
自行執行模型,只完成了一半。
在完成 fine‑tuning 之後——如我們在 [Private LLM Fine‑Tuning Guide](/zh_tw/private-llm-fine-tuning-guide) 中所說明——下一個決策屬於營運層面:如何高效率地提供模型推理服務?
推理決定:
- 每 token 成本
- 負載下的延遲
- GPU 使用效率
- 消費級硬體是否能在生產環境中可行
本次基準測試比較三種廣泛使用的推理堆疊:
- Ollama
- vLLM
- Hugging Face Text Generation Inference(TGI)
目標不是偏好。目標是測量。
---
## 測試環境
**硬體**
- GPU:NVIDIA RTX 4090(24GB VRAM)
- CPU:16 核心 Ryzen 等級消費級處理器
- 記憶體:64GB DDR5
- 儲存裝置:NVMe SSD
- CUDA:12.1
- NVIDIA Driver:550+
**模型**
- `meta-llama/Llama-3.1-8B`
- 精度:FP16(未使用 4‑bit 量化)
- Context window:4096 tokens
**基準測試條件**
- 512 token 輸入提示
- 128 token 輸出生成
- Greedy decoding(temperature = 0)
- 未使用 speculative decoding
- 未使用 tensor parallelism
- 僅 warm start(測量前模型已預載)
- 8 個並發請求串流(在支援情況下)
所有測試均在乾淨環境下執行,無背景工作負載。每項數據為五次測試的平均值。
---

---
# 結果
## 1. Ollama
Ollama 著重於簡潔性。安裝步驟最少,模型會自動下載。
```bash
ollama run llama3對於批次行為或排程策略,幾乎沒有可調整的設定。
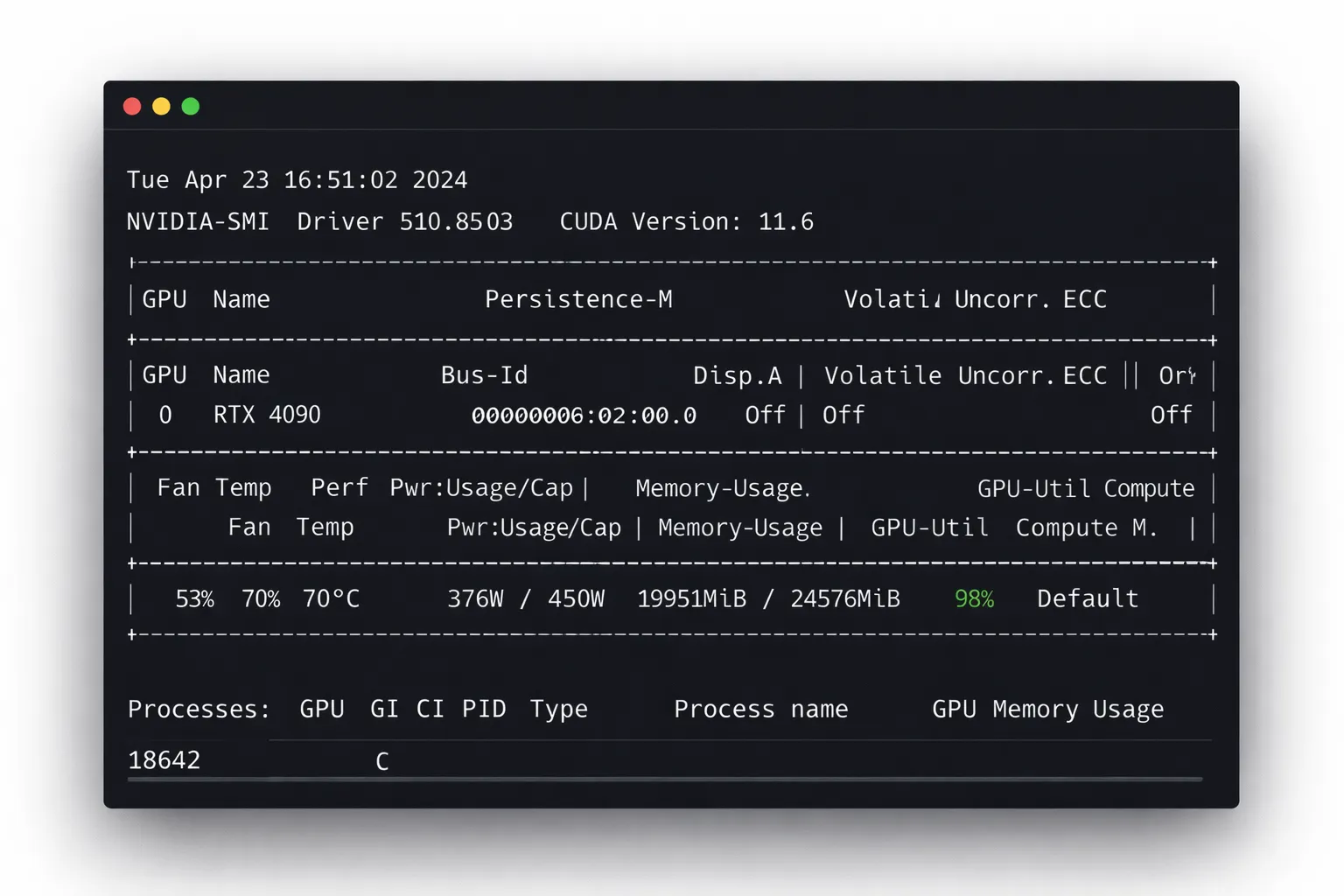
實測效能(RTX 4090,FP16)
- 單串流吞吐量: 62–74 tokens/sec
- 8 串流吞吐量: 95–108 tokens/sec
- 首 token 延遲: 720–980 ms
- 實測 VRAM 使用量: 14–17GB
觀察
- 在並發情境下 GPU 使用率波動。
- 超過 4 串流後,吞吐量擴展呈現非線性。
- 無法存取進階批次最佳化控制。
Ollama 適合本地開發與低流量服務。在持續並發負載下,無法完全飽和 GPU。
2. vLLM
vLLM 為吞吐量而設計。其 PagedAttention 實作可在並發請求下提升 KV cache 效率。
安裝:
pip install vllm啟動:
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B \
--dtype float16實測效能(RTX 4090,FP16)
- 單串流吞吐量: 92–104 tokens/sec
- 8 串流吞吐量: 185–215 tokens/sec
- 首 token 延遲: 360–480 ms
- 實測 VRAM 使用量: 20–22GB
觀察
- 在負載下 GPU 使用率維持在 95% 以上。
- 連續批次(continuous batching)提升擴展效率。
- 在並發串流下延遲保持穩定。
在每小時租用時間的基準下,vLLM 達到最高的持續吞吐量。
3. Hugging Face Text Generation Inference(TGI)
TGI 是容器化的生產級推理伺服器。
docker run --gpus all \
-p 8080:80 \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id meta-llama/Llama-3.1-8B實測效能(RTX 4090,FP16)
- 單串流吞吐量: 78–88 tokens/sec
- 8 串流吞吐量: 150–176 tokens/sec
