
Служебная записка никого не удовлетворяет, но меняет всё.
Когда полупроводниковое подразделение Samsung обнаружило, что инженеры загрузили проприетарные схемы чипов в ChatGPT, реакция была немедленной и абсолютной. Общекорпоративный запрет. Без исключений. Без процедуры апелляции. Инструмент, ставший синонимом продуктивности ИИ, теперь был запрещен во всех корпоративных сетях.
Samsung была не одинока. В течение нескольких месяцев аналогичные объявления появились от JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank и десятков других предприятий. Юридические фирмы, консультирующие компании из Fortune 500, запретили сотрудникам использовать сервис. Системы здравоохранения заблокировали доступ на уровне файрвола. Государственные органы выпустили руководства, которые фактически положили конец любой неоднозначности относительно допустимого использования.
Эта тенденция выявила то, что энтузиасты технологий упустили в своем восторге от возможностей ИИ: корпоративное внедрение работает в условиях ограничений, которых нет у потребительского внедрения.
Эта статья исследует, почему корпоративные политики ИИ ужесточаются, какие конкретные риски движут этими решениями, и как организации могут сохранить возможности ИИ, не принимая неприемлемое раскрытие данных. Путь вперед не требует отказа от ИИ. Он требует понимания того, что инфраструктура важна не меньше, чем интеллект.

Инциденты, которые изменили всё
Корпоративные запреты ИИ возникли не из теоретических оценок рисков. Они последовали за реальными инцидентами, когда конфиденциальная информация вышла из-под организационного контроля.
Утечка полупроводниковых данных Samsung
В начале 2023 года сотрудники Samsung Electronics использовали ChatGPT для отладки исходного кода и оптимизации процессов производства полупроводников. Инженеры вставляли проприетарный код прямо в интерфейс чата. Другие загружали заметки совещаний, содержащие обсуждения стратегического планирования. В течение трех недель после разрешения ChatGPT для внутреннего использования команда информационной безопасности Samsung выявила множественные случаи передачи конфиденциальных данных на серверы OpenAI.
Полупроводниковая отрасль работает с маржой, измеряемой в нанометрах, и конкурентными преимуществами, измеряемыми в месяцах. Возможность того, что производственные процессы Samsung теперь находятся в обучающем корпусе OpenAI — потенциально доступные конкурентам, использующим тот же сервис — была неприемлемой. Samsung ввела полный запрет и начала разрабатывать внутренние инструменты ИИ, которые никогда не будут передавать данные вовне.
Реакция индустрии финансовых услуг
JPMorgan Chase ограничил доступ к ChatGPT еще до каких-либо публичных инцидентов, проактивно осознав регуляторные последствия. Когда банковские сотрудники анализируют клиентские портфели, обсуждают стратегии слияний или оценивают кредитные риски, они работают с информацией, подпадающей под регулирование SEC, законы о банковской тайне и фидуциарные обязанности. Передача такой информации стороннему ИИ-сервису — независимо от заявленных политик конфиденциальности этого сервиса — создает риски соответствия, которые не примет ни один юридический директор.
Goldman Sachs, Citigroup, Bank of America и Deutsche Bank последовали с аналогичными ограничениями. Скоординированный ответ индустрии финансовых услуг отражал не паранойю, а профессиональное понимание регуляторной ответственности. Утечка данных, возникшая из-за использования ChatGPT сотрудниками, потребует раскрытия, вызовет регуляторное расследование и потенциально приведет к принудительным мерам.
Последствия для юридической отрасли
Американская ассоциация юристов не издала общего запрета на инструменты ИИ, но практический эффект требований адвокатской тайны приближается к этому. Когда адвокат обсуждает дела клиентов с ChatGPT, разговор может отменить защиту привилегии. Информация, раскрытая третьим лицам — даже ИИ-системам — может потерять конфиденциальность, которая делает юридические консультации защищенными.
Крупные юридические фирмы, включая Davis Polk, Cravath и Sullivan & Cromwell, ввели ограничения, варьирующиеся от полных запретов до политик только одобренного использования, требующих авторизации партнера. Реакция юридической профессии продемонстрировала, что риски ИИ выходят за рамки безопасности данных к фундаментальным вопросам профессиональной ответственности.
Техническая реальность обработки данных облачного ИИ
Понимание того, почему предприятия запрещают ChatGPT, требует изучения того, что на самом деле происходит, когда вы отправляете сообщение облачному ИИ-сервису.
Путь передачи данных
Когда вы вводите промпт в ChatGPT, ваш текст перемещается с вашего устройства через корпоративную сеть, через публичный интернет, на инфраструктуру OpenAI. OpenAI работает преимущественно на Microsoft Azure, что означает, что ваши данные проходят через сеть Microsoft и находятся на серверах, управляемых Microsoft.
Эта передача происходит независимо от чувствительности контента. Система не может различить запрос на написание стихотворения и запрос на анализ конфиденциальных условий слияния. Каждый символ, который вы вводите, следует по одному и тому же пути к одному и тому же месту назначения.
Политики хранения данных
Политики использования данных OpenAI развивались со временем, но определенные основы остаются неизменными. Пользовательские вводы регистрируются. Разговоры сохраняются. Продолжительность и цель хранения зависят от вашего уровня подписки и конкретных соглашений.
Для подписчиков бесплатного уровня и Plus OpenAI явно оставляет за собой право использовать вводы для улучшения модели. Ваши промпты становятся обучающими данными. Конфиденциальный код, который вы вставили для отладки проблемы, может повлиять на то, как модель отвечает будущим пользователям — потенциально включая ваших конкурентов.
Пользователи API и подписчики Enterprise могут отказаться от вклада в обучающие данные, но их вводы все равно обрабатываются на инфраструктуре OpenAI. Данные все равно существуют на серверах, которые вы не контролируете, управляются сотрудниками, которых вы не проверяли, подчиняются юридическим процессам, на которые вы не можете повлиять.
