RunPod vs Vast.ai:AI 開發者完整對比指南
對於需要 GPU 算力但又不想支付企業級雲服務高昂費用的 AI 開發者來說,在 RunPod 和 Vast.ai 之間做出選擇是一個非常普遍的決策。這兩個平台都填補了昂貴的巨頭服務商與自行購置硬體之間的空白,但它們解決問題的方法迥異,正確的选择很大程度上取決於您的具體需求。
本文將從實際 GPU 租賃中真正重要的維度對這兩個平台進行考察:定價結構、可靠性特徵、功能集以及每個平台最擅長處理的工作流。我曾在訓練和推理負載中大量使用過這兩個平台,本次分析結合了這些實操經驗與當前的市場數據。
簡而言之:Vast.ai 贏在價格,RunPod 贏在便利性和可靠性。而長篇分析則需要理解每個平台架構決策背後的權衡。
本指南涵蓋內容:
- 包含真實成本計算的詳細價格對比
- 基於平台架構和用戶反饋指標的可靠性分析
- 兩大平台各項功能的逐一拆解
- 針對不同工作負載類型的具體建議
- 快速上手每個平台的實操指導
目錄
- 平台概覽
- 定價對比
- 可靠性與在線率
- 可用硬體
- 使用者體驗與介面
- 模板與預配置環境
- 存儲與數據傳輸
- 付款方式
- 支持與文檔
- 安全考量
- 真實性能實測對比
- 各平台的最佳應用場景
- 遷移注意事項
- 其他備選方案
- 常見問題解答
- 最終總結建議
平台概覽
RunPod:託管式算力市場
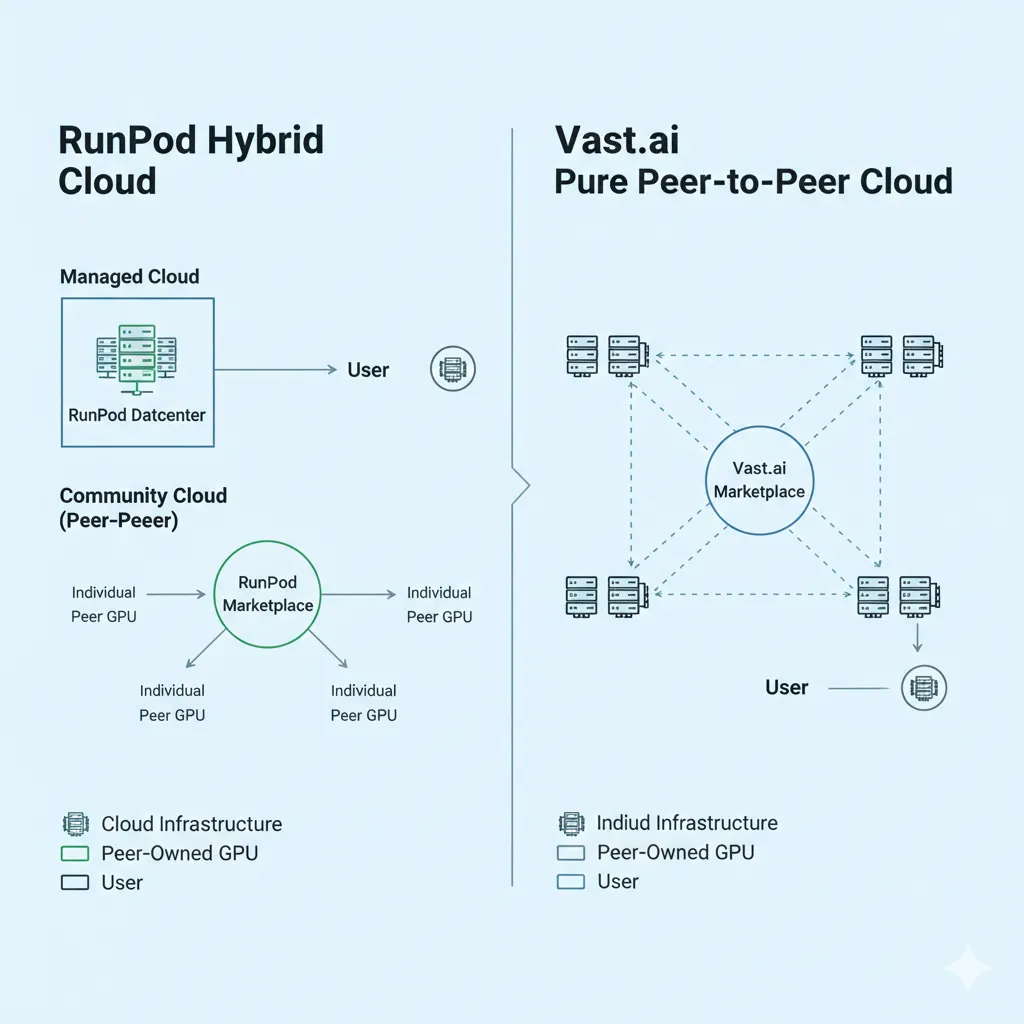
RunPod 於 2022 年推出,致力於讓個人開發者和小型團隊能夠輕鬆租用 GPU。該平台採用混合模式:由管理的数据中心硬體組成的「Secure Cloud(安全雲)」層級,以及類似於 Vast.ai 模式、整合個人供應商 GPU 的「Community Cloud(社區雲)」層級。
公司已獲得風險投資,並擁有一支全職的工程和支持團隊。這種機構背景轉化為更精緻的使用者體驗、官方維護的模板以及及時的客戶服務——這些都是純 P2P 平台難以提供的「奢侈品」。
RunPod 的定位強調易用性。該平台針對的是希望快速部署 GPU 負載而無需深厚基礎設施背景的用戶。針對 Stable Diffusion WebUI、文本生成推理伺服器和 Jupyter 筆記本的一鍵模板將配置時間從幾小時縮短到了幾分鐘。
RunPod 核心特徵:
- 結合託管數據中心和社區 GPU 的混合模式
- Secure Cloud 層級價格固定且可預測
- 針對常見 AI 負載提供豐富的預建模板
- 按秒計費,消除不足一小時的使用浪費
- 活躍的 Discord 社區,官方支持響應迅速
- 提供適用於推理負載的 Serverless GPU 選項
Vast.ai:純市場化平台
Vast.ai 在 2019 年成立時開創了點對點(P2P)GPU 租賃模式。該平台將個人 GPU 持有者(從擁有遊戲主機的發燒友到運行小型私有數據中心的運營商)直接與需要計算資源的用戶聯繫起來。
這種純市場化的方法產生出了行業內最低的价格。由於沒有數據中心管理開銷或託管基礎設施成本,GPU 持有者能夠以低於任何其他選項的價格獲利出租。其代價是波動性:不同的供應商提供的可靠性、網絡性能和硬體質量水平參差不齊。
Vast.ai 吸引的是對成本敏感、且擅長根據可靠性評分、地理位置和硬體規格評估單個供應商的用戶。平台為每個列表提供詳細的指標,以便用戶在價格和可靠性之間做出權衡決策。
Vast.ai 核心特徵:
- 無託管基礎設施的純 P2P 市場
- 基於供需關係的競拍式定價
- GPU 租賃市場中絕對價格最低
- 詳盡的供應商可靠性指標和評分
- 硬體選擇廣泛,包含最新的消費級 GPU
- 需要用戶具備較高的技術辨別能力才能高效使用
定價對比
價格是這兩個平台之間最顯著的區別因素。兩者都比企業級雲服務便宜得多,但對於預算有限的項目來說,它們之間的差距依然具有重要意義。
消費級 GPU 定價
RTX 4090 和 RTX 3090 等消費級 GPU 為大多數 AI 工作負載提供了最佳的性價比。AWS、Azure 和 GCP 均不提供這些 GPU——這是 RunPod 和 Vast.ai 的共同重大優勢。
| GPU | RunPod Secure Cloud | RunPod Community | Vast.ai 價格範圍 | Vast.ai 平均價 |
|---|---|---|---|---|
| RTX 5090 (32GB) | $0.89/小時 | $0.55-0.85/小時 | $0.38-1.08/小時 | $0.65/小時 |
