
The memo satisfies no one but changes everything.
When Samsung’s semiconductor division discovered that engineers had uploaded proprietary chip designs to ChatGPT, the response was immediate and absolute. A company-wide ban. No exceptions. No appeals process. The tool that had become synonymous with AI productivity was now prohibited on all corporate networks.
Samsung was not alone. Within months, similar announcements emerged from JPMorgan Chase, Apple, Amazon, Goldman Sachs, Deutsche Bank, and dozens of other enterprises. Law firms that counsel Fortune 500 companies prohibited associates from using the service. Healthcare systems blocked access at the firewall level. Government agencies issued guidance that effectively ended any ambiguity about acceptable use.
The pattern revealed something that technology enthusiasts had overlooked in their excitement about AI capabilities: enterprise adoption operates under constraints that consumer adoption does not.
This article examines why corporate AI policies are tightening, what specific risks drive these decisions, and how organizations can maintain AI capabilities without accepting unacceptable data exposure. The path forward does not require abandoning AI. It requires understanding that the infrastructure matters as much as the intelligence.

The Incidents That Changed Everything
Corporate AI bans did not emerge from theoretical risk assessments. They followed actual incidents where confidential information escaped organizational control.
The Samsung Semiconductor Breach
In early 2023, Samsung Electronics employees used ChatGPT to debug source code and optimize semiconductor manufacturing processes. Engineers pasted proprietary code directly into the chat interface. Others uploaded meeting notes containing strategic planning discussions. Within three weeks of ChatGPT being permitted for internal use, Samsung’s information security team identified multiple instances of confidential data transmission to OpenAI servers.
The semiconductor industry operates on margins measured in nanometers and competitive advantages measured in months. The possibility that Samsung’s fabrication processes now resided in OpenAI’s training corpus—potentially accessible to competitors using the same service—was unacceptable. Samsung implemented a complete ban and began developing internal AI tools that would never transmit data externally.
Financial Services Industry Response
JPMorgan Chase restricted ChatGPT access before any publicized incident, recognizing the regulatory implications proactively. When bank employees analyze customer portfolios, discuss merger strategies, or evaluate credit risks, they handle information subject to SEC regulations, banking secrecy laws, and fiduciary duties. Transmitting such information to a third-party AI service—regardless of that service’s stated privacy policies—creates compliance exposure that no general counsel would accept.
Goldman Sachs, Citigroup, Bank of America, and Deutsche Bank followed with similar restrictions. The financial services industry’s coordinated response reflected not paranoia but professional understanding of regulatory liability. A data breach originating from employee ChatGPT usage would require disclosure, trigger regulatory investigation, and potentially result in enforcement action.
Legal Industry Implications
The American Bar Association has not issued a blanket prohibition on AI tools, but the practical effect of attorney-client privilege requirements approximates one. When a lawyer discusses client matters with ChatGPT, the conversation may waive privilege protection. Information disclosed to third parties—even AI systems—can lose the confidentiality that makes legal advice protected.
Major law firms including Davis Polk, Cravath, and Sullivan & Cromwell implemented restrictions varying from complete bans to approved-use-only policies requiring partner authorization. The legal profession’s response demonstrated that AI risks extend beyond data security into fundamental questions of professional responsibility.
The Technical Reality of Cloud AI Data Handling
Understanding why enterprises ban ChatGPT requires examining what actually happens when you send a message to a cloud AI service.
Data Transmission Path
When you type a prompt into ChatGPT, your text travels from your device through your corporate network, across the public internet, to OpenAI’s infrastructure. OpenAI operates primarily on Microsoft Azure, meaning your data transits Microsoft’s network and resides on Microsoft-managed servers.
This transmission occurs regardless of content sensitivity. The system cannot distinguish between a request to write a poem and a request to analyze confidential merger terms. Every character you input follows the same path to the same destination.