Проблема третьей стороны
Архитектуры корпоративной безопасности различают системы первой стороны (инфраструктура, которой вы владеете и управляете), системы второй стороны (поставщики с прямыми договорными отношениями и проверенными средствами безопасности) и системы третьей стороны (сервисы, доступ к которым осуществляется без детальной интеграции безопасности).
ChatGPT для большинства пользователей работает как непроверенная третья сторона. Если ваша организация не договорилась о конкретном корпоративном соглашении с приложениями по безопасности, правами на тестирование на проникновение и сертификатами соответствия, соответствующими вашим требованиям, ChatGPT находится за пределами вашего периметра безопасности с доступом к любым данным, которые сотрудники решат поделиться.
Эта архитектурная реальность объясняет, почему команды безопасности относятся к ChatGPT иначе, чем к Microsoft Office или Salesforce. Эти системы, несмотря на то что они облачные, работают в рамках корпоративных соглашений с определенными средствами безопасности, правами аудита и условиями ответственности. ChatGPT для пользователя с подпиской за $20/месяц не предлагает ни одной из этих защит.
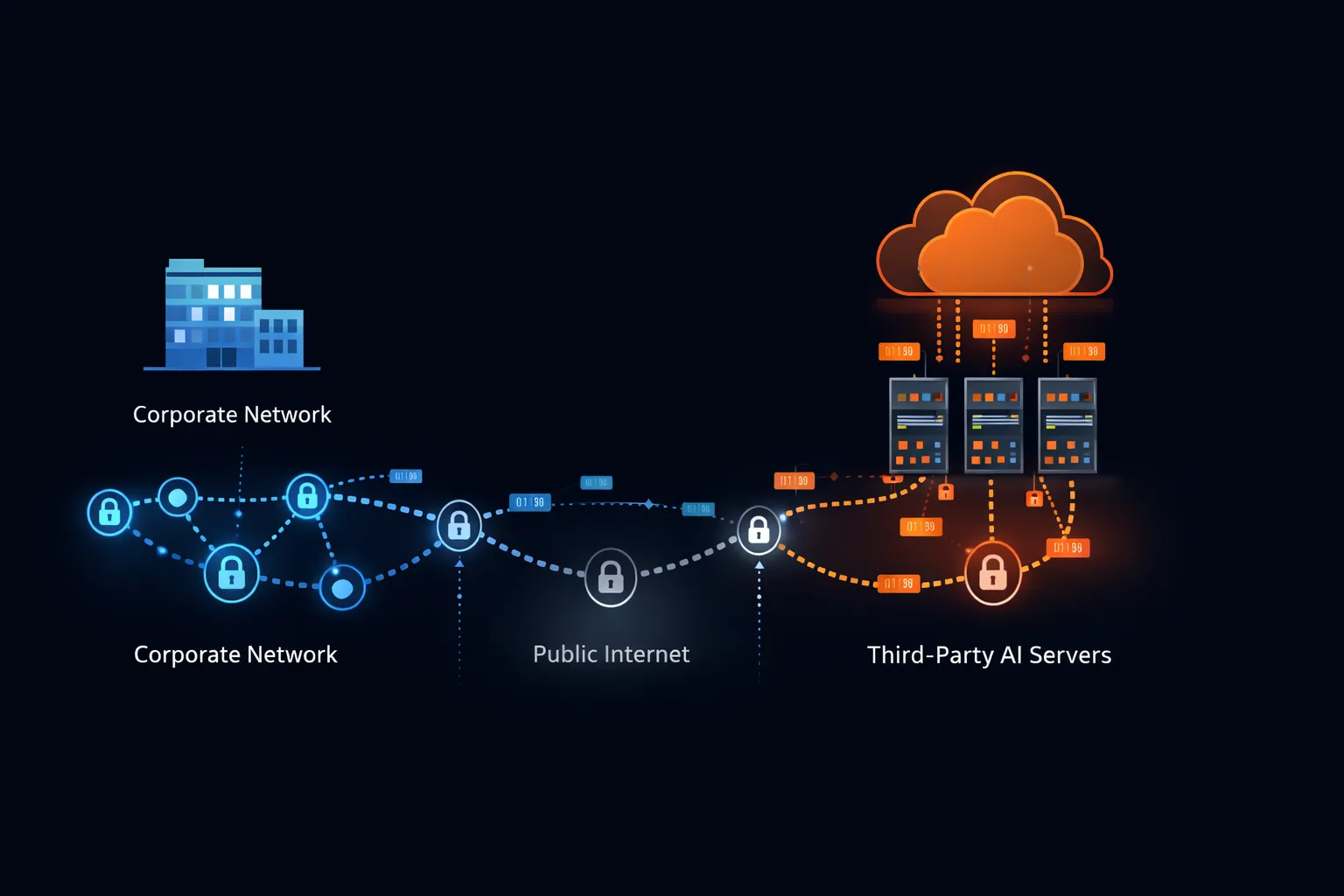
Регуляторные рамки, обуславливающие корпоративную осторожность
Корпоративные политики ИИ не существуют в вакууме. Они отвечают на юридические требования, которые существовали до ChatGPT и переживут его.
GDPR и европейская защита данных
Общий регламент по защите данных накладывает строгие требования на обработку персональных данных резидентов ЕС. Когда сотрудник вставляет информацию о клиентах в ChatGPT, он инициирует передачу данных обработчику, базирующемуся в США. Эта передача требует правового основания — либо решений об адекватности, стандартных договорных условий, либо обязательных корпоративных правил.
Соглашения об обработке данных OpenAI могут удовлетворять требованиям GDPR для некоторых случаев использования, но большинство сотрудников, использующих потребительский продукт, не имеют такого соглашения. Они просто передают персональные данные иностранной корпорации без авторизации.