| RTX 4090 (24GB) | $0.59/小時 | $0.44-0.55/小時 | $0.29-0.78/小時 | $0.45/小時 |
| RTX 3090 (24GB) | $0.46/小時 | $0.32-0.40/小時 | $0.18-0.60/小時 | $0.35/小時 |
| RTX A6000 (48GB) | $0.49/小時 | $0.40-0.48/小時 | $0.40-0.70/小時 | $0.52/小時 |
分析: Vast.ai 的最低價格比 RunPod 便宜 30-50%,但要獲得這些費率,通常需要選擇可靠性評分較低或位置較偏的供應商。在均價水平下,兩者的差距縮小到 15-25%。
數據中心級 GPU 定價
對於需要數據中心級硬體的工作負載——如大語言模型、多卡並行訓練、生產環境推理——兩個平台提供的 A100 和 H100 價格較巨頭服務商都有大幅折扣。
| GPU | RunPod Secure Cloud | RunPod Community | Vast.ai 價格範圍 | AWS 等效價格 |
|---|---|---|---|---|
| A100 40GB | 不適用 | $1.09-1.29/小時 | $0.80-1.20/小時 | 約 $4.10/小時 |
| A100 80GB | $1.39-1.49/小時 | $1.19-1.35/小時 | $0.84-1.49/小時 | 約 $4.10/小時 |
| H100 80GB | $2.39/小時 | $1.89-2.29/小時 | $1.47-2.94/小時 | 約 $6.90/小時 |
| L4 24GB | $0.39/小時 | $0.29-0.35/小時 | $0.35-0.50/小時 | $0.80/小時 |
分析: 在數據中心 GPU 方面,兩個平台比 AWS 節省 60-75%。對於高端硬體,RunPod 和 Vast.ai 之間的差距會縮小,因為此類硬體對可靠性要求更高,且市場上的供應商較少。
定價模式差異
除了原始費率外,定價模式在以下方面也存在顯著差異:
RunPod Secure Cloud:
- 價格固定,不隨需求波動
- 實例啟動後保證可用性
- 無競價或拍賣機制
- 成本可預測,便於預算管理
RunPod Community Cloud:
- 價格隨供應商而異
- 供應商自行設定費率
- 如果供應商需要收回硬體,任務可能會被中斷
- 經濟性類似於競價實例(Spot Instance)
Vast.ai:
- 基於供需關係的動態定價
- 供應商設定底價,市場決定實際費率
- 需求高峰期價格可能飆升
- 在非高峰時段可獲得顯著優惠
如需全面了解所有主流服務商(包括企業雲選項)的 GPU 租賃定價,請參閱我們的 2026 年 GPU 租賃價格對比全指南。
真實成本案例:訓練 LoRA 模型
為了說明實際成本差異,以訓練一個 Stable Diffusion LoRA 模型為例——這是常見的工作負載,在 RTX 4090 上大約耗時 2 小時。
| 平台 | GPU 選擇 | 每小時費率 | 2小時總計 |
|---|---|---|---|
| RunPod Secure | RTX 4090 | $0.59 | $1.18 |
| RunPod Community | RTX 4090 (中位數價格) | $0.49 | $0.98 |
| Vast.ai | RTX 4090 (99%+ 可靠性) | $0.52 | $1.04 |
| Vast.ai | RTX 4090 (97%+ 可靠性) | $0.38 | $0.76 |
RunPod Secure 與最便宜的 Vast.ai 選項之間 0.42 美元的差價在多次訓練中會積少成多。如果是 50 次訓練,將節省 21 美元——對獨立開發者很有意義,但對於專業應用來說,可能不值得為此承擔可靠性方面的風險。
有關 LoRA 訓練工作流(包括 GPU 選擇和成本優化)的詳細指導,請參閱我們的 10 美元以內訓練 Stable Diffusion LoRA 模型指南。
可靠性與在線率
除了價格之外,可靠性是區分 GPU 租賃平台的最大因素。如果您的訓練任務在 12 小時工作進度的第 11 小時由於硬體不可靠而崩潰,那麼便宜一半的价格也毫無意義。
RunPod 可靠性架構
