
La note ne satisfait personne mais change tout.
Quand la division semiconducteurs de Samsung a découvert que des ingénieurs avaient téléchargé des conceptions de puces propriétaires vers ChatGPT, la réponse fut immédiate et absolue. Une interdiction à l’échelle de l’entreprise. Aucune exception. Aucun processus d’appel. L’outil qui était devenu synonyme de productivité IA était désormais interdit sur tous les réseaux de l’entreprise.
Samsung n’était pas seule. En quelques mois, des annonces similaires ont émergé de JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank et des dizaines d’autres entreprises. Des cabinets d’avocats conseillant des entreprises du Fortune 500 ont interdit aux associés d’utiliser le service. Les systèmes de santé ont bloqué l’accès au niveau du pare-feu. Les agences gouvernementales ont émis des directives qui ont effectivement mis fin à toute ambiguïté sur l’utilisation acceptable.
Le schéma a révélé quelque chose que les passionnés de technologie avaient négligé dans leur enthousiasme pour les capacités de l’IA : l’adoption en entreprise opère sous des contraintes que l’adoption grand public n’a pas.
Cet article examine pourquoi les politiques d’IA des entreprises se durcissent, quels risques spécifiques motivent ces décisions et comment les organisations peuvent maintenir des capacités d’IA sans accepter une exposition inacceptable des données. Le chemin à suivre ne nécessite pas d’abandonner l’IA. Il nécessite de comprendre que l’infrastructure compte autant que l’intelligence.

Les incidents qui ont tout changé
Les interdictions d’IA en entreprise ne sont pas nées d’évaluations de risques théoriques. Elles ont suivi des incidents réels où des informations confidentielles ont échappé au contrôle organisationnel.
La faille semiconducteurs de Samsung
Début 2023, des employés de Samsung Electronics ont utilisé ChatGPT pour déboguer du code source et optimiser les processus de fabrication de semiconducteurs. Les ingénieurs ont collé du code propriétaire directement dans l’interface de chat. D’autres ont téléchargé des notes de réunion contenant des discussions de planification stratégique. En trois semaines après l’autorisation de ChatGPT pour un usage interne, l’équipe de sécurité de l’information de Samsung a identifié plusieurs instances de transmission de données confidentielles vers les serveurs d’OpenAI.
L’industrie des semiconducteurs opère avec des marges mesurées en nanomètres et des avantages concurrentiels mesurés en mois. La possibilité que les processus de fabrication de Samsung résident désormais dans le corpus d’entraînement d’OpenAI—potentiellement accessibles aux concurrents utilisant le même service—était inacceptable. Samsung a mis en œuvre une interdiction complète et a commencé à développer des outils d’IA internes qui ne transmettraient jamais de données à l’extérieur.
Réponse de l’industrie des services financiers
JPMorgan Chase a restreint l’accès à ChatGPT avant tout incident publié, reconnaissant les implications réglementaires de manière proactive. Quand les employés de banque analysent des portefeuilles clients, discutent de stratégies de fusion ou évaluent les risques de crédit, ils manipulent des informations soumises aux réglementations de la SEC, aux lois sur le secret bancaire et aux obligations fiduciaires. Transmettre de telles informations à un service d’IA tiers—indépendamment des politiques de confidentialité déclarées de ce service—crée une exposition à la conformité qu’aucun directeur juridique n’accepterait.
Goldman Sachs, Citigroup, Bank of America et Deutsche Bank ont suivi avec des restrictions similaires. La réponse coordonnée de l’industrie des services financiers ne reflétait pas la paranoïa mais la compréhension professionnelle de la responsabilité réglementaire. Une violation de données provenant de l’utilisation de ChatGPT par des employés nécessiterait une divulgation, déclencherait une enquête réglementaire et pourrait potentiellement entraîner des mesures d’application.
Implications pour l’industrie juridique
L’American Bar Association n’a pas émis d’interdiction générale sur les outils d’IA, mais l’effet pratique des exigences du secret professionnel avocat-client s’en approche. Quand un avocat discute d’affaires de clients avec ChatGPT, la conversation peut renoncer à la protection du secret. Les informations divulguées à des tiers—même des systèmes d’IA—peuvent perdre la confidentialité qui rend les conseils juridiques protégés.
De grands cabinets d’avocats incluant Davis Polk, Cravath et Sullivan & Cromwell ont mis en œuvre des restrictions allant des interdictions complètes aux politiques d’utilisation approuvée uniquement nécessitant l’autorisation d’un associé. La réponse de la profession juridique a démontré que les risques de l’IA s’étendent au-delà de la sécurité des données vers des questions fondamentales de responsabilité professionnelle.
La réalité technique du traitement des données par l’IA cloud
Comprendre pourquoi les entreprises interdisent ChatGPT nécessite d’examiner ce qui se passe réellement quand vous envoyez un message à un service d’IA cloud.
Chemin de transmission des données
Quand vous tapez un prompt dans ChatGPT, votre texte voyage depuis votre appareil à travers votre réseau d’entreprise, à travers l’internet public, jusqu’à l’infrastructure d’OpenAI. OpenAI opère principalement sur Microsoft Azure, ce qui signifie que vos données transitent par le réseau de Microsoft et résident sur des serveurs gérés par Microsoft.
Cette transmission se produit indépendamment de la sensibilité du contenu. Le système ne peut pas distinguer entre une demande d’écrire un poème et une demande d’analyser des termes de fusion confidentiels. Chaque caractère que vous saisissez suit le même chemin vers la même destination.
Politiques de rétention des données
Les politiques d’utilisation des données d’OpenAI ont évolué au fil du temps, mais certains fondamentaux restent constants. Les entrées des utilisateurs sont enregistrées. Les conversations sont stockées. La durée et le but du stockage dépendent de votre niveau d’abonnement et d’accords spécifiques.