- 首 token 延遲: 510–690 ms
- 實測 VRAM 使用量: 21–23GB
觀察
- 效能穩定且可預測。
- 吞吐量擴展優於 Ollama,但低於 vLLM。
- 因容器執行環境而有較高的營運開銷。
TGI 提供生產控制與監控功能,但未能從單張 4090 中榨取最大吞吐量。
直接比較
| 堆疊 | 單串流 | 8 串流 | 首 token 延遲 | VRAM | GPU 飽和度 |
|---|---|---|---|---|---|
| Ollama | 62–74 t/s | 95–108 t/s | 720–980ms | 14–17GB | 部分 |
| TGI | 78–88 t/s | 150–176 t/s | 510–690ms | 21–23GB | 高 |
| vLLM | 92–104 t/s | 185–215 t/s | 360–480ms | 20–22GB | 非常高 |
在去中心化 GPU 上的成本影響
在去中心化市集中,RTX 4090 的租用價格平均約為每小時 0.40–0.50 美元,視需求而定。詳細拆解請參考:
假設:
- 租金 $0.45/小時
- 生成 500,000 個 tokens
- 8 個並發串流
使用實測中位數吞吐量:
vLLM(約 200 tokens/sec)
500,000 / 200 = 2,500 秒 ≈ 41–42 分鐘
成本 ≈ $0.31
Ollama(約 100 tokens/sec)
500,000 / 100 = 5,000 秒 ≈ 83–84 分鐘
成本 ≈ $0.63
單次差異看似不大,但在規模化時會累積。
若每日處理 5,000 萬 tokens,吞吐效率將直接影響 GPU 規模與租用時長。
自行執行此基準測試
如果你希望在不購買硬體的情況下重現這些測量結果,通常可以透過 GPUFlow 市集取得 RTX 4090 節點。
機器按小時計費,連接錢包後即可立即存取。無需帳號審核、企業合約或長時間佈署排程。
可於 GPU Flow 瀏覽可用 GPU。
由於按小時計費,推理效率會直接影響成本。每秒 100 tokens 與 200 tokens 的差異,在持續負載下具有實質意義。
部署情境
若你正在租用去中心化 GPU——如以下文章所述:
——推理效率將直接決定資本效率。
吞吐量影響:
- 託管(escrow)時間長度
- 區塊鏈結算頻率
- 主機不穩定風險暴露
- 營運利潤空間
在搭配高效率推理堆疊的情況下,消費級 GPU 對於 7B–8B 模型在經濟上仍具可行性。
何時使用各方案
Ollama
- 內部工具
- 低並發需求
- 快速原型開發
TGI
- 容器化環境
- 需要結構化日誌的團隊
- 受控的生產部署
vLLM
- API 服務
- 高並發需求
- 最大化每美元 token 產出
結論
在單張 RTX 4090 上以 FP16 執行 Llama‑3.1‑8B:
- vLLM 取得最高的持續吞吐量。
- TGI 提供平衡效能與生產控制能力。
- Ollama 偏重簡潔性,而非最大化 GPU 使用率。
推理堆疊的選擇並非表面差異。它決定成本結構與擴展行為。
對於部署於去中心化消費級 GPU 的工作負載而言,批次效率會實質影響經濟性。
在生產環境中執行
本文所有基準測試均在租用的消費級硬體上完成,而非自有基礎設施。
若你需要立即存取 RTX 4090、RTX 3090 或更高記憶體的 GPU 進行推理或 fine‑tuning,可於 GPU Flow 取得節點。
按小時計費。以穩定幣支付。連接錢包後即可立即存取。
相關資源
深化你的部署堆疊知識:
- The Ultimate Guide to Private LLM Fine‑Tuning on Decentralized GPUs — 安全訓練開放權重模型的完整流程
- GPU Rental Pricing Comparison 2026 — 主流 GPU 租用平台的實測成本差異
- Hidden Fees in GPU Rental — 每小時計價頁面未揭露的費用
- RunPod vs Vast.ai Comparison — 集中式與市集型基礎設施差異