Secure Cloud 層級: RunPod 的 Secure Cloud 在採用標準化配置的託管數據中心運行硬體。公司控制環境、維護硬體並對在線率負責。雖然 RunPod 沒有發布 Secure Cloud 的正式 SLA 數據,但用戶反饋和我的個人經驗表明,其可用性在 99.5% 以上。
Secure Cloud 的硬體是獨佔的——一旦啟動實例,它就會一直保持可用直到您將其終止。供應商無法在中途回收硬體。
Community Cloud 層級: Community Cloud 的可靠性隨供應商而異,與 Vast.ai 類似。供應商根據歷史在線時間獲得可靠性評級,用戶可以篩選評級較高的供應商。平台通過供應商審核提供一定的保障,但中斷仍有可能發生。
Vast.ai 可靠性架構
Vast.ai 完全採用 P2P 模式,這意味著可靠性完全取決於單個供應商的行為。平台提供詳細指標幫助用戶評估風險:
可靠性評分(Reliability Score): 機器在出租期間可用的時間百分比。範圍通常在 92% 到 99.9% 之間。
在線歷史(Uptime History): 最近可用性的可視化呈現,顯示任何故障或中斷。
供應商入駐時長(Provider Age): 供應商在平台上的時間。時間越長,其記錄的參考價值越高。
租賃次數(Number of Rentals): 租賃次數越多,可靠性評估的數據點就越豐富。
資深用戶可以通過篩選可靠性評分 99% 以上、入駐時間 6 個月以上且位於電網穩定地區的供應商,在 Vast.ai 上獲得極佳的可靠性。然而,這種篩選會減少可選資源量,且往往會排除掉最便宜的選項。
可靠性對比矩陣
| 指標 | RunPod Secure | RunPod Community | Vast.ai (99%+ 篩選) | Vast.ai (全部) |
|---|---|---|---|---|
| 典型在線率 | 99.5%+ | 98-99% | 99%+ | 95-99% |
| 中斷風險 | 極低 | 中等 | 低 | 中等至偏高 |
| 硬體一致性 | 高 | 不穩定 | 不穩定 | 不穩定 |
| 網絡性能 | 穩定 | 不穩定 | 不穩定 | 不穩定 |
實際可靠性考量
對於 4 小時以內的訓練: 兩個平台都能提供可接受的可靠性。對於短時間任務,Vast.ai 節省的成本通常足以抵消極小的中斷風險。
對於 4-12 小時的訓練: 建議選擇 RunPod Secure Cloud,或者在 Vast.ai 上進行嚴格的可靠性篩選(99%+)。損失 8 小時訓練進度的代價通常超過了為可靠性支付的溢價。
對於 12 小時以上的訓練: 無論使用哪個平台,保存檢查點(Checkpointing)都至關重要。建議每 30-60 分鐘保存一次,這樣即使發生中斷,損失也僅限於上次保存以來的進度,而非全部。
對於生產環境推理: 除非您自己實現了故障轉移和健康檢查機制,否則 RunPod Secure Cloud 是明確的首選。生產系統需要確定的在線時間,而市場化運作的波動性無法提供此類保證。

可用硬體
這兩個平台在提供企業雲無法獲取的硬體(尤其是消費級 GPU)方面表現出色。然而,它們的庫存在各方面存在顯著差異。
消費級 GPU 可用性
| GPU 型號 | RunPod 可用性 | Vast.ai 可用性 |
|---|---|---|
| RTX 5090 (32GB) | 良好 | 中等(新型 GPU) |
| RTX 4090 (24GB) | 極佳 | 極佳 |
| RTX 4080 (16GB) | 有限 | 良好 |
| RTX 3090 (24GB) | 良好 | 極佳 |
| RTX 3080 (12GB) | 有限 | 良好 |
| RTX 3070 (8GB) | 非常有限 | 中等 |
Vast.ai 擁有更龐大的供應商群體,通常能提供更豐富的消費級硬體選擇,包括較舊或不常見的型號。RunPod 則專注於 AI 負載最熱門的選擇,優先保證 RTX 4090 和 RTX 3090 的庫存。
數據中心級 GPU 可用性
| GPU 型號 | RunPod 可用性 | Vast.ai 可用性 |
|---|---|---|
| H100 80GB | 良好 | 中等 |
| H200 140GB | 有限 | 有限 |
| A100 80GB | 極佳 | 良好 |
| A100 40GB | 良好 (社區雲) | 良好 |
| A6000 48GB | 良好 | 良好 |
| L4 24GB | 極佳 | 良好 |
| L40S 48GB | 中等 | 有限 |
| A40 48GB | 中等 | 中等 |
