
O memorando não satisfaz ninguém, mas muda tudo.
Quando a divisão de semicondutores da Samsung descobriu que engenheiros haviam enviado designs de chips proprietários para o ChatGPT, a resposta foi imediata e absoluta. Uma proibição em toda a empresa. Sem exceções. Sem processo de apelação. A ferramenta que havia se tornado sinônimo de produtividade de IA estava agora proibida em todas as redes corporativas.
A Samsung não estava sozinha. Em poucos meses, anúncios semelhantes surgiram do JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank e dezenas de outras empresas. Escritórios de advocacia que aconselham empresas da Fortune 500 proibiram associados de usar o serviço. Sistemas de saúde bloquearam o acesso no nível do firewall. Agências governamentais emitiram orientações que efetivamente acabaram com qualquer ambiguidade sobre o uso aceitável.
O padrão revelou algo que os entusiastas da tecnologia haviam ignorado em sua empolgação com as capacidades da IA: a adoção empresarial opera sob restrições que a adoção do consumidor não tem.
Este artigo examina por que as políticas corporativas de IA estão se tornando mais rigorosas, quais riscos específicos impulsionam essas decisões e como as organizações podem manter as capacidades de IA sem aceitar exposição de dados inaceitável. O caminho a seguir não requer abandonar a IA. Requer entender que a infraestrutura importa tanto quanto a inteligência.

Os incidentes que mudaram tudo
As proibições corporativas de IA não surgiram de avaliações de risco teóricas. Elas seguiram incidentes reais onde informações confidenciais escaparam do controle organizacional.
A violação de semicondutores da Samsung
No início de 2023, funcionários da Samsung Electronics usaram o ChatGPT para depurar código-fonte e otimizar processos de fabricação de semicondutores. Engenheiros colaram código proprietário diretamente na interface de chat. Outros enviaram notas de reunião contendo discussões de planejamento estratégico. Dentro de três semanas após o ChatGPT ser permitido para uso interno, a equipe de segurança da informação da Samsung identificou múltiplas instâncias de transmissão de dados confidenciais para os servidores da OpenAI.
A indústria de semicondutores opera com margens medidas em nanômetros e vantagens competitivas medidas em meses. A possibilidade de que os processos de fabricação da Samsung agora residissem no corpus de treinamento da OpenAI—potencialmente acessíveis a concorrentes usando o mesmo serviço—era inaceitável. A Samsung implementou uma proibição completa e começou a desenvolver ferramentas de IA internas que nunca transmitiriam dados externamente.
Resposta da indústria de serviços financeiros
O JPMorgan Chase restringiu o acesso ao ChatGPT antes de qualquer incidente publicado, reconhecendo proativamente as implicações regulatórias. Quando funcionários de banco analisam carteiras de clientes, discutem estratégias de fusão ou avaliam riscos de crédito, eles lidam com informações sujeitas a regulamentações da SEC, leis de sigilo bancário e deveres fiduciários. Transmitir tais informações para um serviço de IA de terceiros—independentemente das políticas de privacidade declaradas desse serviço—cria exposição de conformidade que nenhum conselho geral aceitaria.
Goldman Sachs, Citigroup, Bank of America e Deutsche Bank seguiram com restrições semelhantes. A resposta coordenada da indústria de serviços financeiros refletiu não paranoia, mas compreensão profissional da responsabilidade regulatória. Uma violação de dados originada do uso do ChatGPT por funcionários exigiria divulgação, desencadearia investigação regulatória e potencialmente resultaria em ação de execução.
Implicações para a indústria jurídica
A American Bar Association não emitiu uma proibição geral sobre ferramentas de IA, mas o efeito prático dos requisitos de privilégio advogado-cliente se aproxima disso. Quando um advogado discute assuntos de clientes com o ChatGPT, a conversa pode renunciar à proteção do privilégio. Informações divulgadas a terceiros—mesmo sistemas de IA—podem perder a confidencialidade que torna o aconselhamento jurídico protegido.
Grandes escritórios de advocacia, incluindo Davis Polk, Cravath e Sullivan & Cromwell, implementaram restrições que vão de proibições completas a políticas de uso apenas aprovado que exigem autorização de sócio. A resposta da profissão jurídica demonstrou que os riscos de IA se estendem além da segurança de dados para questões fundamentais de responsabilidade profissional.
A realidade técnica do tratamento de dados de IA em nuvem
Entender por que as empresas banem o ChatGPT requer examinar o que realmente acontece quando você envia uma mensagem para um serviço de IA em nuvem.
Caminho de transmissão de dados
Quando você digita um prompt no ChatGPT, seu texto viaja do seu dispositivo através da sua rede corporativa, pela internet pública, até a infraestrutura da OpenAI. A OpenAI opera principalmente no Microsoft Azure, o que significa que seus dados transitam pela rede da Microsoft e residem em servidores gerenciados pela Microsoft.
Essa transmissão ocorre independentemente da sensibilidade do conteúdo. O sistema não consegue distinguir entre uma solicitação para escrever um poema e uma solicitação para analisar termos de fusão confidenciais. Cada caractere que você insere segue o mesmo caminho para o mesmo destino.
Políticas de retenção de dados
As políticas de uso de dados da OpenAI evoluíram ao longo do tempo, mas certos fundamentos permanecem consistentes. As entradas dos usuários são registradas. As conversas são armazenadas. A duração e o propósito do armazenamento dependem do seu nível de assinatura e acordos específicos.
Para assinantes de nível gratuito e Plus, a OpenAI reserva explicitamente o direito de usar entradas para melhoria do modelo. Seus prompts se tornam dados de treinamento. O código confidencial que você colou para depurar um problema pode influenciar como o modelo responde a futuros usuários—potencialmente incluindo seus concorrentes.
Usuários de API e assinantes Enterprise podem optar por não contribuir com dados de treinamento, mas suas entradas ainda são processadas na infraestrutura da OpenAI. Os dados ainda existem em servidores que você não controla, gerenciados por funcionários que você não verificou, sujeitos a processos legais que você não pode influenciar.
