre de données pour son niveau Secure Cloud, offrant une disponibilité cohérente des GPU A100 et H100. La disponibilité des GPU de centre de données de Vast.ai dépend des fournisseurs qui ont acheté ou loué cet équipement—la disponibilité peut être sporadique.
Configurations Multi-GPU
Pour l’entraînement de grands modèles nécessitant plusieurs GPU, les deux plateformes font face à des limitations par rapport aux clouds d’entreprise.
RunPod : Offre des pods multi-GPU jusqu’à 8xA100 ou 8xH100 en Secure Cloud. La disponibilité multi-GPU de Community Cloud est limitée et incohérente.
Vast.ai : Les systèmes multi-GPU sont disponibles mais rares. Trouver des systèmes 4x ou 8x GPU nécessite patience et flexibilité sur le timing. Les fournisseurs avec des systèmes multi-GPU facturent des tarifs premium.
Aucune plateforme n’égale la disponibilité multi-GPU des instances AWS p4d ou de la série Azure ND. Pour l’entraînement 8-GPU à grande échelle, les clouds d’entreprise restent nécessaires pour une disponibilité garantie.
Expérience Utilisateur et Interface
L’écart d’expérience utilisateur entre RunPod et Vast.ai reflète leurs philosophies et utilisateurs cibles différents.
Interface RunPod
L’interface de RunPod privilégie l’accessibilité pour les utilisateurs qui ne sont pas des experts en infrastructure. Le tableau de bord présente les GPU disponibles avec des prix clairs, le déploiement prend quelques clics, et les modèles préconfigurés gèrent la majeure partie de la configuration de l’environnement.
Points forts :
- Interface propre et moderne avec navigation intuitive
- Galerie de modèles pour les charges de travail courantes
- Déploiement en un clic pour Stable Diffusion, inférence LLM et plus
- Accès JupyterLab intégré sans configuration supplémentaire
- Design responsive pour mobile pour surveillance en déplacement
Points faibles :
- Options de filtrage moins granulaires que Vast.ai
- Sélection de fournisseur Community Cloud moins détaillée
- Configuration avancée nécessite de creuser dans les paramètres
Interface Vast.ai
L’interface de Vast.ai cible les utilisateurs à l’aise avec les décisions d’infrastructure. La vue du marché fournit un filtrage extensif et des informations détaillées sur les fournisseurs, permettant une correspondance précise des exigences avec le matériel disponible.
Points forts :
- Métriques détaillées des fournisseurs (fiabilité, vitesse réseau, emplacement)
- Filtrage avancé par mémoire GPU, espace disque et bande passante réseau
- Tri des prix et options de prix basées sur les enchères
- Historique et notes transparents des fournisseurs
- Outil CLI pour accès programmatique
Points faibles :
- Courbe d’apprentissage plus raide pour les nouveaux utilisateurs
- L’interface peut sembler surchargée d’informations
- Système de modèles moins raffiné que RunPod
- Plus de décisions requises avant le déploiement
Comparaison de Gestion d’Instance
| Fonctionnalité | RunPod | Vast.ai |
|---|---|---|
| Temps jusqu’au Premier GPU | 2-5 minutes | 2-5 minutes |
| Déploiement de Modèle | Un clic | Manuel ou modèle |
| Accès SSH | Oui | Oui |
| Terminal Web | Oui | Oui |
| JupyterLab | Intégré | Configuration manuelle |
| Explorateur de Fichiers | Oui | Limité |
| Arrêter/Reprendre | Oui | Oui |
| Facturation à la Seconde | Oui | Oui |
Modèles et Environnements Préconfigurés
Les modèles réduisent considérablement le temps jusqu’à la productivité pour les charges de travail courantes. Les deux plateformes offrent des systèmes de modèles, mais avec différents niveaux de raffinement et de couverture.