Итальянские регуляторы временно запретили ChatGPT в 2023 году именно из-за опасений GDPR. Хотя сервис возобновился после того, как OpenAI внесла корректировки соответствия, инцидент продемонстрировал готовность регуляторов действовать. Европейские предприятия несут прямую ответственность за действия сотрудников, нарушающие GDPR, создавая сильные стимулы для ограничительных политик.
HIPAA и данные здравоохранения
Закон о переносимости и подотчетности медицинского страхования запрещает раскрытие защищенной медицинской информации (PHI), за исключением конкретных разрешенных обстоятельств. Работник здравоохранения, обсуждающий случаи пациентов с ChatGPT, раскрывает PHI неуполномоченному получателю.
Между типичными организациями здравоохранения и OpenAI не существует соглашения о деловом партнерстве. Никакой аудит безопасности не проверял соответствие ChatGPT техническим гарантиям HIPAA. Никакая правовая основа не разрешает раскрытие.
Организации здравоохранения, обнаружившие, что сотрудники поделились PHI через ChatGPT, сталкиваются с требованиями уведомления о нарушении, потенциальным расследованием OCR и штрафами, достигающими $1,5 миллиона за категорию нарушения в год. Эти последствия объясняют, почему больничные системы блокируют ChatGPT на сетевом уровне, а не полагаются на соответствие политике.
Финансовые регуляции
Банки, брокеры-дилеры и инвестиционные консультанты работают в рамках регуляций SEC, FINRA, OCC и Федеральной резервной системы, которые предписывают ведение записей и надзор за деловыми коммуникациями. Когда аналитик использует ChatGPT для составления корреспонденции с клиентами, этот разговор должен быть захвачен в архивах соответствия.
ChatGPT не обеспечивает интеграцию с корпоративными архивными системами. Никакие инструменты надзора не отмечают потенциально проблемное использование. Разговор существует только на серверах OpenAI и устройстве сотрудника — ни одно из которых не удовлетворяет регуляторным требованиям к ведению записей.
Помимо ведения записей, финансовые регуляторы выражают озабоченность по поводу инвестиционных советов, генерируемых ИИ, участия ИИ в кредитных решениях и анализа ИИ, который может представлять собой манипулирование рынком. Регуляторный ландшафт остается неопределенным, и сотрудники по соответствию реагируют на неопределенность, ограничивая использование, а не разрешая его в ожидании ясности.
Формирующееся регулирование, специфичное для ИИ
Закон ЕС об ИИ, который, как ожидается, вступит в силу постепенно в 2025 и 2026 годах, введет дополнительные требования к развертыванию систем ИИ. Приложения ИИ высокого риска — включая те, которые влияют на занятость, кредит и образование — требуют оценок соответствия, документации и человеческого надзора.
Организации, использующие ChatGPT в этих контекстах, могут обнаружить, что они эксплуатируют несоответствующие системы ИИ после вступления регуляций в силу. Проактивные предприятия ограничивают использование сейчас, а не сталкиваются с исправлением соответствия позже.
Интеллектуальная собственность: риск, который не решает ни один контракт
Регуляторное соответствие представляет одну категорию опасений. Защита интеллектуальной собственности представляет другую — и для многих предприятий более значимую.
Коммерческие тайны и конфиденциальность
Защита коммерческой тайны в соответствии с Законом о защите коммерческих тайн и государственными эквивалентами требует, чтобы информация оставалась конфиденциальной благодаря разумным защитным мерам. Когда сотрудник вставляет проприетарные алгоритмы, производственные процессы или стратегические планы в ChatGPT, защитные меры организации потерпели неудачу.
Суды, оценивающие претензии на коммерческую тайну, изучают, предприняла ли заявляющая сторона разумные шаги для сохранения секретности. Разрешение сотрудникам делиться конфиденциальной информацией со сторонними ИИ-сервисами подрывает это требование. Даже если информация никогда не утечет из систем OpenAI, сам акт раскрытия может скомпрометировать правовую защиту.
Это опасение выходит за рамки гипотетического судебного разбирательства. Компании регулярно выдвигают претензии на коммерческую тайну против уходящих сотрудников и конкурентов. Если обнаружение выявит, что “секретная” информация ранее была передана ChatGPT — доступная миллионам пользователей через потенциальное обучение модели — претензия существенно ослабевает.
Исходный код и технические активы
Программные компании сталкиваются с особым воздействием. Разработчики естественно хотят использовать инструменты ИИ для отладки кода, генерации шаблонов и ускорения разработки. Но исходный код представляет собой основной актив программного бизнеса. После передачи в ChatGPT этот код существует за пределами организационного контроля.
Опасение по поводу обучающих данных не является теоретическим. Большие языковые модели учатся на своих вводах. Хотя OpenAI заявляет, что клиенты Enterprise и API могут отказаться от вклада в обучение, потребительский продукт не несет такой гарантии. Код, которым поделился один разработчик, может повлиять на автодополнения, показываемые другому — потенциально в конкурирующей компании.
Внутреннее предупреждение Amazon сотрудникам конкретно упоминало риск того, что ответы ChatGPT могут напоминать конфиденциальную информацию Amazon, предполагая, что подобные данные уже были включены в модель. Представляло ли это реальный код Amazon в обучающих данных или просто похожие паттерны, остается неясным. Сама неопределенность подтолкнула к ограничительной политике.
Информация о клиентах и заказчиках
Фирмы профессиональных услуг — консультанты, бухгалтеры, юристы, архитекторы — работают с информацией клиентов, которая принадлежит этим клиентам, а не поставщику услуг. Обмен клиентскими данными с ChatGPT может нарушить письма о помолвке, соглашения о конфиденциальности и правила профессиональной этики.
Консультант, загружающий финансовые прогнозы клиента в ChatGPT для анализа, поделился конфиденциальной информацией этого клиента с третьей стороной. Фирма консультанта может столкнуться с претензиями о нарушении контракта, профессиональной дисциплиной и потерей клиентских отношений в случае обнаружения.