O problema do terceiro
Arquiteturas de segurança empresarial distinguem entre sistemas de primeira parte (infraestrutura que você possui e opera), sistemas de segunda parte (fornecedores com relacionamentos contratuais diretos e controles de segurança auditados) e sistemas de terceira parte (serviços acessados sem integração de segurança detalhada).
O ChatGPT, para a maioria dos usuários, opera como um terceiro não auditado. A menos que sua organização tenha negociado um acordo empresarial específico com adendos de segurança, direitos de teste de penetração e certificações de conformidade mapeadas para seus requisitos, o ChatGPT fica fora do seu perímetro de segurança com acesso a quaisquer dados que os funcionários escolham compartilhar.
Essa realidade arquitetônica explica por que as equipes de segurança tratam o ChatGPT de forma diferente do Microsoft Office ou Salesforce. Esses sistemas, apesar de serem baseados em nuvem, operam sob acordos empresariais com controles de segurança definidos, direitos de auditoria e termos de responsabilidade. O ChatGPT, para um usuário com assinatura de $20/mês, não oferece nenhuma dessas proteções.
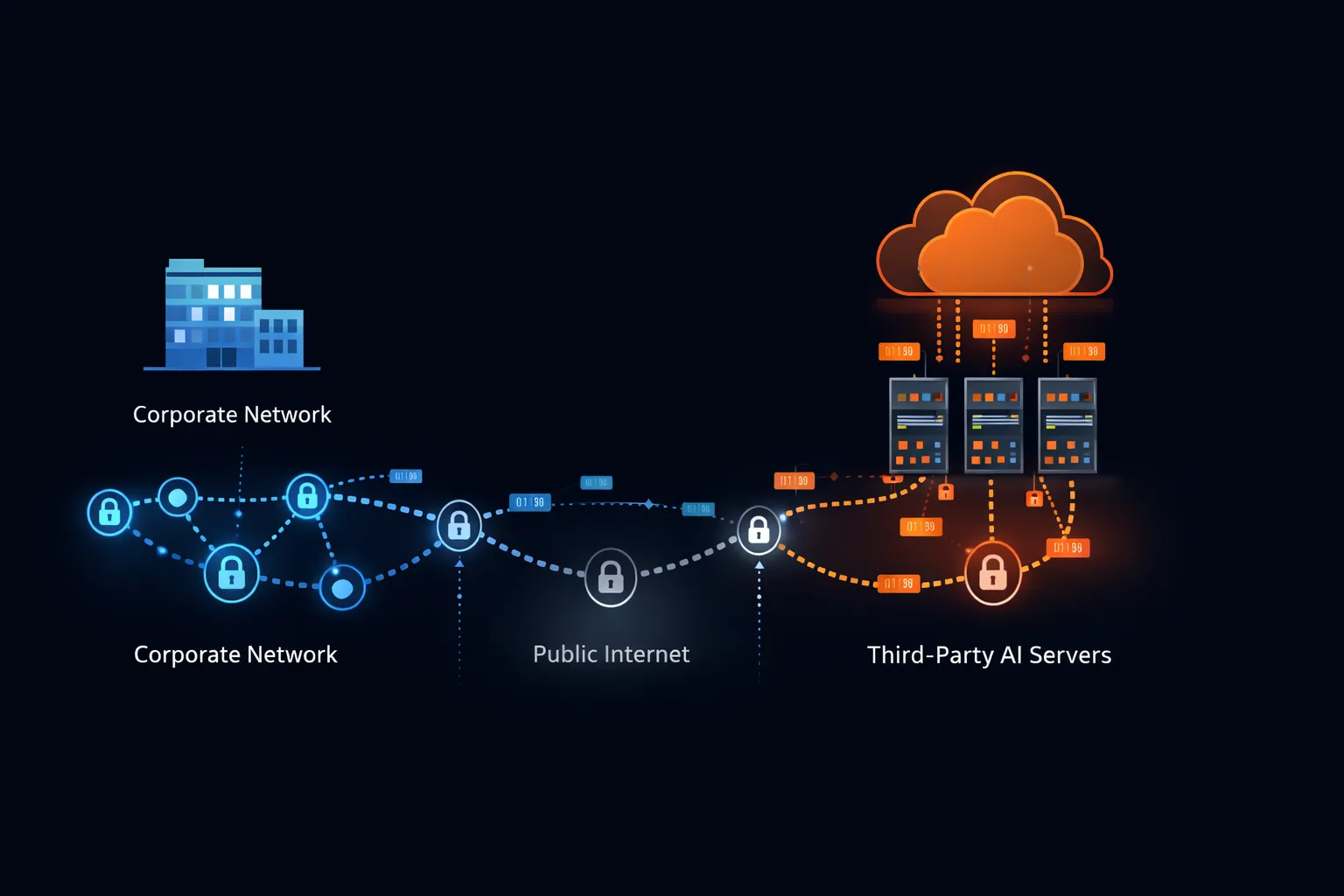
Estruturas regulatórias que impulsionam a cautela empresarial
As políticas corporativas de IA não existem no vácuo. Elas respondem a requisitos legais que antecederam o ChatGPT e o sobreviverão.
LGPD/GDPR e proteção de dados
O Regulamento Geral de Proteção de Dados e a Lei Geral de Proteção de Dados impõem requisitos rigorosos sobre o processamento de dados pessoais. Quando um funcionário cola informações de clientes no ChatGPT, ele inicia uma transferência de dados para um processador baseado nos EUA. Essa transferência requer base legal—seja decisões de adequação, cláusulas contratuais padrão ou regras corporativas vinculativas.
Os acordos de processamento de dados da OpenAI podem satisfazer os requisitos do GDPR para alguns casos de uso, mas a maioria dos funcionários que usam o produto de consumo não tem tal acordo em vigor. Eles estão simplesmente transmitindo dados pessoais para uma corporação estrangeira sem autorização.