Data Retention Policies
OpenAI’s data usage policies have evolved over time, but certain fundamentals remain consistent. User inputs are logged. Conversations are stored. The duration and purpose of storage depend on your subscription tier and specific agreements.
For free-tier and Plus subscribers, OpenAI explicitly reserves the right to use inputs for model improvement. Your prompts become training data. The confidential code you pasted to debug a problem may influence how the model responds to future users—potentially including your competitors.
API users and Enterprise subscribers can opt out of training data contribution, but their inputs still process on OpenAI infrastructure. Data still exists on servers you do not control, managed by employees you have not vetted, subject to legal processes you cannot influence.
The Third-Party Problem
Enterprise security architectures distinguish between first-party systems (infrastructure you own and operate), second-party systems (vendors with direct contractual relationships and audited security controls), and third-party systems (services accessed without detailed security integration).
ChatGPT, for most users, operates as an unaudited third party. Unless your organization has negotiated a specific enterprise agreement with security addenda, penetration testing rights, and compliance certifications mapped to your requirements, ChatGPT sits outside your security perimeter with access to whatever data employees choose to share.
This architectural reality explains why security teams treat ChatGPT differently than they treat Microsoft Office or Salesforce. Those systems, despite being cloud-based, operate under enterprise agreements with defined security controls, audit rights, and liability terms. ChatGPT, for a user with a $20/month subscription, offers none of those protections.
Regulatory Frameworks Driving Enterprise Caution
Corporate AI policies do not exist in a vacuum. They respond to legal requirements that predate ChatGPT and will outlast it.
GDPR and European Data Protection
The General Data Protection Regulation imposes strict requirements on processing personal data of EU residents. When an employee pastes customer information into ChatGPT, they initiate a data transfer to a US-based processor. This transfer requires legal basis—either adequacy decisions, standard contractual clauses, or binding corporate rules.
OpenAI’s data processing agreements may satisfy GDPR requirements for some use cases, but most employees using the consumer product have no such agreement in place. They are simply transmitting personal data to a foreign corporation without authorization.
Italian regulators temporarily banned ChatGPT in 2023 specifically over GDPR concerns. While the service resumed after OpenAI made compliance adjustments, the incident demonstrated regulatory willingness to act. European enterprises face direct liability for employee actions that violate GDPR, creating strong incentives for restrictive policies.
HIPAA and Healthcare Data
The Health Insurance Portability and Accountability Act prohibits disclosure of protected health information (PHI) except under specific authorized circumstances. A healthcare worker discussing patient cases with ChatGPT discloses PHI to an unauthorized recipient.
No business associate agreement exists between typical healthcare organizations and OpenAI. No security audit has verified ChatGPT’s compliance with HIPAA technical safeguards. No legal framework authorizes the disclosure.
Healthcare organizations that discover employees have shared PHI via ChatGPT face breach notification requirements, potential OCR investigation, and penalties reaching $1.5 million per violation category per year. These consequences explain why hospital systems block ChatGPT at the network level rather than relying on policy compliance.
Financial Regulations
Banks, broker-dealers, and investment advisers operate under SEC, FINRA, OCC, and Federal Reserve regulations that mandate recordkeeping and supervision of business communications. When an analyst uses ChatGPT to draft client correspondence, that conversation should be captured in compliance archives.
ChatGPT provides no integration with enterprise archiving systems. No supervision tools flag potentially problematic usage. The conversation exists only on OpenAI’s servers and the employee’s device—neither of which satisfy regulatory recordkeeping requirements.
Beyond recordkeeping, financial regulators express concern about AI-generated investment advice, AI involvement in credit decisions, and AI analysis that could constitute market manipulation. The regulatory landscape remains unsettled, and compliance officers respond to uncertainty by restricting usage rather than permitting it pending clarity.
Emerging AI-Specific Regulation
The European AI Act, expected to take effect progressively through 2025 and 2026, will impose additional requirements on AI system deployment. High-risk AI applications—including those affecting employment, credit, and education—require conformity assessments, documentation, and human oversight.