Эти опасения в равной степени применимы к любому бизнесу, работающему с данными клиентов. Торговый представитель, вставляющий клиентскую корреспонденцию в ChatGPT для составления ответа, передал клиентские коммуникации в OpenAI. В зависимости от отрасли и применимых соглашений это может нарушить обязательства по обработке клиентских данных.

Недостаточность корпоративных соглашений об ИИ
OpenAI предлагает ChatGPT Enterprise специально для решения корпоративных проблем. Microsoft предоставляет Azure OpenAI Service с корпоративными функциями безопасности. Эти продукты улучшают потребительские предложения, но не устраняют фундаментальные опасения для случаев использования высокой чувствительности.
Что обеспечивают корпоративные соглашения
ChatGPT Enterprise включает несколько значимых улучшений:
- Данные не используются для обучения модели
- Сертификация соответствия SOC 2 Type 2
- Шифрование данных в состоянии покоя и при передаче
- Интеграция SSO и административные средства управления
- Средства управления хранением данных
Эти функции удовлетворяют требованиям для многих корпоративных случаев использования. Маркетинговая команда, составляющая тексты кампаний, сталкивается с минимальным риском. Отдел обслуживания клиентов, генерирующий шаблоны ответов, работает в пределах допустимых параметров.
Что корпоративные соглашения не могут обеспечить
Для регулируемых отраслей и конфиденциальной интеллектуальной собственности корпоративные соглашения недостаточны по фундаментальным причинам.
Во-первых, данные все равно обрабатываются на инфраструктуре, которую вы не контролируете. Ваша информация находится на серверах OpenAI, управляется сотрудниками OpenAI, подчиняется практикам безопасности OpenAI. Вы доверяете их реализации. Доверяете их проверке персонала. Доверяете их реагированию на инциденты. Это доверие может быть оправданным, но это все равно доверие — не верификация.
Во-вторых, данные остаются подчиненными юридическому процессу. Повестка, врученная OpenAI, может принудить к раскрытию ваших разговоров. Правительственное расследование в отношении другого клиента потенциально может раскрыть общую инфраструктуру. Письма о национальной безопасности и ордера суда FISA действуют в условиях требований секретности, которые помешают OpenAI уведомить вас о доступе.
В-третьих, поверхность атаки включает всю организацию OpenAI. Ваш периметр безопасности больше не заканчивается на границе вашей сети. Каждый сотрудник OpenAI с системным доступом, каждый поставщик с инфраструктурным доступом, каждая уязвимость безопасности в системах OpenAI становится частью вашего профиля рисков.
В-четвертых, выход и переносимость остаются ограниченными. Ваша история разговоров, дообученное поведение и организационные знания, накопленные в ChatGPT, принадлежат взаимодействиям с системой OpenAI. Миграция на альтернативу требует перестройки с нуля.
Для фармацевтической компании, разрабатывающей новые соединения, оборонного подрядчика, работающего с почти засекреченными исследованиями, или финансового учреждения с торговыми алгоритмами, представляющими миллиарды потенциальной стоимости, эти ограничения имеют значение. Корпоративные соглашения снижают риск. Они его не устраняют.
Альтернатива с открытыми весами
Ограничения, движущие корпоративными запретами ChatGPT, не применяются к ИИ в целом. Они применяются конкретно к облачным ИИ-сервисам, где данные покидают организационный контроль. Другая архитектура полностью устраняет эти опасения.
Что обеспечивают модели с открытыми весами
Модели с открытыми весами — Llama от Meta, Mistral от Mistral AI, Qwen от Alibaba и десятки других — предоставляют загружаемые файлы моделей, которые работают на любом совместимом оборудовании. Веса модели публичны. Код инференса с открытым исходным кодом. Вы можете выполнять всю систему на инфраструктуре, которой владеете и управляете.
Когда вы запускаете Llama на собственном сервере, ваши промпты никогда не покидают вашу сеть. Никакая третья сторона не получает ваши данные. Никакой облачный сервис не регистрирует ваши запросы. Никакой обучающий конвейер не включает ваши вводы. Модель работает локально, обрабатывает локально и не хранит ничего, кроме того, что вы явно настраиваете.
Эта архитектура удовлетворяет каждому опасению, которое движет запретами ChatGPT:
-
Регуляторное соответствие: Данные остаются в пределах вашего периметра безопасности, подчиняются вашим средствам управления, регулируются вашими политиками. Передачи данных GDPR не происходят, потому что данные не передаются. Опасения HIPAA растворяются, потому что нет раскрытия неуполномоченным сторонам.
-
Защита интеллектуальной собственности: Коммерческие тайны остаются секретными. Исходный код никогда не покидает ваши системы. Клиентская конфиденциальность сохраняется, потому что никакая третья сторона не получает клиентскую информацию.
-
Контроль безопасности: Ваша поверхность атаки остается вашей. Вы верифицируете свои практики безопасности. Проверяете свой персонал. Контролируете свое реагирование на инциденты. Уязвимости никакой внешней организации не влияют на ваши данные.
-
Аудит и соответствие: Каждый запрос, каждый ответ, каждое взаимодействие с моделью может быть зарегистрировано в соответствии с вашими требованиями. Регуляторное ведение записей интегрируется с вашими существующими архивными системами.
Сравнение возможностей
Естественный вопрос — соответствуют ли модели с открытыми весами возможностям ChatGPT. Честный ответ: зависит от случая использования.
Для общих запросов знаний обучение ChatGPT на данных интернет-масштаба обеспечивает широту, которой меньшие открытые модели не могут соответствовать. Способности рассуждения GPT-4 в сложных проблемах превосходят достижения Llama-3-8B.