Modèles RunPod
RunPod maintient des modèles officiels pour les principales charges de travail IA :
Stable Diffusion :
- Automatic1111 WebUI
- ComfyUI
- Forge WebUI
- InvokeAI
Inférence LLM :
- Text Generation WebUI (Oobabooga)
- vLLM
- Ollama
- Serveurs API compatibles OpenAI
Développement :
- PyTorch avec CUDA
- TensorFlow avec CUDA
- Notebooks Jupyter
- VS Code Server
Autres :
- Whisper (reconnaissance vocale)
- Modèles de génération musicale
- Support de conteneur personnalisé
Ces modèles incluent une configuration CUDA appropriée, des modèles préchargés le cas échéant et des paramètres par défaut sensés. Un nouvel utilisateur peut avoir Stable Diffusion générant des images dans les 10 minutes suivant la création d’un compte.
Modèles Vast.ai
Le système de modèles de Vast.ai est moins organisé mais plus flexible :
Modèles Officiels :
- Environnements de développement CUDA de base
- Configurations de notebook Jupyter
- Configurations de framework ML courants
Modèles Communautaires :
- Configurations soumises par les utilisateurs
- Qualité et maintenance variables
- Grande variété mais documentation incohérente
Intégration Docker :
- Support complet d’image Docker
- Récupérer n’importe quelle image publique
- Construire des images personnalisées
L’approche native Docker de Vast.ai offre une flexibilité maximale pour les utilisateurs qui savent exactement ce qu’ils veulent. Cependant, l’absence de modèles officiels maintenus signifie plus de travail de configuration pour les cas d’usage courants.
Comparaison de Modèles
| Charge de Travail | RunPod | Vast.ai |
|---|---|---|
| Stable Diffusion | Un clic, plusieurs UI | Manuel ou communauté |
| Inférence LLM | Plusieurs options, un clic | Configuration manuelle |
| Entraînement (PyTorch) | Modèle disponible | Modèle disponible |
| Conteneurs Personnalisés | Supporté | Excellent support |
| Temps de Configuration (charges courantes) | 5-10 minutes | 15-30 minutes |
Pour les utilisateurs exécutant des charges de travail IA standard, l’avantage des modèles de RunPod économise un temps significatif. Pour les utilisateurs avec des exigences personnalisées ou une expertise Docker, la flexibilité de Vast.ai peut être préférable.
Stockage et Transfert de Données
Les considérations de stockage et de transfert de données surprennent souvent les nouveaux utilisateurs. Les coûts GPU sont évidents ; les coûts auxiliaires pour stocker des ensembles de données et déplacer des données sont moins visibles mais peuvent être significatifs.
Stockage RunPod
Stockage de Pod :
- Chaque pod inclut un espace disque configurable
- Le stockage du conteneur persiste tant que le pod existe
- Prix inclus dans le tarif horaire du pod jusqu’à un seuil
- Stockage supplémentaire facturé séparément
Stockage de Volume Réseau :
- Stockage persistant qui survit à la terminaison du pod
- 0,07 $ par Go par mois
- Peut être attaché aux pods dans la même région
- Utile pour les ensembles de données et les poids de modèles
Transfert de Données :
- Pas de frais supplémentaires pour le transfert de données
- Les vitesses de téléchargement varient selon le centre de données
- Vitesses de téléversement généralement excellentes
Stockage Vast.ai
Stockage d’Instance :
- Espace disque déterminé par le fournisseur
- Varie considérablement entre les fournisseurs
- Certains fournisseurs offrent un SSD limité ; d’autres ont des téraoctets disponibles
- Le stockage fait partie du tarif horaire
Stockage Persistant :
- Pas de produit de stockage persistant natif
- Les utilisateurs doivent gérer leurs propres solutions
- Approches courantes : synchronisation de stockage cloud, serveurs externes
- Plus complexe que RunPod pour les ensembles de données couvrant plusieurs sessions
Transfert de Données :
- Pas de frais de plateforme pour le transfert
- Les vitesses réseau varient considérablement selon le fournisseur
- Métrique clé à vérifier lors de la sélection des fournisseurs
- Certains fournisseurs ont une bande passante limitée
Comparaison des Coûts de Stockage
Pour un flux de travail typique nécessitant 100 Go de stockage persistant :
| Besoin de Stockage | RunPod | Vast.ai |
|---|---|---|
| Stockage d’Ensemble de Données (100GB, 1 mois) | 7,00 $ | Solution externe requise |
| Poids de Modèle (50GB, inclus dans pod) | 0 $ | 0 $ |
| Transfert de Données | Gratuit | Gratuit |
La fonctionnalité de Volume Réseau de RunPod offre une commodité significative pour les utilisateurs qui ont besoin de persistance des données entre les sessions. Les utilisateurs de Vast.ai synchronisent généralement avec le stockage cloud (S3, GCS ou similaire) entre les sessions, ajoutant de la complexité et du temps de transfert potentiel.