Pour les abonnés du niveau gratuit et Plus, OpenAI se réserve explicitement le droit d’utiliser les entrées pour l’amélioration du modèle. Vos prompts deviennent des données d’entraînement. Le code confidentiel que vous avez collé pour déboguer un problème peut influencer la façon dont le modèle répond aux futurs utilisateurs—potentiellement y compris vos concurrents.
Les utilisateurs d’API et les abonnés Enterprise peuvent refuser de contribuer aux données d’entraînement, mais leurs entrées sont toujours traitées sur l’infrastructure d’OpenAI. Les données existent toujours sur des serveurs que vous ne contrôlez pas, gérés par des employés que vous n’avez pas vérifiés, soumis à des processus légaux que vous ne pouvez pas influencer.
Le problème du tiers
Les architectures de sécurité d’entreprise distinguent entre les systèmes de première partie (infrastructure que vous possédez et exploitez), les systèmes de deuxième partie (fournisseurs avec des relations contractuelles directes et des contrôles de sécurité audités), et les systèmes de troisième partie (services accessibles sans intégration de sécurité détaillée).
ChatGPT, pour la plupart des utilisateurs, opère comme un tiers non audité. À moins que votre organisation n’ait négocié un accord entreprise spécifique avec des annexes de sécurité, des droits de tests d’intrusion et des certifications de conformité mappées à vos exigences, ChatGPT se situe en dehors de votre périmètre de sécurité avec accès à toutes les données que les employés choisissent de partager.
Cette réalité architecturale explique pourquoi les équipes de sécurité traitent ChatGPT différemment de Microsoft Office ou Salesforce. Ces systèmes, bien que basés sur le cloud, opèrent sous des accords entreprise avec des contrôles de sécurité définis, des droits d’audit et des conditions de responsabilité. ChatGPT, pour un utilisateur avec un abonnement à 20 $/mois, n’offre aucune de ces protections.
Cadres réglementaires qui motivent la prudence des entreprises
Les politiques d’IA des entreprises n’existent pas dans le vide. Elles répondent à des exigences légales qui ont précédé ChatGPT et lui survivront.
RGPD et protection des données européennes
Le Règlement Général sur la Protection des Données impose des exigences strictes sur le traitement des données personnelles des résidents de l’UE. Quand un employé colle des informations clients dans ChatGPT, il initie un transfert de données vers un processeur basé aux États-Unis. Ce transfert nécessite une base légale—soit des décisions d’adéquation, des clauses contractuelles types ou des règles d’entreprise contraignantes.
Les accords de traitement des données d’OpenAI peuvent satisfaire aux exigences du RGPD pour certains cas d’utilisation, mais la plupart des employés utilisant le produit grand public n’ont pas un tel accord en place. Ils transmettent simplement des données personnelles à une société étrangère sans autorisation.
Les régulateurs italiens ont temporairement interdit ChatGPT en 2023 spécifiquement pour des préoccupations liées au RGPD. Bien que le service ait repris après qu’OpenAI ait fait des ajustements de conformité, l’incident a démontré la volonté des régulateurs d’agir. Les entreprises européennes font face à une responsabilité directe pour les actions des employés qui violent le RGPD, créant de fortes incitations pour des politiques restrictives.
HIPAA et données de santé
La loi HIPAA (Health Insurance Portability and Accountability Act) interdit la divulgation d’informations de santé protégées (PHI) sauf dans des circonstances autorisées spécifiques. Un travailleur de la santé qui discute de cas de patients avec ChatGPT divulgue des PHI à un destinataire non autorisé.
Aucun accord d’associé commercial n’existe entre les organisations de santé typiques et OpenAI. Aucun audit de sécurité n’a vérifié la conformité de ChatGPT aux garanties techniques HIPAA. Aucun cadre juridique n’autorise la divulgation.
Les organisations de santé qui découvrent que des employés ont partagé des PHI via ChatGPT font face à des exigences de notification de violation, à une enquête potentielle de l’OCR et à des pénalités atteignant 1,5 million de dollars par catégorie de violation par an. Ces conséquences expliquent pourquoi les systèmes hospitaliers bloquent ChatGPT au niveau du réseau plutôt que de s’appuyer sur la conformité aux politiques.
Réglementations financières
Les banques, courtiers et conseillers en investissement opèrent sous les réglementations de la SEC, FINRA, OCC et de la Réserve fédérale qui imposent la tenue de registres et la supervision des communications commerciales. Quand un analyste utilise ChatGPT pour rédiger de la correspondance client, cette conversation devrait être capturée dans les archives de conformité.
ChatGPT ne fournit aucune intégration avec les systèmes d’archivage d’entreprise. Aucun outil de supervision ne signale une utilisation potentiellement problématique. La conversation n’existe que sur les serveurs d’OpenAI et l’appareil de l’employé—aucun des deux ne satisfait aux exigences réglementaires de tenue de registres.
Au-delà de la tenue de registres, les régulateurs financiers expriment des préoccupations concernant les conseils d’investissement générés par l’IA, l’implication de l’IA dans les décisions de crédit et les analyses d’IA qui pourraient constituer une manipulation de marché. Le paysage réglementaire reste incertain, et les responsables de la conformité répondent à l’incertitude en restreignant l’utilisation plutôt qu’en l’autorisant en attendant des clarifications.
Réglementation émergente spécifique à l’IA
La loi européenne sur l’IA, qui devrait entrer en vigueur progressivement en 2025 et 2026, imposera des exigences supplémentaires sur le déploiement des systèmes d’IA. Les applications d’IA à haut risque—y compris celles affectant l’emploi, le crédit et l’éducation—nécessitent des évaluations de conformité, de la documentation et une supervision humaine.