Reguladores italianos baniram temporariamente o ChatGPT em 2023 especificamente por preocupações com o GDPR. Embora o serviço tenha sido retomado após a OpenAI fazer ajustes de conformidade, o incidente demonstrou a disposição regulatória de agir. Empresas europeias e brasileiras enfrentam responsabilidade direta por ações de funcionários que violam essas regulamentações, criando fortes incentivos para políticas restritivas.
HIPAA e dados de saúde
A Lei de Portabilidade e Responsabilidade de Seguro de Saúde proíbe a divulgação de informações de saúde protegidas (PHI) exceto em circunstâncias autorizadas específicas. Um trabalhador de saúde que discute casos de pacientes com o ChatGPT divulga PHI para um destinatário não autorizado.
Não existe acordo de associado comercial entre organizações de saúde típicas e a OpenAI. Nenhuma auditoria de segurança verificou a conformidade do ChatGPT com as salvaguardas técnicas da HIPAA. Nenhuma estrutura legal autoriza a divulgação.
Organizações de saúde que descobrem que funcionários compartilharam PHI via ChatGPT enfrentam requisitos de notificação de violação, investigação potencial do OCR e penalidades que chegam a $1,5 milhão por categoria de violação por ano. Essas consequências explicam por que sistemas hospitalares bloqueiam o ChatGPT no nível da rede em vez de confiar na conformidade com a política.
Regulamentações financeiras
Bancos, corretoras e consultores de investimento operam sob regulamentações da SEC, FINRA, OCC e Federal Reserve que exigem manutenção de registros e supervisão de comunicações comerciais. Quando um analista usa o ChatGPT para redigir correspondência com clientes, essa conversa deve ser capturada nos arquivos de conformidade.
O ChatGPT não fornece integração com sistemas de arquivamento empresarial. Nenhuma ferramenta de supervisão sinaliza uso potencialmente problemático. A conversa existe apenas nos servidores da OpenAI e no dispositivo do funcionário—nenhum dos quais satisfaz os requisitos regulatórios de manutenção de registros.
Além da manutenção de registros, reguladores financeiros expressam preocupação com aconselhamento de investimento gerado por IA, envolvimento de IA em decisões de crédito e análise de IA que poderia constituir manipulação de mercado. O cenário regulatório permanece incerto, e oficiais de conformidade respondem à incerteza restringindo o uso em vez de permitir enquanto aguardam clareza.
Regulamentação emergente específica de IA
O AI Act da UE, que deve entrar em vigor progressivamente em 2025 e 2026, imporá requisitos adicionais sobre a implantação de sistemas de IA. Aplicações de IA de alto risco—incluindo aquelas que afetam emprego, crédito e educação—requerem avaliações de conformidade, documentação e supervisão humana.
Organizações que usam o ChatGPT nesses contextos podem encontrar-se operando sistemas de IA não conformes uma vez que as regulamentações entrarem em vigor. Empresas proativas estão restringindo o uso agora em vez de enfrentar remediação de conformidade depois.
Propriedade intelectual: O risco que nenhum contrato resolve
A conformidade regulatória representa uma categoria de preocupação. A proteção de propriedade intelectual representa outra—e para muitas empresas, a mais consequente.
Segredos comerciais e confidencialidade
A proteção de segredos comerciais sob o Defend Trade Secrets Act e equivalentes estaduais exige que as informações permaneçam confidenciais através de medidas de proteção razoáveis. Quando um funcionário cola algoritmos proprietários, processos de fabricação ou planos estratégicos no ChatGPT, as medidas de proteção da organização falharam.
Tribunais que avaliam reivindicações de segredos comerciais examinam se a parte reivindicante tomou medidas razoáveis para manter o sigilo. Permitir que funcionários compartilhem informações confidenciais com serviços de IA de terceiros mina esse requisito. Mesmo que as informações nunca vazem dos sistemas da OpenAI, o ato de divulgação em si pode comprometer a proteção legal.
Essa preocupação se estende além do litígio hipotético. As empresas regularmente afirmam reivindicações de segredos comerciais contra funcionários que saem e concorrentes. Se a descoberta revelar que a informação “secreta” foi previamente compartilhada com o ChatGPT—acessível a milhões de usuários através de potencial treinamento do modelo—a reivindicação enfraquece substancialmente.
Código-fonte e ativos técnicos
Empresas de software enfrentam exposição particular. Desenvolvedores naturalmente querem usar ferramentas de IA para depurar código, gerar boilerplate e acelerar o desenvolvimento. Mas o código-fonte representa o ativo central de um negócio de software. Uma vez transmitido para o ChatGPT, esse código existe fora do controle organizacional.
A preocupação com dados de treinamento não é teórica. Modelos de linguagem grande aprendem com suas entradas. Enquanto a OpenAI afirma que clientes Enterprise e API podem optar por não contribuir com treinamento, o produto de consumo não oferece tal garantia. O código compartilhado por um desenvolvedor pode influenciar completions mostradas a outro—potencialmente em uma empresa concorrente.
O aviso interno da Amazon aos funcionários citou especificamente o risco de que as respostas do ChatGPT pudessem se assemelhar a informações confidenciais da Amazon, sugerindo que dados semelhantes já haviam sido incorporados ao modelo. Se isso representava código real da Amazon nos dados de treinamento ou simplesmente padrões semelhantes permanece incerto. A ambiguidade em si impulsionou a política restritiva.
Informações de clientes e consumidores
Firmas de serviços profissionais—consultores, contadores, advogados, arquitetos—trabalham com informações de clientes que pertencem a esses clientes, não ao provedor de serviços. Compartilhar dados de clientes com o ChatGPT pode violar cartas de engajamento, acordos de confidencialidade e regras de ética profissional.