Options de Paiement
La flexibilité de paiement compte pour les utilisateurs internationaux, ceux qui évitent les services bancaires traditionnels et les organisations avec des exigences d’approvisionnement spécifiques.
Méthodes de Paiement RunPod
- Cartes de crédit et de débit (Visa, Mastercard, American Express)
- Cryptomonnaie (Bitcoin, Ethereum, USDC)
- Crédits de compte prépayés
- Pas de facturation pour les comptes d’entreprise (libre-service uniquement)
L’option cryptomonnaie de RunPod est remarquable—de nombreuses plateformes cloud évitent complètement les paiements crypto. L’implémentation est simple : déposer de la crypto, recevoir des crédits de compte, utiliser les crédits pour la location de GPU.
Méthodes de Paiement Vast.ai
- Cartes de crédit et de débit
- Crédits de compte prépayés
- Pas de support de cryptomonnaie
- Pas de facturation
Les options de paiement plus limitées de Vast.ai peuvent affecter les utilisateurs qui préfèrent la cryptomonnaie ou nécessitent une facturation formelle pour la comptabilité d’entreprise.
Exigences de Compte
| Exigence | RunPod | Vast.ai |
|---|---|---|
| Vérification Email | Oui | Oui |
| Vérification Téléphonique | Non | Non |
| Vérification d’Identité (KYC) | Non | Non |
| Vérification d’Entreprise | Non | Non |
| Dépôt Minimum | Aucun | Aucun |
Les deux plateformes maintiennent de faibles barrières à l’entrée. Aucune ne nécessite la vérification extensive que les fournisseurs de cloud d’entreprise exigent. Cette accessibilité vient avec des compromis—aucune plateforme ne fournira la documentation de conformité que les grandes organisations peuvent nécessiter.
Support et Documentation
Lorsque les choses tournent mal—et elles le feront éventuellement—la qualité du support détermine la rapidité de votre rétablissement.
Support RunPod
Canaux :
- Communauté Discord (très active)
- Support par e-mail
- Wiki de documentation
- Tutoriels vidéo
Temps de Réponse :
- Discord : Souvent quelques minutes pendant les heures de bureau
- E-mail : Généralement 24-48 heures
- Questions de la communauté : Souvent répondues directement par le personnel
La présence Discord de RunPod est exceptionnelle pour une entreprise de cette taille. Les membres du personnel surveillent activement les canaux et répondent fréquemment aux questions des utilisateurs. L’entreprise a clairement investi dans la construction de communauté comme stratégie de support.
La documentation couvre bien les flux de travail courants mais peut être en retard sur les nouvelles fonctionnalités. Les tutoriels vidéo aident les apprenants visuels mais ne sont pas exhaustifs.
Support Vast.ai
Canaux :
- Communauté Discord
- Support par e-mail
- Documentation
- FAQ
Temps de Réponse :
- Discord : Variable, souvent répondu par la communauté
- E-mail : 24-72 heures typique
- Moins de présence du personnel dans les canaux communautaires
Le support de Vast.ai reflète sa nature de marché. L’entreprise arbitre entre locataires et fournisseurs mais a moins de contrôle sur l’infrastructure et donc moins de capacité à résoudre certains problèmes. Les problèmes côté fournisseur nécessitent de travailler avec des fournisseurs individuels.
La documentation est adéquate pour les opérations de base mais moins détaillée que celle de RunPod pour les charges de travail spécifiques.
Comparaison du Support
| Aspect | RunPod | Vast.ai |
|---|---|---|
| Activité Communautaire | Très Élevée | Modérée |
| Réponse du Personnel | Fréquente | Occasionnelle |
| Profondeur de Documentation | Bonne | Adéquate |
| Contenu Vidéo | Oui | Limité |
| Résolution en Libre-Service | Élevée | Modérée |
Considérations de Sécurité
Les préoccupations de sécurité diffèrent entre les plateformes gérées et les marchés peer-to-peer. Comprendre le modèle de menace aide à faire des choix appropriés.