Les organisations utilisant ChatGPT dans ces contextes pourraient se retrouver à exploiter des systèmes d’IA non conformes une fois les réglementations en vigueur. Les entreprises proactives restreignent l’utilisation maintenant plutôt que de faire face à une remédiation de conformité plus tard.
Propriété intellectuelle : Le risque qu’aucun contrat ne résout
La conformité réglementaire représente une catégorie de préoccupation. La protection de la propriété intellectuelle en représente une autre—et pour de nombreuses entreprises, la plus conséquente.
Secrets commerciaux et confidentialité
La protection des secrets commerciaux en vertu du Defend Trade Secrets Act et des équivalents étatiques exige que les informations restent confidentielles grâce à des mesures de protection raisonnables. Quand un employé colle des algorithmes propriétaires, des processus de fabrication ou des plans stratégiques dans ChatGPT, les mesures de protection de l’organisation ont échoué.
Les tribunaux évaluant les réclamations de secrets commerciaux examinent si la partie réclamante a pris des mesures raisonnables pour maintenir le secret. Permettre aux employés de partager des informations confidentielles avec des services d’IA tiers sape cette exigence. Même si l’information ne fuit jamais des systèmes d’OpenAI, l’acte de divulgation lui-même peut compromettre la protection juridique.
Cette préoccupation s’étend au-delà du litige hypothétique. Les entreprises font régulièrement valoir des réclamations de secrets commerciaux contre des employés partants et des concurrents. Si la découverte révèle que l’information “secrète” a été précédemment partagée avec ChatGPT—accessible à des millions d’utilisateurs via l’entraînement potentiel du modèle—la réclamation s’affaiblit substantiellement.
Code source et actifs techniques
Les entreprises de logiciels font face à une exposition particulière. Les développeurs veulent naturellement utiliser des outils d’IA pour déboguer du code, générer du code standardisé et accélérer le développement. Mais le code source représente l’actif central d’une entreprise de logiciels. Une fois transmis à ChatGPT, ce code existe en dehors du contrôle organisationnel.
La préoccupation concernant les données d’entraînement n’est pas théorique. Les grands modèles de langage apprennent de leurs entrées. Alors qu’OpenAI déclare que les clients Enterprise et API peuvent refuser de contribuer à l’entraînement, le produit grand public ne porte pas une telle garantie. Le code partagé par un développeur peut influencer les complétions montrées à un autre—potentiellement dans une entreprise concurrente.
L’avertissement interne d’Amazon aux employés a spécifiquement cité le risque que les réponses de ChatGPT puissent ressembler à des informations confidentielles d’Amazon, suggérant que des données similaires avaient déjà été incorporées dans le modèle. Que cela représente du code Amazon réel dans les données d’entraînement ou simplement des patterns similaires reste incertain. L’ambiguïté elle-même a motivé la politique restrictive.
Informations clients et consommateurs
Les cabinets de services professionnels—consultants, comptables, avocats, architectes—travaillent avec des informations clients qui appartiennent à ces clients, pas au prestataire de services. Partager des données clients avec ChatGPT peut violer les lettres de mission, les accords de confidentialité et les règles d’éthique professionnelle.
Un consultant qui télécharge les projections financières d’un client vers ChatGPT pour analyse a partagé les informations confidentielles de ce client avec un tiers. Le cabinet du consultant peut faire face à des réclamations pour rupture de contrat, des sanctions professionnelles et la perte de relations clients si cela est découvert.
Ces préoccupations s’appliquent également à toute entreprise manipulant des données clients. Un représentant commercial qui colle de la correspondance client dans ChatGPT pour rédiger une réponse a transmis des communications clients à OpenAI. Selon l’industrie et les accords applicables, cela peut violer les engagements de traitement des données clients.

L’insuffisance des accords d’IA entreprise
OpenAI propose ChatGPT Enterprise spécifiquement pour répondre aux préoccupations des entreprises. Microsoft fournit Azure OpenAI Service avec des fonctionnalités de sécurité entreprise. Ces produits améliorent les offres grand public mais n’éliminent pas les préoccupations fondamentales pour les cas d’utilisation hautement sensibles.
Ce que les accords entreprise fournissent
ChatGPT Enterprise inclut plusieurs améliorations significatives :
- Les données ne sont pas utilisées pour l’entraînement du modèle
- Certification de conformité SOC 2 Type 2
- Chiffrement des données au repos et en transit
- Intégration SSO et contrôles administratifs
- Contrôles de rétention des données
Ces fonctionnalités satisfont aux exigences pour de nombreux cas d’utilisation d’entreprise. Une équipe marketing rédigeant des textes de campagne fait face à un risque minimal. Un département de service client générant des modèles de réponse opère dans des paramètres acceptables.
Ce que les accords entreprise ne peuvent pas fournir
Pour les industries réglementées et la propriété intellectuelle sensible, les accords entreprise restent insuffisants de manières fondamentales.
Premièrement, les données sont toujours traitées sur une infrastructure que vous ne contrôlez pas. Vos informations résident sur les serveurs d’OpenAI, gérés par les employés d’OpenAI, soumis aux pratiques de sécurité d’OpenAI. Vous faites confiance à leur implémentation. Vous faites confiance à leur vérification du personnel. Vous faites confiance à leur réponse aux incidents. Cette confiance peut être justifiée, mais c’est quand même de la confiance—pas de la vérification.
Deuxièmement, les données restent soumises aux processus légaux. Une assignation servie à OpenAI pourrait contraindre la divulgation de vos conversations. Une enquête gouvernementale sur un autre client pourrait potentiellement exposer une infrastructure partagée. Les lettres de sécurité nationale et les ordonnances de la cour FISA opèrent sous des exigences de secret qui empêcheraient OpenAI de vous notifier de l’accès.