Но корпоративные случаи использования редко требуют знаний интернет-масштаба. Юридическая команда, анализирующая контракты, нуждается в понимании документов и точной генерации языка — возможностях, в которых дообученные открытые модели преуспевают. Команда разработчиков, отлаживающая код, нуждается в распознавании паттернов в конкретных кодовых базах — задаче, в которой пользовательское обучение драматически превосходит общие модели.
Критическое понимание состоит в том, что дообучение трансформирует общие модели в специалистов домена. Модель Llama-3-8B, дообученная на документах вашей организации, стандартах кодирования и паттернах коммуникации, превзойдет GPT-4 для ваших конкретных задач, сохраняя полную изоляцию данных.
Наше основное руководство по частному дообучению LLM на децентрализованных GPU предоставляет полный технический рабочий процесс для этого процесса.
Варианты инфраструктуры для частного развертывания ИИ
Запуск моделей с открытыми весами требует GPU-вычислений. У организаций есть несколько вариантов приобретения этой возможности.
Локальное оборудование
Покупка GPU NVIDIA для внутренних дата-центров обеспечивает максимальный контроль. Оборудование находится в вашем помещении, управляется вашим персоналом, подключено к вашей сети. Никакая внешняя сторона не имеет никакого доступа.
Проблема — капитальные затраты и время выполнения заказа. GPU NVIDIA H100 стоит приблизительно $30 000. Значимый кластер для обучения требует нескольких единиц. Сроки закупки растягиваются на месяцы. Текущее обслуживание требует специализированной экспертизы.
Для крупных предприятий с существующими операциями дата-центров локальная ИИ-инфраструктура представляет собой естественное расширение. Для меньших организаций или тех, кто не имеет экспертизы в GPU, барьеры существенны.
Частные облачные инстансы
AWS, GCP и Azure предлагают GPU-инстансы, которые обеспечивают больший контроль, чем SaaS-продукты ИИ. Вы настраиваете среду. Контролируете доступ. Ваши данные обрабатываются на выделенных инстансах, а не на общих сервисах.
Этот подход улучшает архитектуру ChatGPT, но сохраняет участие облачного провайдера. Ваши данные все равно находятся на инфраструктуре, которую вы не контролируете физически. Сотрудники облачного провайдера с достаточным доступом теоретически могут получить доступ к вашим системам. Юридический процесс, врученный облачному провайдеру, может достичь ваших данных.
Кроме того, частные облачные GPU-инстансы несут значительные затраты. Инстансы AWS p4d.24xlarge (8x A100 GPU) стоят примерно $32 в час. Длительные запуски обучения или непрерывные сервисы инференса генерируют существенные ежемесячные расходы. Доступность ограничена — GPU-инстансы часто показывают списки ожидания или ограниченную региональную доступность.
Децентрализованная аренда GPU
Третий вариант обходит как капитальные затраты, так и участие облачного провайдера. Децентрализованные GPU-маркетплейсы напрямую соединяют пользователей с владельцами оборудования. Вы арендуете вычислительную мощность пиринговым способом, платя криптовалютой, без верификации личности или посредничества облачного провайдера.
Эта модель предоставляет несколько преимуществ для организаций, заботящихся о конфиденциальности:
-
Отсутствие требований KYC: Вы подключаете кошелек и арендуете оборудование. Без корпоративных аккаунтов. Без корпоративного процесса продаж. Без документации личности, связывающей вашу организацию с конкретными действиями ИИ.
-
Отсутствие участия облачного провайдера: Ваши данные обрабатываются на оборудовании, принадлежащем физическим лицам, а не корпорациям с юридическими отделами, государственными контрактами и отношениями с правоохранительными органами.
-
Эффективность затрат: Аренда RTX 4090 стоит от $0,40 до $0,60 в час, примерно десятая часть стоимости сопоставимых облачных инстансов. Наше сравнение цен на аренду GPU подробно описывает экономику.
-
Глобальная доступность: Децентрализованное предложение означает отсутствие региональных ограничений. Оборудование доступно, когда вам нужно, распределенное по юрисдикциям по всему миру.
Для организаций, которые не могут оправдать капитальные затраты на GPU-оборудование, но требуют более сильных гарантий конфиденциальности, чем предлагают облачные провайдеры, децентрализованная аренда предоставляет практичный средний путь.
Рабочий процесс включает передачу ваших данных напрямую на арендованный узел через зашифрованное SSH-соединение, выполнение вашей задачи обучения или инференса, загрузку результатов и очистку удаленной среды перед отключением. Наше руководство по защите вашего датасета на публичном GPU-узле подробно описывает практики операционной безопасности.