RunPod 為其 Secure Cloud 層級投資了大量數據中心級硬體,確保了 A100 和 H100 GPU 的穩定供應。Vast.ai 的數據中心 GPU 可用性則取決於購買或租賃了這些設備的供應商——供應情況可能較為零散。
多 GPU 配置
對於需要多卡並行的超大模型訓練,兩個平台與企業雲相比都存在局限性。
RunPod: 在 Secure Cloud 中提供最高支持 8x A100 或 8x H100 的多卡 Pod。社區雲的多卡可用性較低且不穩定。
Vast.ai: 多卡系統雖然存在但很稀缺。尋找 4x 或 8x GPU 系統需要耐心和靈活的時間安排。擁有多卡系統的供應商通常會收取溢價。
兩個平台都無法完全匹配 AWS p4d 實例或 Azure ND 系列的多卡可用性。對於大規模的 8 卡訓練,為了保證可用性,企業雲仍然是必要的。
使用者體驗與介面
RunPod 和 Vast.ai 之間的使用者體驗差異反映了它們不同的理念和目標用戶。
RunPod 介面
RunPod 的介面優先考慮非基礎設施專家的易用性。控制面板清晰地展示了可用 GPU 及其價格,只需點擊幾次即可完成部署,預配置模板處理了大部分環境設置。
優點:
- 介面整潔現代,導航直觀
- 針對常見工作負載提供模板庫
- Stable Diffusion、LLM 推理等一鍵部署
- 集成 JupyterLab 訪問,無需額外配置
- 行動端適配良好,方便隨時監控
缺點:
- 篩選選項不如 Vast.ai 細致
- 社區雲供應商的選擇資訊不夠詳盡
- 進階配置需要深入設置菜單
Vast.ai 介面
Vast.ai 的介面面向的是對基礎設施決策遊刃有餘的用戶。市場視圖提供了極其豐富的篩選功能和詳細的供應商資訊,使用戶能夠精準地將需求與可用硬體匹配。
優點:
- 詳細的供應商指標(可靠性、網速、地理位置)
- 可按 GPU 顯存、磁碟空間和網絡頻寬進行進階篩選
- 支持價格排序和基於競價的價格選項
- 供應商歷史和評級透明
- 提供用於程序化訪問的 CLI 工具
缺點:
- 新用戶學習曲線較陡峭
- 介面資訊過於密集,顯得擁擠
- 模板系統不如 RunPod 精緻
- 部署前需要做出更多決策
實例管理對比
| 功能 | RunPod | Vast.ai |
|---|---|---|
| 首台 GPU 獲取時間 | 2-5 分鐘 | 2-5 分鐘 |
| 模板部署 | 一鍵式 | 手動或模板 |
| SSH 訪問 | 支持 | 支持 |
| Web 終端 | 支持 | 支持 |
| JupyterLab | 已集成 | 需手動設置 |
| 檔案瀏覽器 | 支持 | 有限支持 |
| 停止/恢復 | 支持 | 支持 |
| 按秒計費 | 支持 | 支持 |
模板與預配置環境
模板能顯著縮短常見任務的生產準備時間。兩個平台都提供模板系統,但在精緻程度和覆蓋面上有所不同。
RunPod 模板
RunPod 為主要的 AI 負載維護著官方模板:
Stable Diffusion:
- Automatic1111 WebUI
- ComfyUI
- Forge WebUI
- InvokeAI
LLM 推理:
- Text Generation WebUI (Oobabooga)
- vLLM
- Ollama
- 兼容 OpenAI 的 API 伺服器
開發環境:
- 帶有 CUDA 的 PyTorch
- 帶有 CUDA 的 TensorFlow
- Jupyter 筆記本
- VS Code Server
其他:
- Whisper(語音識別)
- 音樂生成模型
- 自定義容器支持
這些模板包含正確的 CUDA 配置,在適當情況下提供預下載模型,以及合理的默認設置。新用戶在創建帳戶後 10 分鐘內即可開始生成圖像。
Vast.ai 模板
Vast.ai 的模板系統篩選較少,但更為靈活:
官方模板:
- 基礎 CUDA 開發環境
- Jupyter 筆記本配置
- 常見機器學習框架設置
社區模板:
- 用戶提交的配置
- 質量和維護情況參差不齊
- 種類繁多但文檔說明不一致
Docker 集成:
- 全面的 Docker 鏡像支持
- 可拉取任何公共鏡像
- 構建自定義鏡像
Vast.ai 這種以 Docker 為核心的方法為清楚自己需求的用户提供了極大的靈活性。然而,缺乏維護良好的官方模板意味著在處理常見用例時需要更多的配置工作。
模板對比
| 工作負載 | RunPod | Vast.ai |
|---|---|---|