Troisièmement, la surface d’attaque inclut toute l’organisation d’OpenAI. Votre périmètre de sécurité ne se termine plus à la limite de votre réseau. Chaque employé d’OpenAI avec accès au système, chaque fournisseur avec accès à l’infrastructure, chaque vulnérabilité de sécurité dans les systèmes d’OpenAI devient partie de votre profil de risque.
Quatrièmement, la sortie et la portabilité restent contraintes. Votre historique de conversation, les comportements affinés et les connaissances organisationnelles accumulées dans ChatGPT appartiennent aux interactions avec le système d’OpenAI. La migration vers une alternative nécessite de reconstruire à partir de zéro.
Pour une entreprise pharmaceutique développant des composés nouveaux, un contractant de défense manipulant des recherches quasi-classifiées, ou une institution financière avec des algorithmes de trading représentant des milliards en valeur potentielle, ces limitations comptent. Les accords entreprise réduisent le risque. Ils ne l’éliminent pas.
L’alternative des poids ouverts
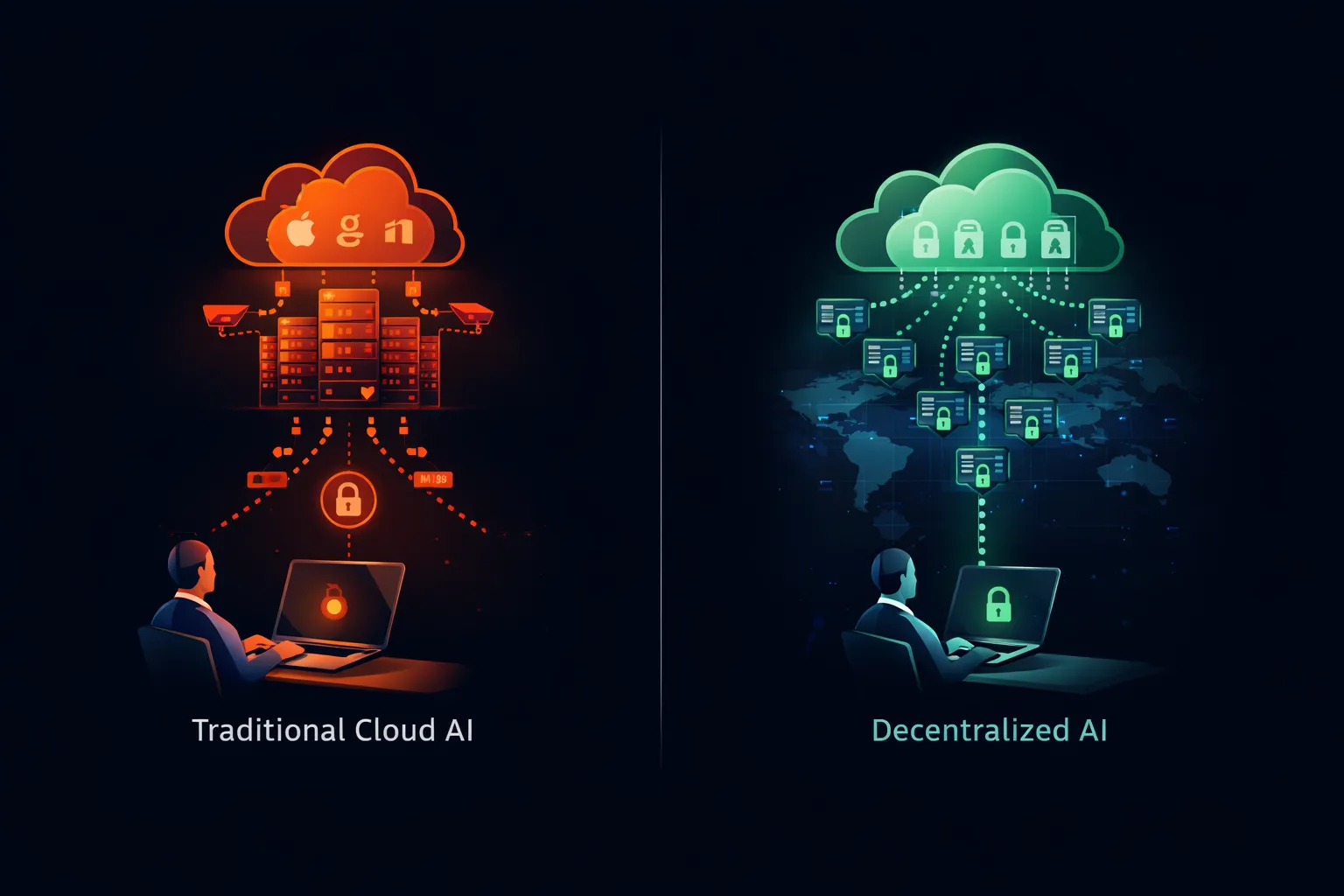
Les restrictions qui motivent les interdictions de ChatGPT en entreprise ne s’appliquent pas à l’IA en général. Elles s’appliquent spécifiquement aux services d’IA cloud où les données quittent le contrôle organisationnel. Une architecture différente élimine entièrement ces préoccupations.
Ce que les modèles à poids ouverts fournissent
Les modèles à poids ouverts—Llama de Meta, Mistral de Mistral AI, Qwen d’Alibaba et des dizaines d’autres—fournissent des fichiers de modèle téléchargeables qui s’exécutent sur n’importe quel matériel compatible. Les poids du modèle sont publics. Le code d’inférence est open source. Vous pouvez exécuter l’ensemble du système sur une infrastructure que vous possédez et exploitez.