Organizations using ChatGPT in these contexts may find themselves operating non-compliant AI systems once regulations take effect. Proactive enterprises are restricting usage now rather than facing compliance remediation later.
Intellectual Property: The Risk No Contract Resolves
Regulatory compliance represents one category of concern. Intellectual property protection represents another—and for many enterprises, the more consequential one.
Trade Secrets and Confidentiality
Trade secret protection under the Defend Trade Secrets Act and state equivalents requires that information remain confidential through reasonable protective measures. When an employee pastes proprietary algorithms, manufacturing processes, or strategic plans into ChatGPT, the organization’s protective measures have failed.
Courts evaluating trade secret claims examine whether the claiming party took reasonable steps to maintain secrecy. Permitting employees to share confidential information with third-party AI services undermines this requirement. Even if the information never leaks from OpenAI’s systems, the act of disclosure itself may compromise legal protection.
This concern extends beyond hypothetical litigation. Companies regularly assert trade secret claims against departing employees and competitors. If discovery reveals that the “secret” information was previously shared with ChatGPT—accessible to millions of users through potential model training—the claim weakens substantially.
Source Code and Technical Assets
Software companies face particular exposure. Developers naturally want to use AI tools to debug code, generate boilerplate, and accelerate development. But source code represents the core asset of a software business. Once transmitted to ChatGPT, that code exists outside organizational control.
The training data concern is not theoretical. Large language models learn from their inputs. While OpenAI states that Enterprise and API customers can opt out of training contribution, the consumer product carries no such guarantee. Code shared by one developer may influence completions shown to another—potentially at a competing company.
Amazon’s internal warning to employees specifically cited the risk that ChatGPT responses might resemble Amazon confidential information, suggesting that similar data had already been incorporated into the model. Whether this represented actual Amazon code in training data or simply similar patterns remains unclear. The ambiguity itself drove the restrictive policy.
Client and Customer Information
Professional services firms—consultants, accountants, lawyers, architects—work with client information that belongs to those clients, not to the service provider. Sharing client data with ChatGPT may violate engagement letters, confidentiality agreements, and professional ethics rules.
A consultant who uploads a client’s financial projections to ChatGPT for analysis has shared that client’s confidential information with a third party. The consultant’s firm may face breach of contract claims, professional discipline, and loss of client relationships if discovered.
These concerns apply equally to any business handling customer data. A sales representative who pastes customer correspondence into ChatGPT to draft a response has transmitted customer communications to OpenAI. Depending on the industry and applicable agreements, this may violate customer data handling commitments.

The Inadequacy of Enterprise AI Agreements
OpenAI offers ChatGPT Enterprise specifically to address corporate concerns. Microsoft provides Azure OpenAI Service with enterprise security features. These products improve upon consumer offerings but do not eliminate fundamental concerns for high-sensitivity use cases.
What Enterprise Agreements Provide
ChatGPT Enterprise includes several meaningful improvements:
- Data is not used for model training
- SOC 2 Type 2 compliance certification
- Data encryption at rest and in transit
- SSO integration and administrative controls
- Data retention controls
These features satisfy requirements for many corporate use cases. A marketing team drafting campaign copy faces minimal risk. A customer service department generating response templates operates within acceptable parameters.
What Enterprise Agreements Cannot Provide
For regulated industries and sensitive intellectual property, enterprise agreements fall short in fundamental ways.
First, data still processes on infrastructure you do not control. Your information resides on OpenAI servers, managed by OpenAI employees, subject to OpenAI’s security practices. You trust their implementation. You trust their personnel vetting. You trust their incident response. This trust may be warranted, but it is trust nonetheless—not verification.
Second, data remains subject to legal process. A subpoena served on OpenAI could compel disclosure of your conversations. A government investigation into another customer could potentially expose shared infrastructure. National security letters and FISA court orders operate under secrecy requirements that would prevent OpenAI from notifying you of access.