| Stable Diffusion | 一鍵部署,多種 UI 可選 | 手動或社區模板 |
| LLM 推理 | 多種選擇,一鍵部署 | 手動設置 |
| 訓練 (PyTorch) | 提供模板 | 提供模板 |
| 自定義容器 | 支持 | 完美支持 |
| 配置時間 (常見負載) | 5-10 分鐘 | 15-30 分鐘 |
對於運行標準 AI 工作負載的用戶,RunPod 的模板優勢能節省大量時間。對於有特殊要求或精通 Docker 的用戶,Vast.ai 的靈活性可能更具吸引力。
存儲與數據傳輸
存儲和數據傳輸的考量往往會讓新用戶感到意外。GPU 成本是顯性的,而存儲數據集和移動數據的隱性成本同樣不可忽視。
RunPod 存儲
Pod 存儲:
- 每個 Pod 包含可配置的磁碟空間
- 容器存儲在 Pod 存在期間持續保留
- 價格包含在 Pod 小時費率內(有一定限額)
- 超出部分存儲空間單獨計費
網絡卷存儲 (Network Volume):
- 持久化存儲,Pod 銷毀後數據依然存在
- 每 GB 每月 0.07 美元
- 可掛載到同一區域的 Pod 上
- 非常適合存放數據集和模型權重
數據傳輸:
- 無額外數據傳輸費用
- 下載速度因數據中心而異
- 上傳速度通常極佳
Vast.ai 存儲
實例存儲:
- 磁碟空間由供應商決定
- 不同供應商之間差異巨大
- 有些僅提供少量 SSD 空間;有些則提供數 TB 空間
- 存儲費用包含在小時費率中
持久化存儲:
- 無原生持久化存儲產品
- 用戶需自行管理存儲方案
- 常見做法:雲存儲同步、外部伺服器
- 相比 RunPod,跨會話處理數據集更為複雜
數據傳輸:
- 平台不收取傳輸費用
- 網絡速度因供應商而異,波動巨大
- 選擇供應商時需重點查看的關鍵指標
- 某些供應商的頻寬非常有限
存儲成本對比
假設一個需要 100GB 持久化存儲的典型工作流:
| 存儲需求 | RunPod | Vast.ai |
|---|---|---|
| 數據集存儲 (100GB, 1 個月) | $7.00 | 需使用外部方案 |
| 模型權重 (50GB, Pod 已包含) | $0 | $0 |
| 數據傳輸 | 免費 | 免費 |
RunPod 的網絡卷功能為需要跨會話數據持久化的用戶提供了極大便利。Vast.ai 用戶通常需要在兩次租賃會話之間同步雲存儲(如 S3, GCS 等),這增加了複雜度並可能消耗傳輸時間。
付款方式
支付靈活性對於國際用戶、不使用傳統銀行服務的用戶以及有特定採購要求的機構非常重要。
RunPod 付款方式
- 信用卡和簽帳卡 (Visa, Mastercard, American Express)
- 加密貨幣 (Bitcoin, Ethereum, USDC)
- 預充值帳戶餘額
- 企業帳戶無帳單支付選項(僅限自助服務)
RunPod 對加密貨幣的支持值得關注——許多雲平台完全拒絕加密支付。其實現方式簡單直接:充值加密貨幣,換取帳戶餘額,用於租用 GPU。
Vast.ai 付款方式
- 信用卡和簽帳卡
- 預充值帳戶餘額
- 不支持加密貨幣
- 無帳單支付選項
Vast.ai 較窄的支付渠道可能會影響偏好加密貨幣或需要正式商業發票入帳的用戶。
帳戶要求
| 要求 | RunPod | Vast.ai |
|---|---|---|
| 信箱驗證 | 是 | 是 |
| 手機驗證 | 否 | 否 |
| 身份驗證 (KYC) | 否 | 否 |
| 企業認證 | 否 | 否 |
| 最低充值額 | 無 | 無 |
兩個平台都維持了較低的入場門檻。兩者都不需要企業級雲服務商強制要求的大規模驗證。這種便捷性也伴隨著權衡——兩個平台都無法提供大型機構可能需要的合規性證明文件。
支持與文檔
當出現問題時——這終究會發生——支持的質量決定了您恢復的速度。
RunPod 支持
渠道:
- Discord 社區(非常活躍)
- 郵件支持
- 文檔維基 (Wiki)
- 視頻教程
響應時間:
- Discord:工作時間內通常幾分鐘內響應
- 郵件:通常 24-48 小時
- 社區提問:經常由工作人員直接回答
RunPod 的 Discord 活躍度對於這種規模的公司來說是出類拔萃的。工作人員積極監控頻道並頻繁回答用戶問題。顯然,公司將社區建設作為其核心支持策略。
其文檔很好地涵蓋了常見工作流,但有時會滯後於新功能的發布。視頻教程對視覺學習者很有幫助,但覆蓋面不夠全面。
Vast.ai 支持
渠道:
- Discord 社區
- 郵件支持
- 文檔