Modèle de Sécurité RunPod
Secure Cloud :
- Matériel dans des centres de données gérés
- Sécurité physique standard de centre de données
- RunPod contrôle la pile d’infrastructure
- Isolation de conteneurs entre utilisateurs
- Pas d’accès bare metal par les locataires
Community Cloud :
- Matériel contrôlé par les fournisseurs
- Le fournisseur a un accès physique au matériel
- Potentiel de fournisseurs malveillants (rare mais possible)
- Isolation de conteneurs mais non garantie
Modèle de Sécurité Vast.ai
- Tout le matériel contrôlé par des fournisseurs individuels
- Le fournisseur a un accès physique et administratif
- Vérification détaillée des fournisseurs mais pas infaillible
- L’isolation des conteneurs varie selon la configuration du fournisseur
- Certains fournisseurs peuvent enregistrer ou inspecter le trafic
Recommandations Pratiques de Sécurité
Pour les charges de travail sensibles (modèles propriétaires, données confidentielles) :
- Utilisez exclusivement RunPod Secure Cloud
- Envisagez le cloud d’entreprise si la conformité est requise
- N’utilisez jamais les GPU de marché peer-to-peer pour les données sensibles
Pour les charges de travail non sensibles (modèles publics, données synthétiques) :
- Les deux plateformes sont acceptables
- Les fournisseurs avec de longs antécédents et des notes élevées présentent un faible risque
- L’hygiène de sécurité standard s’applique (pas d’identifiants codés en dur, etc.)
Pour toute charge de travail :
- Évitez de laisser des identifiants dans les scripts d’entraînement
- Utilisez des variables d’environnement pour les clés API
- Nettoyez les instances avant la terminaison
- Supposez que les fournisseurs pourraient inspecter le contenu du disque après la terminaison
Comparaison de Performance Réelle
Les prix bruts et les fonctionnalités n’importent que si les GPU fonctionnent réellement comme prévu. J’ai exécuté des charges de travail identiques sur les deux plateformes pour mesurer les différences pratiques.
Méthodologie de Test
Matériel : RTX 4090 24GB Charge de Travail 1 : Génération d’images Stable Diffusion XL (50 images, 30 étapes chacune) Charge de Travail 2 : Entraînement LoRA (50 images, 10 époques) Charge de Travail 3 : Inférence LLM (Llama 2 7B, 1000 tokens générés)
Chaque test a été exécuté trois fois sur chaque plateforme, en sélectionnant des fournisseurs de milieu de gamme sur Vast.ai (fiabilité 98%+, prix médian).
Résultats de Performance
| Charge de Travail | RunPod Secure | Vast.ai (fournisseur 98%+) | Différence |
|---|---|---|---|
| Génération SDXL (50 images) | 4m 32s | 4m 28s | -1,5% |
| Entraînement LoRA (10 époques) | 52m 14s | 53m 41s | +2,7% |
| Inférence LLM (1000 tokens) | 28s | 29s | +3,6% |
Analyse : Les différences de performance sont négligeables pour les charges de travail limitées par le calcul. Le RTX 4090 est le même GPU sur les deux plateformes—le silicium ne se soucie pas de qui le possède.
Le léger ralentissement de Vast.ai en entraînement et inférence reflète probablement une surcharge réseau plutôt que la performance GPU. Ces différences sont bien dans le bruit à des fins pratiques.
Performance Réseau
La performance réseau varie de manière plus significative :
| Métrique | RunPod Secure | Moyenne Vast.ai | Meilleur Vast.ai |
|---|---|---|---|
| Vitesse de Téléchargement | 500+ Mbps | 200-400 Mbps | 800+ Mbps |
| Vitesse de Téléversement | 400+ Mbps | 150-300 Mbps | 600+ Mbps |
| Cohérence de Latence | Élevée | Variable | Élevée |
Pour les charges de travail impliquant un transfert de données important (grands ensembles de données, téléversements fréquents de modèles), la performance réseau cohérente de RunPod offre un gain de temps significatif. Pour les charges de travail dominées par le calcul, les différences réseau importent moins.