Um consultor que envia projeções financeiras de um cliente para o ChatGPT para análise compartilhou as informações confidenciais desse cliente com um terceiro. A firma do consultor pode enfrentar reivindicações de violação de contrato, disciplina profissional e perda de relacionamentos com clientes se descoberto.
Essas preocupações se aplicam igualmente a qualquer negócio que lida com dados de clientes. Um representante de vendas que cola correspondência de clientes no ChatGPT para redigir uma resposta transmitiu comunicações de clientes para a OpenAI. Dependendo da indústria e acordos aplicáveis, isso pode violar compromissos de tratamento de dados de clientes.

A inadequação dos acordos empresariais de IA
A OpenAI oferece o ChatGPT Enterprise especificamente para abordar preocupações corporativas. A Microsoft fornece o Azure OpenAI Service com recursos de segurança empresarial. Esses produtos melhoram em relação às ofertas de consumo, mas não eliminam preocupações fundamentais para casos de uso de alta sensibilidade.
O que os acordos empresariais fornecem
O ChatGPT Enterprise inclui várias melhorias significativas:
- Os dados não são usados para treinamento do modelo
- Certificação de conformidade SOC 2 Type 2
- Criptografia de dados em repouso e em trânsito
- Integração SSO e controles administrativos
- Controles de retenção de dados
Esses recursos satisfazem os requisitos para muitos casos de uso corporativo. Uma equipe de marketing redigindo texto de campanha enfrenta risco mínimo. Um departamento de atendimento ao cliente gerando modelos de resposta opera dentro de parâmetros aceitáveis.
O que os acordos empresariais não podem fornecer
Para indústrias regulamentadas e propriedade intelectual sensível, os acordos empresariais ficam aquém de maneiras fundamentais.
Primeiro, os dados ainda são processados em infraestrutura que você não controla. Suas informações residem em servidores da OpenAI, gerenciados por funcionários da OpenAI, sujeitos às práticas de segurança da OpenAI. Você confia na implementação deles. Confia na verificação de pessoal deles. Confia na resposta a incidentes deles. Essa confiança pode ser justificada, mas é confiança mesmo assim—não verificação.
Segundo, os dados permanecem sujeitos a processo legal. Uma intimação servida à OpenAI poderia obrigar a divulgação de suas conversas. Uma investigação governamental sobre outro cliente poderia potencialmente expor infraestrutura compartilhada. Cartas de segurança nacional e ordens do tribunal FISA operam sob requisitos de sigilo que impediriam a OpenAI de notificá-lo sobre o acesso.
Terceiro, a superfície de ataque inclui toda a organização da OpenAI. Seu perímetro de segurança não termina mais no limite da sua rede. Cada funcionário da OpenAI com acesso ao sistema, cada fornecedor com acesso à infraestrutura, cada vulnerabilidade de segurança nos sistemas da OpenAI se torna parte do seu perfil de risco.
Quarto, saída e portabilidade permanecem restritas. Seu histórico de conversas, comportamentos ajustados e conhecimento organizacional acumulado no ChatGPT pertencem a interações com o sistema da OpenAI. A migração para uma alternativa requer reconstruir do zero.
Para uma empresa farmacêutica desenvolvendo compostos novos, um contratante de defesa lidando com pesquisa quase classificada, ou uma instituição financeira com algoritmos de negociação representando bilhões em valor potencial, essas limitações importam. Acordos empresariais reduzem o risco. Eles não o eliminam.
A alternativa de pesos abertos
As restrições que impulsionam as proibições corporativas do ChatGPT não se aplicam à IA em geral. Elas se aplicam especificamente a serviços de IA em nuvem onde os dados deixam o controle organizacional. Uma arquitetura diferente elimina essas preocupações inteiramente.
O que os modelos de pesos abertos fornecem
Modelos de pesos abertos—Llama da Meta, Mistral da Mistral AI, Qwen da Alibaba e dezenas de outros—fornecem arquivos de modelo para download que rodam em qualquer hardware compatível. Os pesos do modelo são públicos. O código de inferência é open source. Você pode executar o sistema inteiro em infraestrutura que você possui e opera.
Quando você roda o Llama no seu próprio servidor, seus prompts nunca deixam sua rede. Nenhum terceiro recebe seus dados. Nenhum serviço de nuvem registra suas consultas. Nenhum pipeline de treinamento incorpora suas entradas. O modelo roda localmente, processa localmente e não armazena nada além do que você configura explicitamente.
Essa arquitetura satisfaz toda preocupação que impulsiona as proibições do ChatGPT:
-
Conformidade regulatória: Os dados permanecem dentro do seu perímetro de segurança, sujeitos aos seus controles, governados pelas suas políticas. Transferências de dados LGPD/GDPR não ocorrem porque os dados não são transferidos. Preocupações com HIPAA se dissolvem porque não há divulgação para partes não autorizadas.
-
Proteção de propriedade intelectual: Segredos comerciais permanecem secretos. O código-fonte nunca deixa seus sistemas. A confidencialidade do cliente é mantida porque nenhum terceiro recebe informações do cliente.
-
Controle de segurança: Sua superfície de ataque permanece sua. Você verifica suas práticas de segurança. Você verifica seu pessoal. Você controla sua resposta a incidentes. As vulnerabilidades de nenhuma organização externa afetam seus dados.
-
Auditoria e conformidade: Cada consulta, cada resposta, cada interação com o modelo pode ser registrada de acordo com seus requisitos. A manutenção de registros regulatórios se integra com seus sistemas de arquivo existentes.
Comparação de capacidades
A pergunta natural é se os modelos de pesos abertos correspondem às capacidades do ChatGPT. A resposta honesta: depende do caso de uso.
Para consultas de conhecimento geral, o treinamento do ChatGPT em dados de escala de internet fornece amplitude que modelos abertos menores não podem igualar. As capacidades de raciocínio do GPT-4 em problemas complexos excedem o que o Llama-3-8B alcança.