- 常見問題解答 (FAQ)
響應時間:
- Discord:不固定,通常由社區成員回答
- 郵件:通常 24-72 小時
- 社區頻道中的官方存在感較低
Vast.ai 的支持體現了其純市場的性質。公司在租戶和供應商之間充當仲裁者,但對基礎設施的控制較弱,因此解決特定技術問題的能力有限。供應商側的問題通常需要直接與具體供應商溝通。
其文檔足以應對基本操作,但在特定工作負載的指導上不如 RunPod 詳盡。
支持能力對比
| 維度 | RunPod | Vast.ai |
|---|---|---|
| 社區活躍度 | 極高 | 中等 |
| 官方響應 | 頻繁 | 偶爾 |
| 文檔深度 | 良好 | 足夠 |
| 視頻內容 | 有 | 較少 |
| 自助解決問題的便捷度 | 高 | 中等 |
安全考量
託管平台與 P2P 市場的安全關注點有所不同。理解威脅模型有助於做出正確選擇。
RunPod 安全模型
Secure Cloud:
- 硬體位於託管的數據中心
- 標準的數據中心物理安全
- RunPod 控制整個基礎設施技術棧
- 用戶之間實現容器隔離
- 租戶無法訪問裸機
社區雲:
- 硬體由供應商控制
- 供應商擁有硬體的物理接觸權限
- 存在潛在惡意供應商風險(極罕見但理論上存在)
- 有容器隔離但無絕對保證
Vast.ai 安全模型
- 所有硬體均由單個供應商控制
- 供應商擁有物理和管理訪問權限
- 雖有詳盡的供應商審核但非萬無一失
- 容器隔離程度取決於供應商的配置
- 某些供應商可能會記錄或檢查流量
實際安全建議
對於敏感任務(自有模型、機密數據):
- 務必僅使用 RunPod Secure Cloud
- 如果有合規要求,請考慮企業級雲服務
- 切勿在 P2P 市場 GPU 上處理敏感數據
對於非敏感任務(公開模型、合成數據):
- 兩個平台均可接受
- 擁有長期記錄和高評級的供應商風險較低
- 需遵循標準安全準則(不要硬編碼憑證等)
針對任何負載:
- 避免在訓練腳本中留下帳號密碼
- 使用環境變量存儲 API 密鑰
- 在終止實例前清理數據
- 假設供應商可能會在實例終止後檢查磁碟內容
真實性能實測對比
單純的定價和功能固然重要,但 GPU 能否達到預期表現才是關鍵。我在兩個平台上運行了完全相同的任務,以測量實際差異。
測試方法
硬體配置: RTX 4090 24GB 工作負載 1: Stable Diffusion XL 圖像生成(50 張圖像,每張 30 步) 工作負載 2: LoRA 訓練(50 張圖像,10 個 Epoch) 工作負載 3: LLM 推理(Llama 2 7B,生成 1000 個 Token)
每項測試在每個平台上運行三次,Vast.ai 選擇了中等水平的供應商(可靠性 98% 以上,價格居中)。
性能結果
| 工作負載 | RunPod Secure | Vast.ai (98%+ 供應商) | 差異 |
|---|---|---|---|
| SDXL 生成 (50 張圖) | 4分 32秒 | 4分 28秒 | -1.5% |
| LoRA 訓練 (10 Epochs) | 52分 14秒 | 53分 41秒 | +2.7% |
| LLM 推理 (1000 Tokens) | 28秒 | 29秒 | +3.6% |
分析: 對於計算密集型工作負載,性能差異幾乎可以忽略不計。RTX 4090 在兩個平台上都是相同的芯片,底層硬體並不在乎所有者是誰。
Vast.ai 在訓練和推理中的輕微延遲可能反映了網絡開銷而非 GPU 性能。從實際使用角度來看,這些差異完全處於正常波動範圍內。
網絡性能
網絡性能的差異則更為顯著:
| 指標 | RunPod Secure | Vast.ai 平均水平 | Vast.ai 最佳表現 |
|---|---|---|---|
| 下載速度 | 500+ Mbps | 200-400 Mbps | 800+ Mbps |
| 上傳速度 | 400+ Mbps | 150-300 Mbps | 600+ Mbps |
| 延遲穩定性 | 高 | 不穩定 | 高 |
對於涉及大量數據傳輸的任务(如大型數據集下載、頻繁的模型上傳),RunPod 穩定的網絡表現能節省可觀的時間。而對於純計算任務,網絡差異的影響較小。
各平台的最佳應用場景
基於對價格、可靠性和功能的分析,以下是針對常見場景的具体建議。
在以下情況下選擇 RunPod Secure Cloud:
生產級推理系統: 生產環境對可靠性的要求使得 RunPod 的溢價物有所值。凌晨 2 點掉線的推理伺服器帶來的損失遠超那點差價。