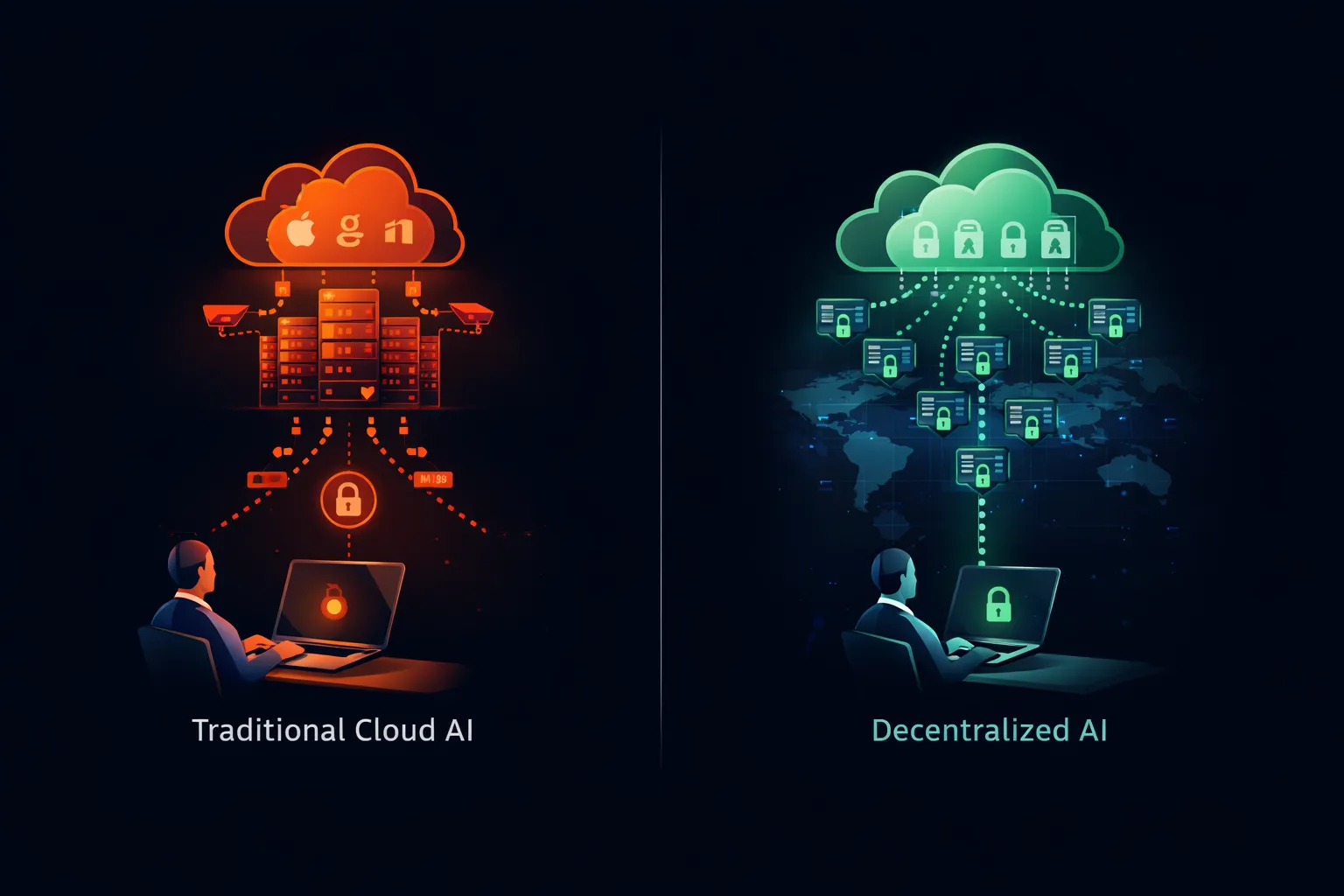
Реализация соответствующей ИИ-стратегии
Организации, переходящие от запретов ChatGPT к частному развертыванию ИИ, должны подходить к переходу системно.
Фаза 1: Разработка политики
Начните с формулирования того, что ваша ИИ-политика на самом деле запрещает и разрешает. Многие первоначальные запреты ChatGPT были реактивными — всеобъемлющие запреты, быстро реализованные для остановки немедленного риска. Зрелая политика различает:
- Категории данных, которые никогда не могут обрабатываться внешними ИИ-системами
- Случаи использования, где облачные ИИ-сервисы приемлемы с соответствующими средствами контроля
- Утвержденные инструменты и платформы для разных уровней чувствительности
- Процессы утверждения для внедрения новых ИИ-инструментов
- Требования к отчетности об инцидентах при нарушениях политики
Эта структура позволяет продолжать использование ИИ там, где это уместно, защищая чувствительные операции.
Фаза 2: Оценка инфраструктуры
Оцените ваши варианты для частного развертывания ИИ на основе организационных ресурсов и требований:
-
Существующие GPU-ресурсы: Многие организации имеют рабочие станции или серверы с GPU NVIDIA, используемые для других целей (визуализация, рендеринг, научные вычисления), которые могут поддерживать ИИ-рабочие нагрузки.
-
Облачный бюджет и толерантность к риску: Если ваша команда безопасности принимает участие облачного провайдера с соответствующими средствами контроля, частные облачные GPU-инстансы предлагают более простые операции, чем локальные или децентрализованные варианты.
-
Требования конфиденциальности: Если ваш случай использования включает данные, которые не могут касаться инфраструктуры облачного провайдера ни при каких обстоятельствах, локальное оборудование или децентрализованная аренда становятся необходимыми.
-
Масштаб и частота: Периодические задачи дообучения подходят для моделей аренды. Непрерывный сервис инференса может оправдать капитальные инвестиции.
Фаза 3: Выбор и настройка модели
Общие модели с открытыми весами предоставляют отправную точку, но организационная ценность приходит от настройки. Дообучение на ваших данных создает модели, которые понимают ваш домен, вашу терминологию и ваши требования.
Рассмотрите, какие случаи использования предлагают наибольшую ценность:
- Анализ документов: Юридические контракты, регуляторные заявки, внутренние политики
- Помощь с кодом: Разработка в рамках ваших конкретных фреймворков и стандартов
- Коммуникация с клиентами: Ответы, отражающие голос вашего бренда и знание продукта
- Внутренние знания: Запросы к организационной документации и институциональным знаниям
Каждый случай использования может оправдать отдельную дообученную модель, или одна модель, обученная на разнообразных организационных данных, может служить нескольким целям.
Фаза 4: Операционная интеграция
Частное развертывание ИИ требует операционных возможностей, которые SaaS-продукты абстрагируют:
-
Инфраструктура обслуживания модели: Запуск инференса в масштабе требует GPU-ресурсов, балансировки нагрузки и API-интерфейсов. Такие инструменты, как vLLM, Text Generation Inference и Ollama, упрощают развертывание.
-
Контроль доступа: Кто может запрашивать модель? Какое логирование происходит? Как вы проводите аудит использования?
-
Процедуры обновления: Как вы включаете новые обучающие данные? Как вы развертываете улучшенные версии модели?
-
Реагирование на инциденты: Что происходит, если модель генерирует проблемный вывод? Кто проверяет пограничные случаи?