Mas casos de uso empresarial raramente requerem conhecimento de escala de internet. Uma equipe jurídica analisando contratos precisa de compreensão de documentos e geração de linguagem precisa—capacidades onde modelos abertos com fine-tuning se destacam. Uma equipe de desenvolvimento depurando código precisa de reconhecimento de padrões dentro de bases de código específicas—uma tarefa onde o treinamento personalizado supera dramaticamente os modelos genéricos.
O insight crítico é que o fine-tuning transforma modelos genéricos em especialistas de domínio. Um modelo Llama-3-8B com fine-tuning nos documentos da sua organização, padrões de codificação e padrões de comunicação superará o GPT-4 para suas tarefas específicas enquanto mantém isolamento completo de dados.
Nosso guia principal sobre fine-tuning privado de LLM em GPUs descentralizadas fornece o fluxo de trabalho técnico completo para esse processo.
Opções de infraestrutura para implantação de IA privada
Executar modelos de pesos abertos requer computação GPU. As organizações têm várias opções para adquirir essa capacidade.
Hardware on-premises
Comprar GPUs NVIDIA para data centers internos fornece controle máximo. O hardware fica nas suas instalações, gerenciado pela sua equipe, conectado à sua rede. Nenhuma parte externa tem qualquer acesso.
O desafio é o gasto de capital e o tempo de entrega. Uma GPU NVIDIA H100 custa aproximadamente $30.000. Um cluster significativo para treinamento requer múltiplas unidades. Os prazos de aquisição se estendem por meses. A manutenção contínua requer expertise especializada.
Para grandes empresas com operações de data center existentes, a infraestrutura de IA on-premises representa uma extensão natural. Para organizações menores ou aquelas sem expertise em GPU, as barreiras são substanciais.
Instâncias de nuvem privada
AWS, GCP e Azure oferecem instâncias GPU que fornecem mais controle do que produtos de IA SaaS. Você configura o ambiente. Você controla o acesso. Seus dados são processados em instâncias dedicadas em vez de serviços compartilhados.
Essa abordagem melhora a arquitetura do ChatGPT, mas mantém o envolvimento do provedor de nuvem. Seus dados ainda residem em infraestrutura que você não controla fisicamente. Funcionários do provedor de nuvem com acesso suficiente poderiam teoricamente acessar seus sistemas. O processo legal servido ao provedor de nuvem poderia alcançar seus dados.
Além disso, instâncias GPU de nuvem privada têm custos significativos. Instâncias AWS p4d.24xlarge (8x A100 GPUs) rodam aproximadamente $32 por hora. Execuções de treinamento estendidas ou serviços de inferência contínuos geram despesas mensais substanciais. A disponibilidade é restrita—instâncias GPU frequentemente mostram listas de espera ou disponibilidade regional limitada.
Aluguéis de GPU descentralizados
Uma terceira opção contorna tanto o gasto de capital quanto o envolvimento do provedor de nuvem. Marketplaces de GPU descentralizados conectam usuários diretamente com proprietários de hardware. Você aluga capacidade de computação peer-to-peer, pagando com criptomoeda, sem verificação de identidade ou intermediação de provedor de nuvem.
Esse modelo fornece várias vantagens para organizações conscientes de privacidade:
-
Sem requisitos KYC: Você conecta uma carteira e aluga hardware. Sem contas corporativas. Sem processo de vendas empresariais. Sem documentação de identidade vinculando sua organização a atividades específicas de IA.
-
Sem envolvimento de provedor de nuvem: Seus dados são processados em hardware de propriedade de indivíduos, não de corporações com departamentos jurídicos, contratos governamentais e relacionamentos com autoridades.
-
Eficiência de custo: Aluguéis de RTX 4090 custam $0,40 a $0,60 por hora, aproximadamente um décimo do custo de instâncias de nuvem comparáveis. Nossa comparação de preços de aluguel de GPU detalha a economia.
-
Disponibilidade global: Fornecimento descentralizado significa sem restrições regionais. Hardware está disponível quando você precisa, distribuído em jurisdições em todo o mundo.
Para organizações que não podem justificar gastos de capital em hardware GPU, mas requerem garantias de privacidade mais fortes do que os provedores de nuvem oferecem, aluguéis descentralizados fornecem um caminho intermediário prático.
O fluxo de trabalho envolve transferir seus dados diretamente para o nó de aluguel via conexão SSH criptografada, executar seu trabalho de treinamento ou inferência, baixar resultados e sanitizar o ambiente remoto antes de desconectar. Nosso guia sobre como proteger seu dataset em um nó GPU público cobre as práticas de segurança operacional em detalhes.