有明確截止時間的訓練任務: 當交付期限至關重要時,確定的可用性遠比寄希望於 Vast.ai 供應商不掉線更靠譜。適度的成本增加是對時間流逝的有效保險。
剛入行的新手用戶: RunPod 的模板和文檔大大降低了學習門檻。建議從此開始,等摸清需求後再考慮 Vast.ai。
擁有共享資源的團隊: RunPod 的組織管理功能和持久化存儲使團隊協作比在多個 Vast.ai 供應商之間協調要容易得多。
在以下情況下選擇 Vast.ai:
預算受限的探索���研究: 在學習或實驗階段,Vast.ai 節省的 30-40% 成本能讓您在固定預算內進行更多次迭代。探索階段的任務中斷影響相對較小。
支持檢查點保存的批量處理: 能夠定期保存檢查點的工作負載可以容忍供應商中斷。配合正確的檢查點策略,長週期訓練任務的成本節省非常可觀。
特殊的硬體需求: 需要某些特定的舊款 GPU?Vast.ai 龐雜的供應商庫中可能存有 RunPod 不再提供的型號。
夜間或週末訓練: Vast.ai 在非高峰時段的價格會大幅下降。如果您能接受可靠性波動,在週五晚上啟動長耗時訓練任務非常划算。
兩者皆可勝任的場景:
LoRA 訓練 (2-4 小時): 兩個平台都能很好地處理此類任務。根據即時價格和可用性選擇即可。
Stable Diffusion 創作: 交互式生成會話在任一平台上表現都很好。1 小時的會話中出現可靠性問題的風險極低。
一次性實驗: 在投入長時間運行前驗證想法的小型測試,在兩個平台上的表現基本一致。
遷移注意事項
只要做好準備,在兩個平台之間切換並不困難。兩者都採用了標準的容器技術和 SSH 訪問方式。
數據遷移
數據集與模型權重:
- 存儲在兩個平台都能訪問的雲存儲(如 S3, GCS, Backblaze B2)中。
- 避免過度依賴平台特定的持久化存儲。
- 會話開始時,直接從雲端下載到實例中。
代碼與配置:
- 所有代碼使用 Git 倉庫管理。
- 將配置文件存儲在版本控制系統中。
- 腳本中避免使用平台特定的硬編碼路徑。
容器鏡像:
- 兩個平台均支持 Docker Hub 和私有鏡像倉庫。
- 自定義鏡像在兩個平台上均可運行。
- 在入口腳本 (Entrypoint) 中屏蔽平台差異。
工作流可移植性
一個通用的設置腳本可以讓您在任意平台上運行:
# 通用設置腳本示例
#!/bin/bash
# 克隆代碼庫
git clone https://github.com/yourrepo/training-code.git
# 從雲存儲同步數據集
aws s3 sync s3://your-bucket/dataset ./dataset
# 下載模型權重
wget https://huggingface.co/model/weights.safetensors -O ./models/
# 運行訓練
python train.py --config ./config.yaml
# 上傳結果
aws s3 sync ./output s3://your-bucket/results/該腳本在 RunPod 或 Vast.ai 上運行效果相同,僅需提供相應的雲存儲訪問憑證。
其他備選方案
雖然 RunPod 和 Vast.ai 主導了 GPU 算力租賃市場,但根據需求,以下選項也值得考慮。
Lambda Labs
Lambda Labs 提供價格固定且專注於機器學習的託管 GPU 雲。其定價介於企業雲與算力市場之間。對於追求穩定、不願應對算力市場複雜度,且願意支付適度溢價的用戶來說是理想選擇。
GPUFlow
GPUFlow 運營著一個基於區塊鏈支付處理的點對點市場。通過智能合約處理託管,無需中心化機構即可消除違約風險。主要優勢包括:無需 KYC 的加密貨幣支付、更低的平台手續費(10-15% 對比 20-30%)以及快速的實例交付。適合偏好去中心化基礎設施的用戶。
企業級雲服務 (AWS, Azure, GCP)
若有合規性要求、明確的 SLA 協議及企業級支持需求,大廠依然不可或缺。3-5 倍的溢價換來的是算力市場無法提供的能力:SOC2 認證、HIPAA 合規、專屬支持工程師以及合同保障的在線率。
購置硬體
當規模足夠大時,自購硬體才具有經濟性。通常,消費級 GPU 的盈虧平衡點在累計使用 2,500 到 3,000 小時左右。運行持續性工作負載的機構應評估總擁有成本 (TCO) 與租賃成本的差異。
常見問題解答
租用 GPU 是 RunPod 還是 Vast.ai 更便宜?