Организации, привыкшие к простоте SaaS, могут недооценить эту операционную нагрузку. Планируйте бюджет соответствующим образом для текущего обслуживания, а не только для первоначального развертывания.
Кейс-стади: Архитектура соответствия финансовых услуг
Региональный банк с активами $50 миллиардов столкнулся с знакомой дилеммой. Менеджеры по работе с клиентами хотели ИИ-помощь для составления клиентских коммуникаций и анализа портфельных позиций. Специалисты по соответствию признали, что передача финансовых данных клиентов в ChatGPT нарушает как регуляторные требования, так и фидуциарные обязанности.
Архитектура решения иллюстрирует, как организации могут удовлетворить обе стороны.
Классификация данных
Банк установил три уровня данных, допустимых для ИИ:
-
Уровень 1 (Публичный): Маркетинговые материалы, публичный финансово-образовательный контент, общие описания продуктов. Облачные ИИ-сервисы разрешены со стандартными руководствами по допустимому использованию.
-
Уровень 2 (Внутренний): Внутренние политики, обучающие материалы, операционные процедуры. Облачные ИИ-сервисы разрешены с корпоративными соглашениями и приложениями по обработке данных.
-
Уровень 3 (Ограниченный): Данные клиентов, портфельная информация, детали транзакций, стратегическое планирование. Никакая внешняя ИИ-обработка ни при каких обстоятельствах.
Эта классификация позволила внедрение ИИ там, где риск был приемлем, сохраняя абсолютную защиту для чувствительных категорий.
Развертывание частной инфраструктуры
Для случаев использования Уровня 3 банк развернул дообученную модель Llama на локальных GPU-серверах в своем существующем дата-центре. Модель была обучена на:
- Анонимизированных исторических клиентских коммуникациях (с согласия клиента)
- Внутренних руководствах по соответствию и регуляторных интерпретациях
- Продуктовой документации и инвестиционных исследованиях
- Шаблонах коммуникации, утвержденных отделом соответствия
Полученная модель понимала банковскую терминологию, регуляторные ограничения и организационные стандарты коммуникации. Менеджеры по работе с клиентами могли составлять клиентские письма с ИИ-помощью, зная, что никакие клиентские данные не покидают периметр безопасности банка.
Операционный контроль
Каждое взаимодействие с моделью регистрировалось в существующей архивной системе соответствия банка. Супервайзеры могли просматривать коммуникации с ИИ-помощью наряду с традиционной корреспонденцией. Аудиторские следы удовлетворяли регуляторным требованиям к ведению записей.
Сама модель работала в рамках ограждений, предотвращающих определенные выводы — инвестиционные рекомендации, гарантийный язык или заявления, которые могут составлять консультации, требующие специфического лицензирования. Эти ограничения были реализованы на уровне приложения, а не полагаясь только на поведение модели.
Измеренные результаты
Через шесть месяцев после развертывания банк сообщил:
- 40% сокращение времени, затрачиваемого на составление рутинных клиентских коммуникаций
- Ноль инцидентов соответствия, связанных с использованием ИИ
- Успешная регуляторная проверка без замечаний, связанных с развертыванием ИИ
- Повышение показателей удовлетворенности менеджеров по работе с клиентами
Инвестиции в частную инфраструктуру — примерно $200 000, включая оборудование, разработку и интеграцию — сгенерировали возврат в течение первого года только за счет прироста производительности.
Кейс-стади: Медицинское исследовательское учреждение
Крупный академический медицинский центр, проводящий клинические исследования, столкнулся с ограничениями HIPAA, которые делали любое использование облачного ИИ с данными пациентов юридически проблематичным. Исследователи хотели использовать ИИ для обзора литературы, разработки протоколов и анализа данных.
Гибридный подход
Вместо выбора между полным запретом и неприемлемым риском учреждение реализовало гибридную архитектуру:
-
Публичные исследовательские задачи (обзор литературы, методологические вопросы, статистические подходы) использовали облачные ИИ-сервисы с четкими политиками, запрещающими любой ввод данных пациентов.
-
Анализ данных пациентов использовал локально развернутые модели на изолированных рабочих станциях в безопасной исследовательской среде. Эти машины не имели интернет-подключения. Данные не могли покинуть их независимо от поведения пользователя.
Децентрализованное обучение
Учреждение не имело капитального бюджета на GPU-оборудование для обучения, но нуждалось в моделях, дообученных на медицинской литературе и исследовательских протоколах. Они использовали децентрализованную аренду GPU для запусков обучения, используя только публичную медицинскую литературу и обезличенные наборы данных без последствий HIPAA.
Рабочий процесс обучения следовал практикам безопасности, описанным в нашем руководстве по безопасности набора данных:
- Передача только нечувствительных обучающих данных на арендованные узлы
- Выполнение задач дообучения
- Загрузка полученных весов модели
- Полная очистка удаленных сред
- Развертывание обученных моделей на изолированной внутренней инфраструктуре
Этот подход предоставил настроенные медицинские ИИ-возможности без раскрытия какой-либо защищенной медицинской информации внешним системам.
Регуляторная валидация
IRB учреждения проверил развертывание ИИ как часть поправок к исследовательскому протоколу. Четкое разделение между обучением на публичных данных (внешнее) и инференсом на данных пациентов (внутреннее, изолированное) удовлетворило требованиям конфиденциальности. Специалисты по соответствию HIPAA утвердили архитектуру после оценки безопасности.

Стратегический императив
Организации, которые рассматривают ИИ-политику только через призму снижения рисков, упускают общую картину. Предприятия, запрещающие ChatGPT сегодня, не отказываются от ИИ. Они перепозиционируются для устойчивого преимущества.
Конкурентная дифференциация через данные
Наиболее ценные ИИ-возможности возникают из проприетарных данных. Общая языковая модель, обученная на интернет-тексте, предоставляет общие возможности, доступные всем. Модель, дообученная на ваших взаимодействиях с клиентами, ваших операционных данных и ваших институциональных знаниях, предоставляет уникальные возможности для вашей организации.