Quand vous exécutez Llama sur votre propre serveur, vos prompts ne quittent jamais votre réseau. Aucun tiers ne reçoit vos données. Aucun service cloud n’enregistre vos requêtes. Aucun pipeline d’entraînement n’incorpore vos entrées. Le modèle s’exécute localement, traite localement et ne stocke rien au-delà de ce que vous configurez explicitement.
Cette architecture satisfait chaque préoccupation qui motive les interdictions de ChatGPT :
-
Conformité réglementaire : Les données restent dans votre périmètre de sécurité, soumises à vos contrôles, régies par vos politiques. Les transferts de données RGPD ne se produisent pas parce que les données ne sont pas transférées. Les préoccupations HIPAA se dissolvent parce qu’il n’y a pas de divulgation à des parties non autorisées.
-
Protection de la propriété intellectuelle : Les secrets commerciaux restent secrets. Le code source ne quitte jamais vos systèmes. La confidentialité client est maintenue parce qu’aucun tiers ne reçoit d’informations client.
-
Contrôle de sécurité : Votre surface d’attaque reste la vôtre. Vous vérifiez vos pratiques de sécurité. Vous vérifiez votre personnel. Vous contrôlez votre réponse aux incidents. Les vulnérabilités d’aucune organisation externe n’affectent vos données.
-
Audit et conformité : Chaque requête, chaque réponse, chaque interaction avec le modèle peut être enregistrée selon vos exigences. La tenue de registres réglementaire s’intègre à vos systèmes d’archivage existants.
Comparaison des capacités
La question naturelle est de savoir si les modèles à poids ouverts égalent les capacités de ChatGPT. La réponse honnête : cela dépend du cas d’utilisation.
Pour les requêtes de connaissances générales, l’entraînement de ChatGPT sur des données à l’échelle d’internet fournit une étendue que les modèles ouverts plus petits ne peuvent pas égaler. Les capacités de raisonnement de GPT-4 sur des problèmes complexes dépassent ce que Llama-3-8B atteint.
Mais les cas d’utilisation en entreprise nécessitent rarement des connaissances à l’échelle d’internet. Une équipe juridique analysant des contrats a besoin de compréhension de documents et de génération de langage précis—des capacités où les modèles ouverts affinés excellent. Une équipe de développement déboguant du code a besoin de reconnaissance de patterns dans des bases de code spécifiques—une tâche où l’entraînement personnalisé surpasse dramatiquement les modèles génériques.
L’insight critique est que l’affinage transforme des modèles génériques en spécialistes de domaine. Un modèle Llama-3-8B affiné sur les documents de votre organisation, vos standards de codage et vos patterns de communication surpassera GPT-4 pour vos tâches spécifiques tout en maintenant une isolation complète des données.
Notre guide pilier sur l’affinage privé de LLM sur des GPUs décentralisés fournit le workflow technique complet pour ce processus.
Options d’infrastructure pour le déploiement d’IA privée
L’exécution de modèles à poids ouverts nécessite du calcul GPU. Les organisations ont plusieurs options pour acquérir cette capacité.
Matériel sur site
L’achat de GPUs NVIDIA pour les centres de données internes fournit un contrôle maximal. Le matériel se trouve dans vos locaux, géré par votre personnel, connecté à votre réseau. Aucune partie externe n’a aucun accès.
Le défi est la dépense en capital et le délai. Un GPU NVIDIA H100 coûte environ 30 000 $. Un cluster significatif pour l’entraînement nécessite plusieurs unités. Les délais d’approvisionnement s’étendent sur des mois. La maintenance continue nécessite une expertise spécialisée.
Pour les grandes entreprises avec des opérations de centre de données existantes, l’infrastructure IA sur site représente une extension naturelle. Pour les organisations plus petites ou celles sans expertise GPU, les barrières sont substantielles.
Instances cloud privées
AWS, GCP et Azure offrent des instances GPU qui fournissent plus de contrôle que les produits IA SaaS. Vous configurez l’environnement. Vous contrôlez l’accès. Vos données sont traitées sur des instances dédiées plutôt que des services partagés.
Cette approche améliore l’architecture de ChatGPT mais conserve l’implication du fournisseur cloud. Vos données résident toujours sur une infrastructure que vous ne contrôlez pas physiquement. Les employés du fournisseur cloud avec un accès suffisant pourraient théoriquement accéder à vos systèmes. Les processus légaux servis au fournisseur cloud pourraient atteindre vos données.
De plus, les instances GPU cloud privées entraînent des coûts significatifs. Les instances AWS p4d.24xlarge (8x A100 GPUs) coûtent environ 32 $ par heure. Les exécutions d’entraînement prolongées ou les services d’inférence continus génèrent des dépenses mensuelles substantielles. La disponibilité est contrainte—les instances GPU montrent fréquemment des listes d’attente ou une disponibilité régionale limitée.
Locations de GPU décentralisées
Une troisième option contourne à la fois les dépenses en capital et l’implication du fournisseur cloud. Les marchés de GPU décentralisés connectent les utilisateurs directement avec les propriétaires de matériel. Vous louez de la capacité de calcul en peer-to-peer, payant avec des cryptomonnaies, sans vérification d’identité ni intermédiation du fournisseur cloud.
Ce modèle fournit plusieurs avantages pour les organisations soucieuses de la confidentialité :
-
Pas d’exigences KYC : Vous connectez un portefeuille et louez du matériel. Pas de comptes d’entreprise. Pas de processus de vente entreprise. Pas de documentation d’identité liant votre organisation à des activités IA spécifiques.
-
Pas d’implication de fournisseur cloud : Vos données sont traitées sur du matériel appartenant à des individus, pas à des entreprises avec des départements juridiques, des contrats gouvernementaux et des relations avec les forces de l’ordre.