Vast.ai 通常價格更低,因為它是一個純粹的 P2P 市場。Vast.ai 上的 RTX 4090 價格低至每小時 0.29 美元,而 RunPod 的 Secure Cloud 則為 0.59 美元。然而,要獲得 Vast.ai 的最低價,必須犧牲一定的可靠性。在同等可靠性水平(99% 以上)下,兩者的價格差距會縮小到 15-25%。
哪個平台對生產環境負載更可靠?
RunPod 的 Secure Cloud 更可靠,因為它使用精選的數據中心硬體並由官方負責維護。Vast.ai 的可靠性取決於具體的個體供應商,通常在 97% 到 99.9% 之間波動。對於追求高在線率的任務,RunPod 是更穩妥的选择。
我可以在這兩個平台上使用 RTX 4090 等消費級 GPU 嗎?
可以。RunPod 和 Vast.ai 均提供 RTX 3090、RTX 4090 和 RTX 5090 等消費級 GPU。而 AWS、Azure 等大廠僅提供 A100、H100 等數據中心型號。對於大多數 AI 任務,消費級 GPU 提供了極佳的性價比。
哪個平台針對 AI 負載有更好的預配置模板?
RunPod 擁有更完善的官方模板,支持 Stable Diffusion(多種 UI)、各種 LLM 推理伺服器及主流訓練框架的一鍵部署。這些模板由官方維護並預裝了正確的 CUDA 配置。Vast.ai 則多依賴質量參差不齊的社區模板。
RunPod 和 Vast.ai 是否需要身份驗證?
基礎使用均不需要完整的 KYC 驗證。RunPod 僅需信箱驗證和支付方式,Vast.ai 需求更少。相比之下,企業級雲服務商往往需要商業實名認證和信用調查。
如何為特定項目選擇平台?
考慮三個因素:可靠性要求、預算限制和配置時間成本。生產系統或緊急任務首選 RunPod Secure Cloud;研究性或低預算項目首選 Vast.ai。新手建議從 RunPod 的模板開始,專家則可能更喜歡 Vast.ai 的靈活性。
我可以輕鬆地在平台間切換嗎?
可以。兩者都支持標準 SSH 和 Docker 容器。通過將數據集存放在雲端、代碼存放在 Git,遷移通常只需幾個小時的熟悉時間即可完成。
最終總結建議
在深度使用過兩個平台後,我的建議如下:
在以下情況下優先選擇 RunPod:
- 您是 GPU 租賃的新手
- 您需要生產環境級別的穩定性
- 官方模板對您的工作流很重要
- 您看重及時的官方支持
在以下情況下優先選擇 Vast.ai:
- 成本優化是您的頭等大事
- 您具備豐富的基礎設施管理經驗
- 您的任務可以容忍偶爾的中斷
- 您樂於篩選和優化各種資源選項
在以下情況下考慮 GPUFlow:
- 您偏好加密貨幣付款
- 您不希望參與任何 KYC 認證
- 更低的平台手續費對您的成本模型有顯著影響
- 您追求基於區塊鏈驗證的支付安全性
好消息是:無論選擇 RunPod 還是 Vast.ai,與企業級雲服務相比,它們都提供了極高的價值,通常能節省 60-80% 的成本。兩者之間的差異雖然重要,但與它們共同帶來的巨額節省相比,則是次要的。
對於長期項目,我建議在兩個平台上都保留帳號。將 RunPod 用於關鍵任務,將 Vast.ai 用於成本敏感的實驗和批量處理。這種靈活性不僅能最大化成本效率,還能在可靠性最關鍵的時候提供保障。
尋找支持加密貨幣付款且具有智能合約安全保障的 GPU 租賃服務? GPUFlow 提供極具競爭力的市場費率,支持區塊鏈驗證的託管服務,手續費更低且無需 KYC。立即訪問 gpuflow.app 查看即時庫存和價格。
相關指南:
本對比最後更新於 2026 年 2 月 12 日。平台功能和價格變動頻繁,決策前請直接在 RunPod 和 Vast.ai 官網核實最新資訊。