Third, the attack surface includes OpenAI’s entire organization. Your security perimeter no longer ends at your network boundary. Every OpenAI employee with system access, every vendor with infrastructure access, every security vulnerability in OpenAI’s systems becomes part of your risk profile.
Fourth, exit and portability remain constrained. Your conversation history, fine-tuned behaviors, and organizational knowledge accumulated in ChatGPT belong to interactions with OpenAI’s system. Migration to an alternative requires rebuilding from scratch.
For a pharmaceutical company developing novel compounds, a defense contractor handling classified-adjacent research, or a financial institution with trading algorithms representing billions in potential value, these limitations matter. Enterprise agreements reduce risk. They do not eliminate it.
The Open-Weights Alternative
The restrictions driving corporate ChatGPT bans do not apply to AI generally. They apply specifically to cloud AI services where data leaves organizational control. A different architecture eliminates these concerns entirely.
What Open-Weights Models Provide
Open-weights models—Llama from Meta, Mistral from Mistral AI, Qwen from Alibaba, and dozens of others—provide downloadable model files that run on any compatible hardware. The model weights are public. The inference code is open source. You can execute the entire system on infrastructure you own and operate.
When you run Llama on your own server, your prompts never leave your network. No third party receives your data. No cloud service logs your queries. No training pipeline incorporates your inputs. The model runs locally, processes locally, and stores nothing beyond what you explicitly configure.
This architecture satisfies every concern that drives ChatGPT bans:
-
Regulatory compliance: Data remains within your security perimeter, subject to your controls, governed by your policies. GDPR data transfers do not occur because data does not transfer. HIPAA concerns dissolve because no disclosure to unauthorized parties takes place.
-
Intellectual property protection: Trade secrets remain secret. Source code never leaves your systems. Client confidentiality is maintained because no third party receives client information.
-
Security control: Your attack surface remains your own. You verify your security practices. You vet your personnel. You control your incident response. No external organization’s vulnerabilities affect your data.
-
Audit and compliance: Every query, every response, every model interaction can be logged according to your requirements. Regulatory recordkeeping integrates with your existing archive systems.
Capability Comparison
The natural question is whether open-weights models match ChatGPT’s capabilities. The honest answer: it depends on the use case.
For general knowledge queries, ChatGPT’s training on internet-scale data provides breadth that smaller open models cannot match. GPT-4’s reasoning capabilities on complex problems exceed what Llama-3-8B achieves.
But enterprise use cases rarely require internet-scale knowledge. A legal team analyzing contracts needs document understanding and precise language generation—capabilities where fine-tuned open models excel. A development team debugging code needs pattern recognition within specific codebases—a task where custom training dramatically outperforms generic models.
The critical insight is that fine-tuning transforms generic models into domain specialists. A Llama-3-8B model fine-tuned on your organization’s documents, coding standards, and communication patterns will outperform GPT-4 for your specific tasks while maintaining complete data isolation.
Our pillar guide on private LLM fine-tuning on decentralized GPUs provides the complete technical workflow for this process.
Infrastructure Options for Private AI Deployment
Running open-weights models requires GPU compute. Organizations have several options for acquiring this capability.
On-Premises Hardware
Purchasing NVIDIA GPUs for internal data centers provides maximum control. The hardware sits in your facility, managed by your staff, connected to your network. No external party has any access.
The challenge is capital expenditure and lead time. An NVIDIA H100 GPU costs approximately $30,000. A meaningful cluster for training requires multiple units. Procurement timelines stretch to months. Ongoing maintenance requires specialized expertise.
For large enterprises with existing data center operations, on-premises AI infrastructure represents a natural extension. For smaller organizations or those without GPU expertise, the barriers are substantial.
Private Cloud Instances
AWS, GCP, and Azure offer GPU instances that provide more control than SaaS AI products. You configure the environment. You control access. Your data processes on dedicated instances rather than shared services.