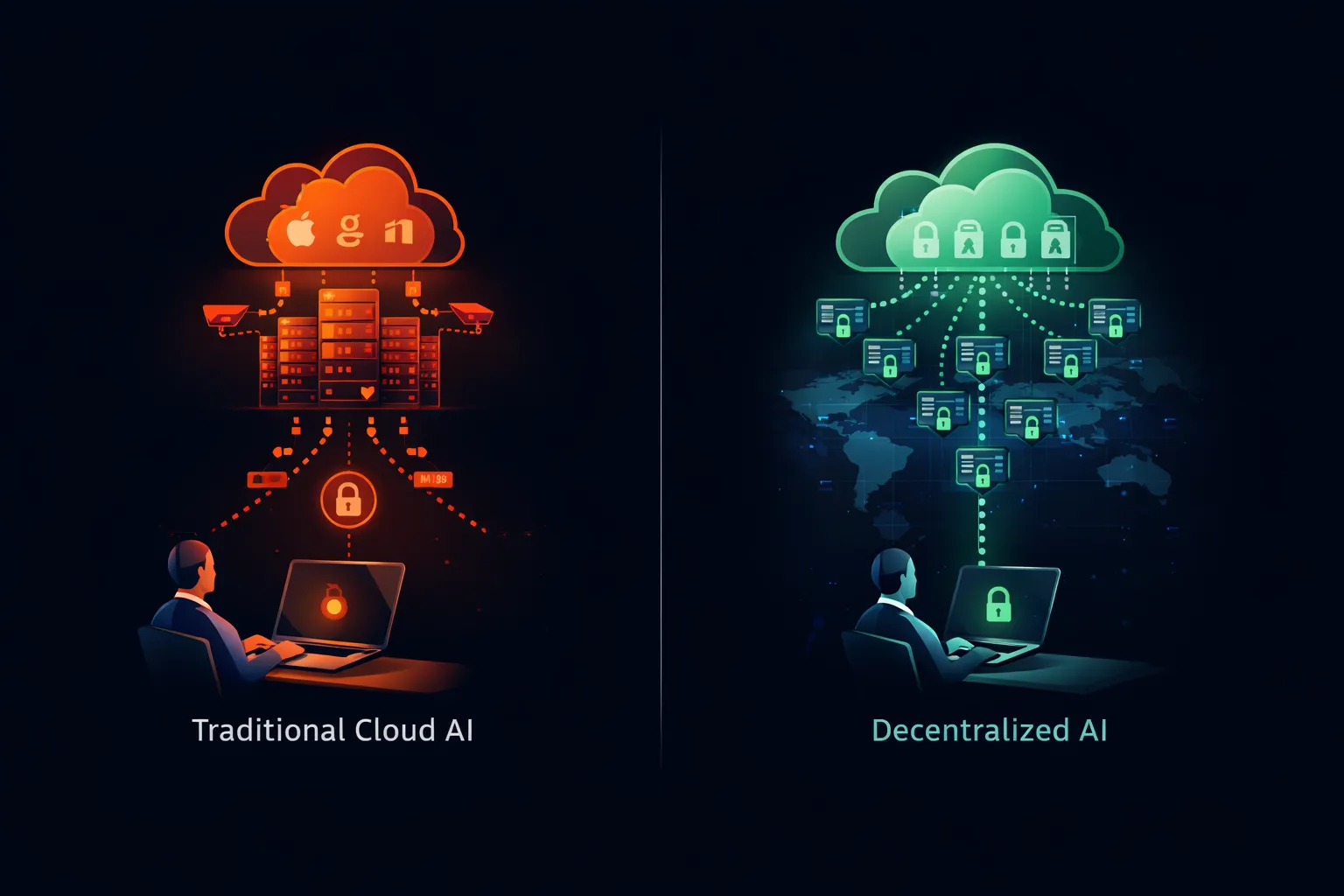
Implementando uma estratégia de IA em conformidade
Organizações que estão migrando de proibições do ChatGPT para implantação de IA privada devem abordar a transição sistematicamente.
Fase 1: Desenvolvimento de políticas
Comece articulando o que sua política de IA realmente proíbe e permite. Muitas proibições iniciais do ChatGPT foram reativas—proibições gerais implementadas rapidamente para parar o risco imediato. Uma política madura distingue entre:
- Categorias de dados que nunca podem ser processadas por sistemas de IA externos
- Casos de uso onde serviços de IA em nuvem são aceitáveis com controles apropriados
- Ferramentas e plataformas aprovadas para diferentes níveis de sensibilidade
- Processos de aprovação para adoção de novas ferramentas de IA
- Requisitos de relatório de incidentes para violações de política
Essa estrutura permite que o uso de IA continue onde apropriado enquanto protege operações sensíveis.
Fase 2: Avaliação de infraestrutura
Avalie suas opções para implantação de IA privada com base em recursos e requisitos organizacionais:
-
Recursos GPU existentes: Muitas organizações têm estações de trabalho ou servidores com GPUs NVIDIA usadas para outros fins (visualização, renderização, computação científica) que poderiam suportar cargas de trabalho de IA.
-
Orçamento de nuvem e tolerância a risco: Se sua equipe de segurança aceita o envolvimento do provedor de nuvem com controles apropriados, instâncias GPU de nuvem privada oferecem operações mais simples do que opções on-premises ou descentralizadas.
-
Requisitos de privacidade: Se seu caso de uso envolve dados que não podem tocar infraestrutura de provedor de nuvem sob nenhuma circunstância, hardware on-premises ou aluguéis descentralizados se tornam necessários.
-
Escala e frequência: Trabalhos ocasionais de fine-tuning se adequam a modelos de aluguel. Serviço de inferência contínuo pode justificar investimento de capital.
Fase 3: Seleção e personalização de modelo
Modelos de pesos abertos genéricos fornecem um ponto de partida, mas o valor organizacional vem da personalização. Fine-tuning nos seus dados cria modelos que entendem seu domínio, sua terminologia e seus requisitos.
Considere quais casos de uso oferecem maior valor:
- Análise de documentos: Contratos legais, arquivos regulatórios, políticas internas
- Assistência de código: Desenvolvimento dentro de seus frameworks e padrões específicos
- Comunicação com clientes: Respostas refletindo a voz da sua marca e conhecimento do produto
- Conhecimento interno: Consulta de documentação organizacional e conhecimento institucional
Cada caso de uso pode justificar um modelo com fine-tuning separado, ou um único modelo treinado em dados organizacionais diversos pode servir múltiplos propósitos.
Fase 4: Integração operacional
A implantação de IA privada requer capacidades operacionais que produtos SaaS abstraem:
-
Infraestrutura de serving de modelo: Executar inferência em escala requer recursos GPU, balanceamento de carga e interfaces API. Ferramentas como vLLM, Text Generation Inference e Ollama simplificam a implantação.
-
Controles de acesso: Quem pode consultar o modelo? Que registro ocorre? Como você audita o uso?
-
Procedimentos de atualização: Como você incorpora novos dados de treinamento? Como você implanta versões de modelo aprimoradas?
-
Resposta a incidentes: O que acontece se um modelo gerar saída problemática? Quem revisa casos extremos?