-
Efficacité des coûts : Les locations de RTX 4090 coûtent de 0,40 $ à 0,60 $ par heure, environ un dixième du coût des instances cloud comparables. Notre comparaison des prix de location de GPU détaille l’économie.
-
Disponibilité mondiale : L’offre décentralisée signifie pas de contraintes régionales. Le matériel est disponible quand vous en avez besoin, distribué à travers les juridictions du monde entier.
Pour les organisations qui ne peuvent pas justifier les dépenses en capital pour du matériel GPU mais qui nécessitent des garanties de confidentialité plus fortes que ce que les fournisseurs cloud offrent, les locations décentralisées fournissent un chemin intermédiaire pratique.
Le workflow implique de transférer vos données directement vers le nœud de location via une connexion SSH chiffrée, d’exécuter votre travail d’entraînement ou d’inférence, de télécharger les résultats et d’assainir l’environnement distant avant de vous déconnecter. Notre guide sur comment sécuriser votre ensemble de données sur un nœud GPU public couvre les pratiques de sécurité opérationnelle en détail.
Mise en œuvre d’une stratégie IA conforme
Les organisations passant des interdictions de ChatGPT au déploiement d’IA privée devraient aborder la transition de manière systématique.
Phase 1 : Développement des politiques
Commencez par articuler ce que votre politique IA interdit et permet réellement. De nombreuses interdictions initiales de ChatGPT étaient réactives—des interdictions générales mises en œuvre rapidement pour arrêter le risque immédiat. Une politique mature distingue entre :
- Les catégories de données qui ne peuvent jamais être traitées par des systèmes IA externes
- Les cas d’utilisation où les services IA cloud sont acceptables avec des contrôles appropriés
- Les outils et plateformes approuvés pour différents niveaux de sensibilité
- Les processus d’approbation pour l’adoption de nouveaux outils IA
- Les exigences de signalement d’incidents pour les violations de politique
Ce cadre permet à l’utilisation de l’IA de continuer là où c’est approprié tout en protégeant les opérations sensibles.
Phase 2 : Évaluation de l’infrastructure
Évaluez vos options pour le déploiement d’IA privée en fonction des ressources et des exigences organisationnelles :
-
Ressources GPU existantes : De nombreuses organisations ont des postes de travail ou des serveurs avec des GPUs NVIDIA utilisés à d’autres fins (visualisation, rendu, calcul scientifique) qui pourraient supporter des charges de travail IA.
-
Budget cloud et tolérance au risque : Si votre équipe de sécurité accepte l’implication du fournisseur cloud avec des contrôles appropriés, les instances GPU cloud privées offrent des opérations plus simples que les options sur site ou décentralisées.
-
Exigences de confidentialité : Si votre cas d’utilisation implique des données qui ne peuvent pas toucher l’infrastructure du fournisseur cloud sous aucune circonstance, le matériel sur site ou les locations décentralisées deviennent nécessaires.
-
Échelle et fréquence : Les travaux d’affinage occasionnels conviennent aux modèles de location. Le service d’inférence continu peut justifier l’investissement en capital.
Phase 3 : Sélection et personnalisation du modèle
Les modèles à poids ouverts génériques fournissent un point de départ, mais la valeur organisationnelle vient de la personnalisation. L’affinage sur vos données crée des modèles qui comprennent votre domaine, votre terminologie et vos exigences.
Considérez quels cas d’utilisation offrent la plus haute valeur :
- Analyse de documents : Contrats juridiques, dépôts réglementaires, politiques internes
- Assistance au code : Développement dans vos frameworks et standards spécifiques
- Communication client : Réponses reflétant la voix de votre marque et les connaissances produit
- Connaissances internes : Interrogation de la documentation organisationnelle et des connaissances institutionnelles
Chaque cas d’utilisation peut justifier un modèle affiné séparé, ou un seul modèle entraîné sur des données organisationnelles diverses peut servir plusieurs objectifs.
Phase 4 : Intégration opérationnelle
Le déploiement d’IA privée nécessite des capacités opérationnelles que les produits SaaS abstraient :
-
Infrastructure de service du modèle : L’exécution de l’inférence à grande échelle nécessite des ressources GPU, l’équilibrage de charge et des interfaces API. Des outils comme vLLM, Text Generation Inference et Ollama simplifient le déploiement.
-
Contrôles d’accès : Qui peut interroger le modèle ? Quelle journalisation se produit ? Comment auditez-vous l’utilisation ?
-
Procédures de mise à jour : Comment incorporez-vous de nouvelles données d’entraînement ? Comment déployez-vous des versions de modèle améliorées ?
-
Réponse aux incidents : Que se passe-t-il si un modèle génère des sorties problématiques ? Qui examine les cas limites ?
Les organisations habituées à la simplicité du SaaS peuvent sous-estimer cette surcharge opérationnelle. Budgétisez de manière appropriée pour la maintenance continue, pas seulement pour le déploiement initial.
Étude de cas : Architecture de conformité des services financiers
Une banque régionale avec 50 milliards de dollars d’actifs a fait face à un dilemme familier. Les gestionnaires de relations voulaient une assistance IA pour rédiger des communications clients et analyser les positions de portefeuille. Les responsables de la conformité ont reconnu que la transmission de données financières clients à ChatGPT violait à la fois les exigences réglementaires et les obligations fiduciaires.
L’architecture de solution illustre comment les organisations peuvent satisfaire les deux parties.
Classification des données
La banque a établi trois niveaux de données autorisées pour l’IA :
-
Niveau 1 (Public) : Matériels marketing, contenu d’éducation financière publique, descriptions générales de produits. Services IA cloud autorisés avec des directives d’utilisation acceptable standard.