This approach improves upon ChatGPT’s architecture but retains cloud provider involvement. Your data still resides on infrastructure you do not physically control. Cloud provider employees with sufficient access could theoretically access your systems. Legal process served on the cloud provider could reach your data.
Additionally, private cloud GPU instances carry significant costs. AWS p4d.24xlarge instances (8x A100 GPUs) run approximately $32 per hour. Extended training runs or continuous inference services generate substantial monthly expenses. Availability is constrained—GPU instances frequently show waitlists or limited regional availability.
Decentralized GPU Rentals
A third option bypasses both capital expenditure and cloud provider involvement. Decentralized GPU marketplaces connect users directly with hardware owners. You rent compute capacity peer-to-peer, paying with cryptocurrency, without identity verification or cloud provider intermediation.
This model provides several advantages for privacy-conscious organizations:
-
No KYC requirements: You connect a wallet and rent hardware. No corporate accounts. No enterprise sales process. No identity documentation linking your organization to specific AI activities.
-
No cloud provider involvement: Your data processes on hardware owned by individuals, not by corporations with legal departments, government contracts, and law enforcement relationships.
-
Cost efficiency: RTX 4090 rentals run $0.40 to $0.60 per hour, approximately one-tenth the cost of comparable cloud instances. Our GPU rental pricing comparison details the economics.
-
Global availability: Decentralized supply means no regional constraints. Hardware is available when you need it, distributed across jurisdictions worldwide.
For organizations that cannot justify capital expenditure on GPU hardware but require stronger privacy guarantees than cloud providers offer, decentralized rentals provide a practical middle path.
The workflow involves transferring your data directly to the rental node via encrypted SSH connection, running your training or inference job, downloading results, and sanitizing the remote environment before disconnecting. Our guide on securing your dataset on a public GPU node covers the operational security practices in detail.
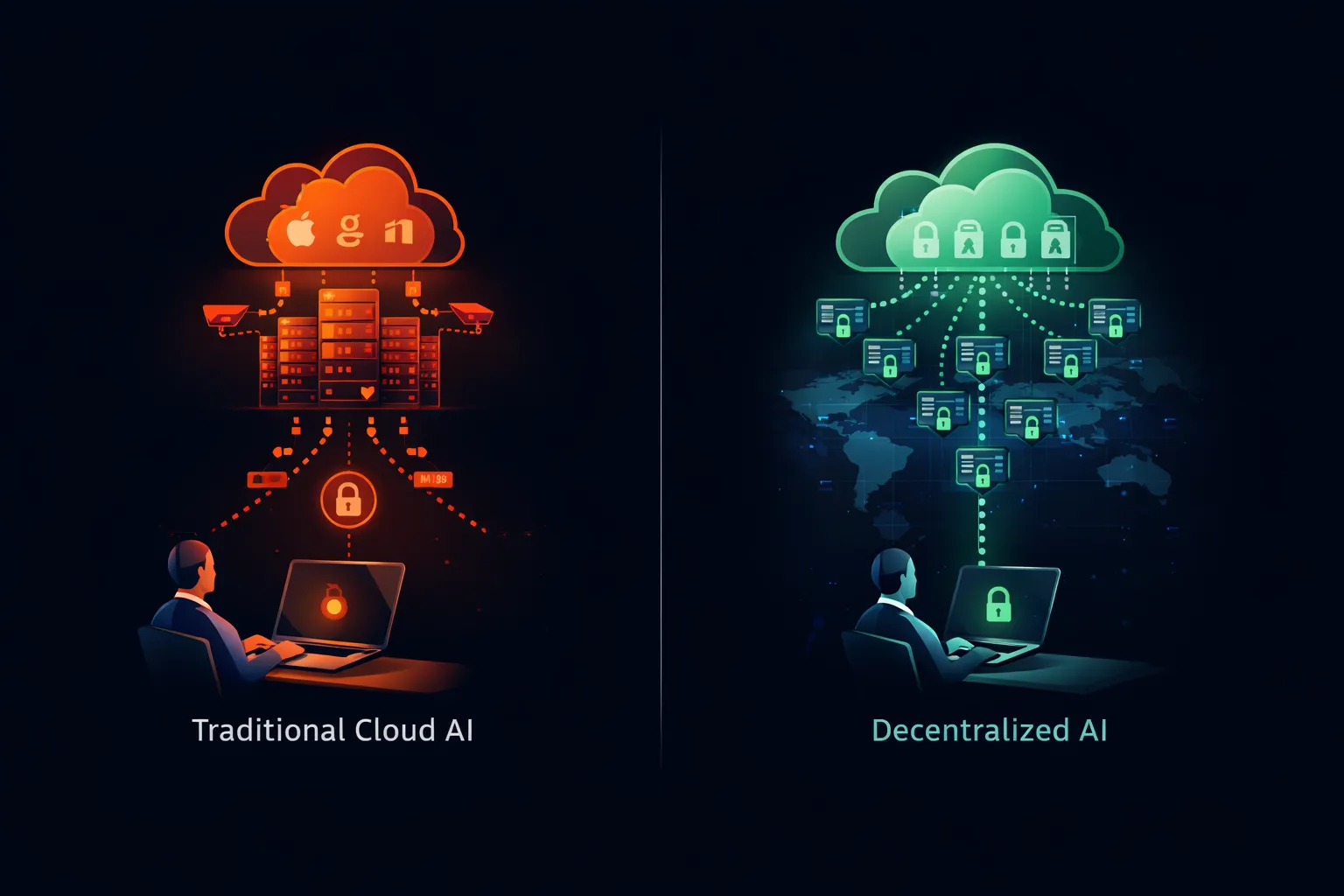
Implementing a Compliant AI Strategy