Meilleurs Cas d’Usage pour Chaque Plateforme
Basé sur l’analyse des prix, de la fiabilité et des fonctionnalités, voici des recommandations spécifiques pour les scénarios courants.
Choisissez RunPod Secure Cloud Quand :
Systèmes d’inférence de production : Les exigences de fiabilité des systèmes de production justifient la prime de RunPod. Un serveur d’inférence qui plante à 2h du matin vaut plus que la différence de coût.
Exécutions d’entraînement sensibles au temps : Lorsque les délais comptent, la disponibilité prévisible bat l’espoir qu’un fournisseur Vast.ai ne se déconnecte pas. L’augmentation modeste du coût est une assurance contre le temps perdu.
Nouveaux utilisateurs apprenant le domaine : Les modèles et la documentation de RunPod réduisent la courbe d’apprentissage. Commencez ici, puis envisagez Vast.ai une fois que vous comprenez vos besoins.
Équipes avec ressources partagées : Les fonctionnalités d’organisation et de stockage persistant de RunPod facilitent la collaboration par rapport à la coordination entre fournisseurs Vast.ai.
Choisissez Vast.ai Quand :
Exploration avec contraintes budgétaires : Lors de l’apprentissage ou de l’expérimentation, les économies de 30-40% de Vast.ai permettent plus d’itérations dans un budget fixe. Les exécutions interrompues comptent moins pendant l’exploration.
Traitement par lots avec checkpointing : Les charges de travail qui créent régulièrement des checkpoints peuvent tolérer les interruptions de fournisseurs. Les économies de coûts s’accumulent sur de longues exécutions d’entraînement avec une stratégie de checkpoint appropriée.
Exigences matérielles inhabituelles : Besoin d’un GPU ancien spécifique ? La base de fournisseurs diversifiée de Vast.ai inclut du matériel que RunPod n’a pas en stock.
Entraînement nocturne ou de week-end : Les prix hors heures de pointe sur Vast.ai baissent considérablement. Lancer de longues exécutions d’entraînement vendredi soir à tarifs réduits a du sens si vous pouvez tolérer l’incertitude de fiabilité.
Cas d’Usage Où L’un ou L’autre Fonctionne :
Entraînement LoRA (2-4 heures) : Les deux plateformes gèrent bien cette charge de travail. Choisissez en fonction des prix et de la disponibilité actuels.
Génération Stable Diffusion : Les sessions de génération interactive fonctionnent bien sur l’une ou l’autre plateforme. Le risque de fiabilité pendant une session d’1 heure est minime.
Expériences ponctuelles : Les tests rapides pour valider des idées avant de s’engager dans des exécutions plus longues fonctionnent également bien sur les deux plateformes.
Considérations de Migration
Basculer entre les plateformes est simple avec une certaine préparation. Les deux utilisent des technologies de conteneurs standard et un accès SSH.
Migration de Données
Ensembles de données et poids de modèles :
- Stocker dans le stockage cloud (S3, GCS, Backblaze B2) accessible depuis l’une ou l’autre plateforme
- Éviter de dépendre du stockage persistant spécifique à la plateforme
- Télécharger du cloud vers l’instance au démarrage de la session
Code et configurations :
- Utiliser des dépôts git pour tout le code
- Stocker les fichiers de configuration dans le contrôle de version
- Éviter les chemins spécifiques à la plateforme dans les scripts
Images de conteneur :
- Les deux plateformes prennent en charge Docker Hub et les registres de conteneurs
- Les images personnalisées fonctionnent sur les deux plateformes
- Abstraire les différences de plateforme dans les scripts de point d’entrée
Portabilité des Flux de Travail
Un flux de travail portable fonctionne sur l’une ou l’autre plateforme avec des modifications minimales :
# Exemple de script de configuration portable
#!/bin/bash
# Cloner le dépôt de code
git clone https://github.com/yourrepo/training-code.git
# Télécharger l'ensemble de données depuis le stockage cloud
aws s3 sync s3://your-bucket/dataset ./dataset
# Télécharger les poids du modèle
wget https://huggingface.co/model/weights.safetensors -O ./models/
# Exécuter l'entraînement
python train.py --config ./config.yaml
# Téléverser les résultats
aws s3 sync ./output s3://your-bucket/results/Ce script s’exécute de manière identique sur RunPod ou Vast.ai, ne nécessitant que les identifiants appropriés pour l’accès au stockage cloud.