Organizações acostumadas à simplicidade do SaaS podem subestimar essa sobrecarga operacional. Faça o orçamento apropriadamente para manutenção contínua, não apenas para a implantação inicial.
Estudo de caso: Arquitetura de conformidade de serviços financeiros
Um banco regional com $50 bilhões em ativos enfrentou um dilema familiar. Gerentes de relacionamento queriam assistência de IA para redigir comunicações com clientes e analisar posições de carteira. Oficiais de conformidade reconheceram que transmitir dados financeiros de clientes para o ChatGPT violava tanto os requisitos regulatórios quanto os deveres fiduciários.
A arquitetura da solução ilustra como as organizações podem satisfazer ambos os lados.
Classificação de dados
O banco estabeleceu três níveis de dados permissíveis para IA:
-
Nível 1 (Público): Materiais de marketing, conteúdo de educação financeira pública, descrições gerais de produtos. Serviços de IA em nuvem permitidos com diretrizes de uso aceitável padrão.
-
Nível 2 (Interno): Políticas internas, materiais de treinamento, procedimentos operacionais. Serviços de IA em nuvem permitidos com acordos empresariais e adendos de tratamento de dados.
-
Nível 3 (Restrito): Dados de clientes, informações de carteira, detalhes de transações, planejamento estratégico. Nenhum processamento de IA externo sob nenhuma circunstância.
Essa classificação permitiu a adoção de IA onde o risco era aceitável enquanto mantinha proteção absoluta para categorias sensíveis.
Implantação de infraestrutura privada
Para casos de uso de Nível 3, o banco implantou um modelo Llama com fine-tuning em servidores GPU on-premises dentro de seu data center existente. O modelo foi treinado em:
- Comunicações históricas de clientes anonimizadas (com consentimento do cliente)
- Diretrizes de conformidade internas e interpretações regulatórias
- Documentação de produtos e pesquisa de investimentos
- Modelos de comunicação aprovados por conformidade
O modelo resultante entendia terminologia bancária, restrições regulatórias e padrões de comunicação organizacional. Gerentes de relacionamento podiam redigir cartas de clientes com assistência de IA, sabendo que nenhum dado de cliente deixava o perímetro de segurança do banco.
Controles operacionais
Cada interação com o modelo foi registrada no sistema de arquivo de conformidade existente do banco. Supervisores podiam revisar comunicações assistidas por IA junto com correspondência tradicional. Trilhas de auditoria satisfizeram os requisitos regulatórios de manutenção de registros.
O modelo em si operava dentro de guard-rails que impediam certas saídas—recomendações de investimento, linguagem de garantia ou declarações que poderiam constituir aconselhamento exigindo licenciamento específico. Essas restrições foram implementadas na camada de aplicação, não dependendo apenas do comportamento do modelo.
Resultados medidos
Seis meses após a implantação, o banco relatou:
- 40% de redução no tempo gasto redigindo comunicações rotineiras com clientes
- Zero incidentes de conformidade relacionados ao uso de IA
- Exame regulatório bem-sucedido sem descobertas relacionadas à implantação de IA
- Aumento nas pontuações de satisfação dos gerentes de relacionamento
O investimento em infraestrutura privada—aproximadamente $200.000 incluindo hardware, desenvolvimento e integração—gerou retornos dentro do primeiro ano apenas através de ganhos de produtividade.
Estudo de caso: Instituição de pesquisa em saúde
Um grande centro médico acadêmico conduzindo pesquisa clínica enfrentou restrições HIPAA que tornavam qualquer uso de IA em nuvem com dados de pacientes legalmente problemático. Pesquisadores queriam usar IA para revisão de literatura, desenvolvimento de protocolo e análise de dados.
A abordagem híbrida
Em vez de escolher entre proibição completa e risco inaceitável, a instituição implementou uma arquitetura híbrida:
-
Tarefas de pesquisa pública (revisão de literatura, questões de metodologia, abordagens estatísticas) usaram serviços de IA em nuvem com políticas claras proibindo qualquer entrada de dados de pacientes.
-
Análise de dados de pacientes usou modelos implantados localmente em estações de trabalho air-gapped dentro do ambiente de pesquisa seguro. Essas máquinas não tinham conectividade com a internet. Os dados não podiam sair independentemente do comportamento do usuário.
Treinamento descentralizado
A instituição não tinha orçamento de capital para hardware GPU capaz de treinamento, mas precisava de modelos com fine-tuning em literatura médica e protocolos de pesquisa. Eles utilizaram aluguéis de GPU descentralizados para execuções de treinamento usando apenas literatura médica pública e datasets desidentificados sem implicações HIPAA.
O fluxo de trabalho de treinamento seguiu as práticas de segurança descritas em nosso guia de segurança de dataset:
- Transferir apenas dados de treinamento não sensíveis para nós de aluguel
- Executar trabalhos de fine-tuning
- Baixar os pesos do modelo resultantes
- Sanitizar completamente os ambientes remotos
- Implantar modelos treinados em infraestrutura interna air-gapped
Essa abordagem forneceu capacidades de IA médica personalizadas sem expor qualquer informação de saúde protegida a sistemas externos.
Validação regulatória
O IRB da instituição revisou a implantação de IA como parte das emendas ao protocolo de pesquisa. A clara separação entre treinamento de dados públicos (externo) e inferência de dados de pacientes (interno, air-gapped) satisfez os requisitos de privacidade. Oficiais de conformidade HIPAA aprovaram a arquitetura após avaliação de segurança.

O imperativo estratégico
Organizações que veem a política de IA apenas através de uma lente de mitigação de risco perdem o quadro maior. As empresas que estão banindo o ChatGPT hoje não estão abandonando a IA. Elas estão se reposicionando para vantagem sustentável.
Diferenciação competitiva através de dados
As capacidades de IA mais valiosas emergem de dados proprietários. Um modelo de linguagem genérico treinado em texto da internet fornece capacidades genéricas disponíveis para todos. Um modelo com fine-tuning nas suas interações com clientes, seus dados operacionais e seu conhecimento institucional fornece capacidades únicas para sua organização.