Organizations moving from ChatGPT bans to private AI deployment should approach the transition systematically.
Phase 1: Policy Development
Begin by articulating what your AI policy actually prohibits and permits. Many initial ChatGPT bans were reactive—blanket prohibitions implemented quickly to stop immediate risk. A mature policy distinguishes between:
- Data categories that may never be processed by external AI systems
- Use cases where cloud AI services are acceptable with appropriate controls
- Approved tools and platforms for different sensitivity levels
- Approval processes for new AI tool adoption
- Incident reporting requirements for policy violations
This framework allows AI usage to continue where appropriate while protecting sensitive operations.
Phase 2: Infrastructure Evaluation
Assess your options for private AI deployment based on organizational resources and requirements:
-
Existing GPU resources: Many organizations have workstations or servers with NVIDIA GPUs used for other purposes (visualization, rendering, scientific computing) that could support AI workloads.
-
Cloud budget and risk tolerance: If your security team accepts cloud provider involvement with appropriate controls, private cloud GPU instances offer simpler operations than on-premises or decentralized options.
-
Privacy requirements: If your use case involves data that cannot touch cloud provider infrastructure under any circumstances, on-premises hardware or decentralized rentals become necessary.
-
Scale and frequency: Occasional fine-tuning jobs suit rental models. Continuous inference serving may justify capital investment.
Phase 3: Model Selection and Customization
Generic open-weights models provide a starting point, but organizational value comes from customization. Fine-tuning on your data creates models that understand your domain, your terminology, and your requirements.
Consider which use cases offer highest value:
- Document analysis: Legal contracts, regulatory filings, internal policies
- Code assistance: Development within your specific frameworks and standards
- Customer communication: Responses reflecting your brand voice and product knowledge
- Internal knowledge: Querying organizational documentation and institutional knowledge
Each use case may warrant a separate fine-tuned model, or a single model trained on diverse organizational data may serve multiple purposes.