Alternatives à Considérer
Bien que RunPod et Vast.ai dominent l’espace de location de GPU sur le marché, d’autres options méritent considération selon vos exigences.
Lambda Labs
Lambda Labs offre un cloud GPU géré avec des prix fixes et un fort accent sur le ML. Les prix se situent entre les clouds d’entreprise et les marchés. Bon choix pour les utilisateurs qui veulent la fiabilité sans la complexité du marché et sont prêts à payer une prime modérée.
GPUFlow
GPUFlow opère un marché peer-to-peer avec traitement des paiements basé sur la blockchain. Les contrats intelligents gèrent l’entiercement, éliminant le risque de contrepartie sans autorité centrale. Avantages principaux : paiements en cryptomonnaie sans KYC, frais de plateforme plus bas (10-15% versus 20-30%) et provisionnement rapide d’instances. Vaut la peine d’être considéré pour les utilisateurs qui préfèrent l’infrastructure décentralisée.
Clouds d’Entreprise (AWS, Azure, GCP)
Pour les exigences de conformité, les SLA garantis et le support d’entreprise, les hyperscalers restent nécessaires. La prime de prix 3-5x achète des capacités que les plateformes de marché ne peuvent pas fournir : certification SOC2, conformité HIPAA, ingénieurs de support dédiés et garanties contractuelles de temps de disponibilité.
Achat de Matériel
À une échelle suffisante, posséder du matériel devient économique. Le seuil de rentabilité se produit généralement autour de 2 500-3 000 heures d’utilisation pour les GPU grand public. Les organisations exécutant des charges de travail continues devraient évaluer le coût total de possession par rapport à la location.
Questions Fréquemment Posées
RunPod ou Vast.ai est-il moins cher pour la location de GPU ?
Vast.ai offre généralement des tarifs horaires plus bas en raison de son modèle de marché peer-to-peer pur. Les GPU RTX 4090 sur Vast.ai varient de 0,29 $ à 0,78 $ par heure, tandis que le niveau Secure Cloud de RunPod facture 0,59 $ par heure pour le même GPU. Cependant, atteindre les tarifs les plus bas de Vast.ai nécessite de sélectionner des fournisseurs avec des scores de fiabilité plus bas. À des niveaux de fiabilité équivalents (99%+), l’écart de prix se réduit à 15-25%.
Quelle plateforme est plus fiable pour les charges de travail de production ?
Le niveau Secure Cloud de RunPod offre une fiabilité plus cohérente avec du matériel de centre de données sélectionné. L’entreprise contrôle l’infrastructure et assume la responsabilité du temps de disponibilité. La fiabilité de Vast.ai varie selon le fournisseur individuel, avec des notes allant de 97% à 99,9%. Pour l’inférence de production nécessitant une haute disponibilité, RunPod est le choix le plus sûr. Pour les tâches d’entraînement par lots pouvant tolérer des interruptions occasionnelles, Vast.ai offre une meilleure économie.
Puis-je utiliser des GPU grand public comme RTX 4090 sur les deux plateformes ?
Oui. RunPod et Vast.ai offrent tous deux l’accès aux GPU grand public, notamment RTX 3090, RTX 4090 et RTX 5090. Cela les distingue des fournisseurs de cloud d’entreprise comme AWS, Azure et GCP, qui n’offrent que des modèles de GPU de centre de données (A100, H100, etc.). Les GPU grand public offrent un excellent rapport prix-performance pour la plupart des charges de travail IA.
Quelle plateforme a de meilleurs modèles préconfigurés pour les charges de travail IA ?