Эта дифференциация требует сохранения проприетарных данных проприетарными. Организации, которые подают свои конкурентные преимущества в облачные ИИ-сервисы, вносят вклад в модели, которые приносят пользу всем пользователям — включая конкурентов. Организации, которые сохраняют контроль над данными, развертывая частный ИИ, накапливают преимущества, которые со временем умножаются.
Регуляторная траектория
Регулирование ИИ ужесточается, а не ослабляется. Закон ЕС об ИИ устанавливает прецедент, которому последуют другие юрисдикции. Американские агентства, включая FTC, SEC и банковских регуляторов, разрабатывают специфичные для ИИ руководства. Китай ввел регуляции ИИ, влияющие на обучение и развертывание моделей.
Организации, строящие частную ИИ-инфраструктуру сейчас, готовятся к регуляторным средам, которые будут все больше ограничивать использование облачного ИИ. Инвестиции в соответствующую архитектуру становятся более ценными по мере усиления требований соответствия.
Соображения цепочки поставок
Зависимость от одного провайдера ИИ создает стратегическую уязвимость. Ценообразование, политики и возможности OpenAI меняются по их усмотрению. Перебои в обслуживании одновременно затрагивают всех клиентов. Изменения политики могут запретить ранее допустимые случаи использования в одночасье.
Частное развертывание ИИ устраняет зависимость от одного поставщика. Модели с открытыми весами загружаемы и постоянно доступны. Для развертывания существуют множественные варианты оборудования. Организация контролирует свою цепочку поставок ИИ, а не зависит от внешних решений.
Дорожная карта реализации
Для организаций, готовых перейти от запретов ChatGPT к частным ИИ-возможностям, мы рекомендуем поэтапный подход.
Немедленные действия (Неделя 1-2)
- Аудит текущего использования ИИ в организации
- Классификация типов данных по чувствительности и регуляторным требованиям
- Документирование того, какие случаи использования требуют частной инфраструктуры по сравнению с допустимым облачным использованием
- Установление промежуточной политики, разъясняющей запрещенные и разрешенные действия
Краткосрочная разработка (Месяц 1-3)
- Оценка вариантов инфраструктуры на основе требований чувствительности и бюджета
- Выбор начальных случаев использования для частного развертывания ИИ
- Идентификация источников обучающих данных для настройки модели
- Установление протоколов безопасности для внешнего использования GPU, если применимо
Среднесрочное развертывание (Месяц 3-6)
- Дообучение моделей на организационных данных в соответствии с нашим техническим руководством
- Развертывание инфраструктуры инференса с соответствующими средствами контроля доступа
- Интеграция с существующими системами соответствия и аудита
- Обучение пользователей утвержденным рабочим процессам и инструментам
Текущие операции
- Регулярные обновления модели с включением новых обучающих данных
- Оценки безопасности ИИ-инфраструктуры
- Обновления политики, отражающие регуляторные изменения
- Расширение возможностей на дополнительные случаи использования
Заключение
Корпоративные запреты ChatGPT отражают рациональное управление рисками, а не технофобию. Когда Samsung запретила инструмент после обнаружения того, что были загружены проприетарные полупроводниковые схемы, они приняли правильное решение. Когда JPMorgan проактивно ограничил доступ, они продемонстрировали надлежащее регуляторное осознание. Когда системы здравоохранения блокируют доступ на уровне файрвола, они защищают конфиденциальность пациентов, как того требует закон.
Но запрет — это не стратегия. Организации, которые останавливаются на “нет”, отказываются от преимуществ производительности, которые захватят их конкуренты. Предприятия, которые будут процветать — это те, которые признают, что существует третий путь.
Модели с открытыми весами, работающие на частной инфраструктуре, обеспечивают ИИ-возможности без раскрытия данных. Модели доступны сейчас. Инфраструктура доступна. Технические рабочие процессы задокументированы. Единственный барьер — это организационная воля к реализации.
Ваши конкуренты, которые дообучают модели на своих проприетарных данных — обучая системы, которые понимают их клиентов, их продукты и их операции — строят преимущества, которые вы не можете воспроизвести, подписавшись на общий сервис. Пока вы обсуждаете политику, они развертывают возможности.
Решения об инфраструктуре, которые вы принимаете сегодня, определяют, станет ли ИИ вашим конкурентным преимуществом или преимуществом ваших конкурентов над вами. Облачные ИИ-сервисы превращают ваши данные в общие ресурсы. Частное развертывание ИИ превращает ваши данные в уникальную возможность.
Выбор не в том, использовать ли ИИ. Выбор в том, контролировать ли его.
Связанные ресурсы
Эта статья рассматривает стратегический и регуляторный контекст для корпоративных решений об ИИ. Следующие ресурсы предоставляют руководство по технической реализации:
Основное руководство по реализации
- Полное руководство по частному дообучению LLM на децентрализованных GPU — Полный технический рабочий процесс для обучения пользовательских моделей
Безопасность и операции
- Как защитить ваш набор данных на публичном GPU-узле — Практики операционной безопасности для децентрализованных вычислений
- Как арендовать GPU без KYC — Анонимные рабочие процессы аренды для развертываний, чувствительных к конфиденциальности
Платформа и экономика
- Сравнение цен на аренду GPU 2026 — Анализ затрат по вариантам развертывания
- Объяснение эскроу смарт-контракта — Как децентрализованные платежи защищают обе стороны
- Стейблкоины — самый умный способ платить за аренду GPU — Механика платежей для децентрализованной инфраструктуры
Технические сравнения
- Ollama vs vLLM vs TGI: Бенчмаркинг скоростей инференса на потребительских GPU — Выбор сервера инференса для развертывания
- Сравнение RunPod vs Vast.ai — Оценка маркетплейса для аренды GPU