Essa diferenciação requer manter dados proprietários como proprietários. Organizações que alimentam suas vantagens competitivas em serviços de IA em nuvem contribuem para modelos que beneficiam todos os usuários—incluindo concorrentes. Organizações que mantêm controle de dados enquanto implantam IA privada acumulam vantagens que se compõem ao longo do tempo.
Trajetória regulatória
A regulamentação de IA está se tornando mais rigorosa, não mais frouxa. O AI Act da UE estabelece precedentes que outras jurisdições seguirão. Agências americanas incluindo FTC, SEC e reguladores bancários estão desenvolvendo orientações específicas de IA. A China implementou regulamentações de IA afetando treinamento e implantação de modelos.
Organizações que constroem infraestrutura de IA privada agora estão se preparando para ambientes regulatórios que restringirão cada vez mais o uso de IA em nuvem. O investimento em arquitetura de conformidade se torna mais valioso à medida que os requisitos de conformidade se intensificam.
Considerações de cadeia de suprimentos
A dependência de um único provedor de IA cria vulnerabilidade estratégica. Os preços, políticas e capacidades da OpenAI mudam a seu critério. Interrupções de serviço afetam todos os clientes simultaneamente. Mudanças de política podem proibir casos de uso anteriormente aceitáveis da noite para o dia.
A implantação de IA privada elimina a dependência de fornecedor único. Modelos de pesos abertos são baixáveis e permanentemente disponíveis. Múltiplas opções de hardware existem para implantação. A organização controla sua cadeia de suprimentos de IA em vez de depender de decisões externas.
Roteiro de implementação
Para organizações prontas para ir além das proibições do ChatGPT em direção à capacidade de IA privada, recomendamos uma abordagem em fases.
Ações imediatas (Semana 1-2)
- Auditar o uso atual de IA em toda a organização
- Classificar tipos de dados por sensibilidade e requisitos regulatórios
- Documentar quais casos de uso requerem infraestrutura privada versus uso de nuvem aceitável
- Estabelecer política provisória esclarecendo atividades proibidas e permitidas
Desenvolvimento de curto prazo (Mês 1-3)
- Avaliar opções de infraestrutura com base em requisitos de sensibilidade e orçamento
- Selecionar casos de uso iniciais para implantação de IA privada
- Identificar fontes de dados de treinamento para personalização de modelo
- Estabelecer protocolos de segurança para uso de GPU externo, se aplicável
Implantação de médio prazo (Mês 3-6)
- Fazer fine-tuning de modelos em dados organizacionais seguindo nosso guia técnico
- Implantar infraestrutura de inferência com controles de acesso apropriados
- Integrar com sistemas de conformidade e auditoria existentes
- Treinar usuários em fluxos de trabalho e ferramentas aprovados
Operações contínuas
- Atualizações regulares de modelo incorporando novos dados de treinamento
- Avaliações de segurança da infraestrutura de IA
- Atualizações de política refletindo mudanças regulatórias
- Expansão de capacidade para casos de uso adicionais
Conclusão
As proibições corporativas do ChatGPT refletem gerenciamento de risco racional, não tecnofobia. Quando a Samsung proibiu a ferramenta após descobrir que designs de semicondutores proprietários haviam sido enviados, eles tomaram a decisão correta. Quando o JPMorgan restringiu o acesso proativamente, eles demonstraram consciência regulatória apropriada. Quando sistemas de saúde bloqueiam o acesso no nível do firewall, eles protegem a privacidade do paciente conforme exigido por lei.
Mas proibição não é estratégia. Organizações que param no “não” renunciam às vantagens de produtividade que seus concorrentes capturarão. As empresas que prosperarão serão aquelas que reconhecem que existe um terceiro caminho.
Modelos de pesos abertos rodando em infraestrutura privada fornecem capacidade de IA sem exposição de dados. Os modelos estão disponíveis agora. A infraestrutura é acessível. Os fluxos de trabalho técnicos estão documentados. A única barreira é a vontade organizacional de implementar.
Seus concorrentes que estão fazendo fine-tuning de modelos em seus dados proprietários—treinando sistemas que entendem seus clientes, seus produtos e suas operações—estão construindo vantagens que você não pode replicar assinando um serviço genérico. Enquanto você debate política, eles estão implantando capacidade.
As decisões de infraestrutura que você toma hoje determinam se a IA se torna sua vantagem competitiva ou a vantagem dos seus concorrentes sobre você. Serviços de IA em nuvem transformam seus dados em recursos compartilhados. A implantação de IA privada transforma seus dados em capacidade única.
A escolha não é se deve usar IA. A escolha é se deve controlá-la.
Recursos relacionados
Este artigo aborda o contexto estratégico e regulatório para decisões corporativas de IA. Os seguintes recursos fornecem orientação de implementação técnica:
Guia de implementação principal
- O guia definitivo para fine-tuning privado de LLM em GPUs descentralizadas — Fluxo de trabalho técnico completo para treinar modelos personalizados
Segurança e operações
- Como proteger seu dataset em um nó GPU público — Práticas de segurança operacional para computação descentralizada
- Como alugar uma GPU sem KYC — Fluxos de trabalho de aluguel anônimo para implantações sensíveis à privacidade
Plataforma e economia
- Comparação de preços de aluguel de GPU 2026 — Análise de custos entre opções de implantação
- Escrow de contrato inteligente explicado — Como pagamentos descentralizados protegem ambas as partes
- Stablecoins são a forma mais inteligente de pagar por aluguel de GPU — Mecânicas de pagamento para infraestrutura descentralizada
Comparações técnicas
- Ollama vs vLLM vs TGI: Benchmarking de velocidades de inferência em GPUs de consumidor — Seleção de servidor de inferência para implantação
- Comparação RunPod vs Vast.ai — Avaliação de marketplace para aluguéis de GPU