RunPod offre des modèles officiels plus étendus, y compris des déploiements en un clic pour Stable Diffusion (plusieurs UI), divers serveurs d’inférence LLM et des frameworks d’entraînement populaires. Les modèles sont maintenus par le personnel de RunPod et incluent une configuration CUDA appropriée. Vast.ai fournit des modèles communautaires mais avec moins de curation et une maintenance variable. Les utilisateurs qui préfèrent des configurations clés en main trouvent généralement RunPod plus pratique.
RunPod et Vast.ai nécessitent-ils une vérification d’identité ?
Aucune des plateformes ne nécessite de vérification KYC complète pour un usage basique. RunPod nécessite une vérification par e-mail et un moyen de paiement valide. Vast.ai nécessite des informations de compte minimales. Les deux plateformes sont beaucoup moins restrictives que les fournisseurs de cloud d’entreprise, qui exigent une vérification d’entreprise, des vérifications de crédit et parfois des processus d’approbation de quota avant d’accorder l’accès aux GPU.
Comment choisir entre les plateformes pour un projet spécifique ?
Considérez trois facteurs : exigences de fiabilité, contraintes budgétaires et valeur du temps de configuration. Les systèmes de production ou les exécutions d’entraînement critiques en termes de délai favorisent RunPod Secure Cloud. Le travail exploratoire ou les projets à budget limité favorisent Vast.ai. Les nouveaux utilisateurs bénéficient des modèles de RunPod. Les utilisateurs expérimentés avec des exigences personnalisées peuvent préférer la flexibilité de Vast.ai.
Puis-je basculer facilement entre les plateformes ?
Oui. Les deux plateformes utilisent un accès SSH standard et prennent en charge les conteneurs Docker. Stocker les ensembles de données dans le stockage cloud et le code dans les dépôts git permet une migration facile. Le principal coût de basculement est d’apprendre l’interface de chaque plateforme et les flux de travail de provisionnement—généralement quelques heures de familiarisation.
Recommandations Finales
Après une utilisation extensive des deux plateformes, mes recommandations sont :
Commencez avec RunPod si :
- Vous êtes nouveau dans la location de GPU
- Vous avez besoin de fiabilité de production
- La disponibilité de modèles compte pour votre flux de travail
- Vous appréciez un support réactif
Commencez avec Vast.ai si :
- L’optimisation des coûts est votre préoccupation principale
- Vous avez de l’expérience en infrastructure
- Vos charges de travail tolèrent les interruptions
- Vous aimez évaluer les options et optimiser
Considérez GPUFlow si :
- Vous préférez les paiements en cryptomonnaie
- Les exigences KYC sont une préoccupation
- Des frais de plateforme plus bas impactent votre économie
- Vous voulez une sécurité de paiement vérifiée par blockchain
Les bonnes nouvelles : RunPod et Vast.ai offrent tous deux une excellente valeur par rapport aux alternatives d’entreprise. L’un ou l’autre choix économise 60-80% par rapport à AWS ou Azure. Les différences entre eux, bien que significatives, sont secondaires aux économies massives que les deux permettent.
Pour les projets en cours, je recommande de maintenir des comptes sur les deux plateformes. Utilisez RunPod pour les travaux critiques en termes de fiabilité et les projets sensibles au temps. Utilisez Vast.ai pour l’exploration, les expériences et le traitement par lots où le coût compte plus que la disponibilité garantie. La flexibilité de choisir en fonction des exigences du projet, plutôt que de s’engager entièrement sur une plateforme, maximise à la fois l’efficacité des coûts et la fiabilité là où chacune compte le plus.
Vous cherchez une location de GPU avec paiements en cryptomonnaie et sécurité par contrat intelligent ? GPUFlow offre des tarifs de marché compétitifs avec entiercement vérifié par blockchain, des frais de plateforme plus bas et aucune exigence KYC. Vérifiez la disponibilité et les prix actuels sur gpuflow.app.
Guides connexes :
- Comparaison des Prix de Location de GPU 2026
- Comment Entraîner des Modèles LoRA Stable Diffusion pour Moins de 10 $
- Guide Complet pour Louer des GPU avec Cryptomonnaie
Cette comparaison a été mise à jour pour la dernière fois le 12 février 2026. Les fonctionnalités de plateforme et les prix changent fréquemment. Vérifiez les informations actuelles directement auprès de RunPod et Vast.ai avant de prendre des décisions.