-
Niveau 2 (Interne) : Politiques internes, matériels de formation, procédures opérationnelles. Services IA cloud autorisés avec des accords entreprise et des annexes de traitement des données.
-
Niveau 3 (Restreint) : Données clients, informations de portefeuille, détails des transactions, planification stratégique. Aucun traitement IA externe sous aucune circonstance.
Cette classification a permis l’adoption de l’IA là où le risque était acceptable tout en maintenant une protection absolue pour les catégories sensibles.
Déploiement d’infrastructure privée
Pour les cas d’utilisation de Niveau 3, la banque a déployé un modèle Llama affiné sur des serveurs GPU sur site dans leur centre de données existant. Le modèle a été entraîné sur :
- Des communications clients historiques anonymisées (avec le consentement du client)
- Des directives de conformité internes et des interprétations réglementaires
- De la documentation produit et de la recherche d’investissement
- Des modèles de communication approuvés par la conformité
Le modèle résultant comprenait la terminologie bancaire, les contraintes réglementaires et les standards de communication organisationnelle. Les gestionnaires de relations pouvaient rédiger des lettres clients avec une assistance IA, sachant qu’aucune donnée client ne quittait le périmètre de sécurité de la banque.
Contrôles opérationnels
Chaque interaction avec le modèle a été journalisée dans le système d’archive de conformité existant de la banque. Les superviseurs pouvaient examiner les communications assistées par IA aux côtés de la correspondance traditionnelle. Les pistes d’audit satisfaisaient aux exigences réglementaires de tenue de registres.
Le modèle lui-même opérait dans des garde-fous empêchant certaines sorties—recommandations d’investissement, langage de garantie ou déclarations qui pourraient constituer des conseils nécessitant une licence spécifique. Ces contraintes ont été implémentées au niveau de l’application, sans s’appuyer uniquement sur le comportement du modèle.
Résultats mesurés
Six mois après le déploiement, la banque a rapporté :
- 40 % de réduction du temps consacré à la rédaction de communications clients routinières
- Zéro incident de conformité lié à l’utilisation de l’IA
- Examen réglementaire réussi sans constatations liées au déploiement de l’IA
- Augmentation des scores de satisfaction des gestionnaires de relations
L’investissement dans l’infrastructure privée—environ 200 000 $ incluant le matériel, le développement et l’intégration—a généré des retours dans la première année uniquement grâce aux gains de productivité.
Étude de cas : Institution de recherche en santé
Un grand centre médical académique menant des recherches cliniques a fait face à des contraintes HIPAA qui rendaient toute utilisation d’IA cloud avec des données de patients juridiquement problématique. Les chercheurs voulaient utiliser l’IA pour la revue de littérature, le développement de protocoles et l’analyse de données.
L’approche hybride
Plutôt que de choisir entre l’interdiction complète et le risque inacceptable, l’institution a mis en œuvre une architecture hybride :
-
Tâches de recherche publique (revue de littérature, questions de méthodologie, approches statistiques) utilisaient des services IA cloud avec des politiques claires interdisant toute entrée de données de patients.
-
Analyse des données de patients utilisait des modèles déployés localement sur des postes de travail isolés d’internet dans l’environnement de recherche sécurisé. Ces machines n’avaient pas de connectivité internet. Les données ne pouvaient pas partir indépendamment du comportement de l’utilisateur.
Entraînement décentralisé
L’institution manquait de budget en capital pour du matériel GPU capable d’entraînement mais avait besoin de modèles affinés sur la littérature médicale et les protocoles de recherche. Ils ont utilisé des locations de GPU décentralisées pour les exécutions d’entraînement en utilisant uniquement de la littérature médicale publique et des ensembles de données désidentifiés sans implications HIPAA.
Le workflow d’entraînement a suivi les pratiques de sécurité décrites dans notre guide de sécurité des ensembles de données :
- Transférer uniquement les données d’entraînement non sensibles vers les nœuds de location
- Exécuter les travaux d’affinage
- Télécharger les poids du modèle résultant
- Assainir complètement les environnements distants
- Déployer les modèles entraînés sur l’infrastructure interne isolée
Cette approche a fourni des capacités IA médicales personnalisées sans exposer aucune information de santé protégée à des systèmes externes.
Validation réglementaire
L’IRB de l’institution a examiné le déploiement de l’IA dans le cadre des amendements au protocole de recherche. La séparation claire entre l’entraînement sur données publiques (externe) et l’inférence sur données de patients (interne, isolée) a satisfait aux exigences de confidentialité. Les responsables de la conformité HIPAA ont approuvé l’architecture après évaluation de la sécurité.

L’impératif stratégique
Les organisations qui voient la politique IA uniquement à travers une lentille d’atténuation des risques manquent le tableau plus large. Les entreprises qui interdisent ChatGPT aujourd’hui n’abandonnent pas l’IA. Elles se repositionnent pour un avantage durable.
Différenciation concurrentielle par les données
Les capacités IA les plus précieuses émergent des données propriétaires. Un modèle de langage générique entraîné sur du texte internet fournit des capacités génériques disponibles pour tous. Un modèle affiné sur vos interactions clients, vos données opérationnelles et vos connaissances institutionnelles fournit des capacités uniques à votre organisation.
Cette différenciation nécessite de garder les données propriétaires propriétaires. Les organisations qui alimentent leurs avantages concurrentiels dans les services IA cloud contribuent à des modèles qui bénéficient à tous les utilisateurs—y compris les concurrents. Les organisations qui maintiennent le contrôle des données tout en déployant une IA privée accumulent des avantages qui se composent au fil du temps.
Trajectoire réglementaire
La réglementation de l’IA se durcit, pas s’assouplit. La loi européenne sur l’IA établit un précédent que d’autres juridictions suivront. Les agences américaines incluant la FTC, la SEC et les régulateurs bancaires développent des orientations spécifiques à l’IA. La Chine a mis en œuvre des réglementations IA affectant l’entraînement et le déploiement des modèles.
Les organisations qui construisent une infrastructure IA privée maintenant se préparent à des environnements réglementaires qui restreindront de plus en plus l’utilisation de l’IA cloud. L’investissement dans une architecture conforme devient plus précieux à mesure que les exigences de conformité s’intensifient.
Considérations sur la chaîne d’approvisionnement
La dépendance envers un seul fournisseur d’IA crée une vulnérabilité stratégique. Les prix, politiques et capacités d’OpenAI changent à leur discrétion. Les interruptions de service affectent tous les clients simultanément. Les changements de politique peuvent interdire du jour au lendemain des cas d’utilisation précédemment acceptables.
Le déploiement d’IA privée élimine la dépendance envers un fournisseur unique. Les modèles à poids ouverts sont téléchargeables et disponibles de manière permanente. Plusieurs options matérielles existent pour le déploiement. L’organisation contrôle sa chaîne d’approvisionnement IA plutôt que de dépendre de décisions externes.
Feuille de route de mise en œuvre
Pour les organisations prêtes à passer au-delà des interdictions de ChatGPT vers une capacité IA privée, nous recommandons une approche par phases.
Actions immédiates (Semaine 1-2)
- Auditer l’utilisation actuelle de l’IA dans toute l’organisation
- Classifier les types de données par sensibilité et exigences réglementaires
- Documenter quels cas d’utilisation nécessitent une infrastructure privée versus une utilisation cloud acceptable
- Établir une politique provisoire clarifiant les activités interdites et permises
Développement à court terme (Mois 1-3)
- Évaluer les options d’infrastructure en fonction des exigences de sensibilité et du budget
- Sélectionner les cas d’utilisation initiaux pour le déploiement d’IA privée
- Identifier les sources de données d’entraînement pour la personnalisation du modèle
- Établir des protocoles de sécurité pour l’utilisation de GPU externe si applicable
Déploiement à moyen terme (Mois 3-6)
- Affiner les modèles sur les données organisationnelles en suivant notre guide technique
- Déployer l’infrastructure d’inférence avec des contrôles d’accès appropriés
- Intégrer avec les systèmes de conformité et d’audit existants
- Former les utilisateurs aux workflows et outils approuvés
Opérations continues
- Mises à jour régulières du modèle incorporant de nouvelles données d’entraînement
- Évaluations de sécurité de l’infrastructure IA
- Mises à jour des politiques reflétant les changements réglementaires
- Extension des capacités à des cas d’utilisation supplémentaires
Conclusion
Les interdictions de ChatGPT en entreprise reflètent une gestion des risques rationnelle, pas de la technophobie. Quand Samsung a interdit l’outil après avoir découvert que des conceptions de semiconducteurs propriétaires avaient été téléchargées, ils ont pris la bonne décision. Quand JPMorgan a restreint l’accès de manière proactive, ils ont démontré une conscience réglementaire appropriée. Quand les systèmes de santé bloquent l’accès au niveau du pare-feu, ils protègent la confidentialité des patients comme l’exige la loi.
Mais l’interdiction n’est pas une stratégie. Les organisations qui s’arrêtent à “non” renoncent aux avantages de productivité que leurs concurrents captureront. Les entreprises qui prospéreront seront celles qui reconnaissent qu’un troisième chemin existe.
Les modèles à poids ouverts s’exécutant sur une infrastructure privée fournissent une capacité IA sans exposition des données. Les modèles sont disponibles maintenant. L’infrastructure est accessible. Les workflows techniques sont documentés. La seule barrière est la volonté organisationnelle de mettre en œuvre.
Vos concurrents qui affinent des modèles sur leurs données propriétaires—entraînant des systèmes qui comprennent leurs clients, leurs produits et leurs opérations—construisent des avantages que vous ne pouvez pas répliquer en vous abonnant à un service générique. Pendant que vous débattez des politiques, ils déploient des capacités.
Les décisions d’infrastructure que vous prenez aujourd’hui déterminent si l’IA devient votre avantage concurrentiel ou l’avantage de vos concurrents sur vous. Les services IA cloud transforment vos données en ressources partagées. Le déploiement d’IA privée transforme vos données en capacité unique.
Le choix n’est pas de savoir s’il faut utiliser l’IA. Le choix est de savoir s’il faut la contrôler.
Ressources connexes
Cet article aborde le contexte stratégique et réglementaire pour les décisions IA des entreprises. Les ressources suivantes fournissent des conseils de mise en œuvre technique :
Guide de mise en œuvre principal
- Le guide ultime de l’affinage privé de LLM sur des GPUs décentralisés — Workflow technique complet pour l’entraînement de modèles personnalisés
Sécurité et opérations
- Comment sécuriser votre ensemble de données sur un nœud GPU public — Pratiques de sécurité opérationnelle pour le calcul décentralisé
- Comment louer un GPU sans KYC — Workflows de location anonyme pour les déploiements sensibles à la confidentialité
Plateforme et économie
- Comparaison des prix de location de GPU 2026 — Analyse des coûts à travers les options de déploiement
- Escrow par contrat intelligent expliqué — Comment les paiements décentralisés protègent les deux parties
- Les stablecoins sont le moyen le plus intelligent de payer la location de GPU — Mécanismes de paiement pour l’infrastructure décentralisée
Comparaisons techniques
- Ollama vs vLLM vs TGI : Benchmarking des vitesses d’inférence sur GPUs grand public — Sélection de serveur d’inférence pour le déploiement
- Comparaison RunPod vs Vast.ai — Évaluation de marketplace pour les locations de GPU