Phase 4: Operational Integration
Private AI deployment requires operational capabilities that SaaS products abstract away:
-
Model serving infrastructure: Running inference at scale requires GPU resources, load balancing, and API interfaces. Tools like vLLM, Text Generation Inference, and Ollama simplify deployment.
-
Access controls: Who can query the model? What logging occurs? How do you audit usage?
-
Update procedures: How do you incorporate new training data? How do you deploy improved model versions?
-
Incident response: What happens if a model generates problematic output? Who reviews edge cases?
Organizations accustomed to SaaS simplicity may underestimate this operational overhead. Budget appropriately for ongoing maintenance, not just initial deployment.
Case Study: Financial Services Compliance Architecture
A regional bank with $50 billion in assets faced a familiar dilemma. Relationship managers wanted AI assistance drafting client communications and analyzing portfolio positions. Compliance officers recognized that transmitting client financial data to ChatGPT violated both regulatory requirements and fiduciary duties.
The solution architecture illustrates how organizations can satisfy both constituencies.
Data Classification
The bank established three tiers of AI-permissible data:
-
Tier 1 (Public): Marketing materials, public financial education content, general product descriptions. Cloud AI services permitted with standard acceptable use guidelines.
-
Tier 2 (Internal): Internal policies, training materials, operational procedures. Cloud AI services permitted with enterprise agreements and data handling addenda.
-
Tier 3 (Restricted): Client data, portfolio information, transaction details, strategic planning. No external AI processing under any circumstances.
This classification allowed AI adoption where risk was acceptable while maintaining absolute protection for sensitive categories.
Private Infrastructure Deployment
For Tier 3 use cases, the bank deployed a fine-tuned Llama model on on-premises GPU servers within their existing data center. The model was trained on:
- Anonymized historical client communications (with client consent)
- Internal compliance guidelines and regulatory interpretations
- Product documentation and investment research
- Communication templates approved by compliance
The resulting model understood banking terminology, regulatory constraints, and organizational communication standards. Relationship managers could draft client letters with AI assistance, knowing that no client data left the bank’s security perimeter.
Operational Controls
Every model interaction logged to the bank’s existing compliance archive system. Supervisors could review AI-assisted communications alongside traditional correspondence. Audit trails satisfied regulatory recordkeeping requirements.
The model itself operated within guardrails preventing certain outputs—investment recommendations, guarantee language, or statements that could constitute advice requiring specific licensing. These constraints were implemented at the application layer, not relying on model behavior alone.
Measured Outcomes
Six months after deployment, the bank reported:
- 40% reduction in time spent drafting routine client communications
- Zero compliance incidents related to AI usage
- Successful regulatory examination with no findings related to AI deployment
- Relationship manager satisfaction scores increased
The investment in private infrastructure—approximately $200,000 including hardware, development, and integration—generated returns within the first year through productivity gains alone.
Case Study: Healthcare Research Institution
A major academic medical center conducting clinical research faced HIPAA constraints that made any cloud AI usage with patient data legally problematic. Researchers wanted to use AI for literature review, protocol development, and data analysis.
The Hybrid Approach
Rather than choosing between complete prohibition and unacceptable risk, the institution implemented a hybrid architecture:
-
Public research tasks (literature review, methodology questions, statistical approaches) used cloud AI services with clear policies prohibiting any patient data input.
-
Patient data analysis used locally deployed models on air-gapped workstations within the secure research environment. These machines had no internet connectivity. Data could not leave regardless of user behavior.
Decentralized Training
The institution lacked capital budget for training-capable GPU hardware but needed models fine-tuned on medical literature and research protocols. They utilized decentralized GPU rentals for training runs using only public medical literature and de-identified datasets with no HIPAA implications.
The training workflow followed the security practices outlined in our dataset security guide:
- Transfer only non-sensitive training data to rental nodes
- Execute fine-tuning jobs
- Download resulting model weights
- Sanitize remote environments completely
- Deploy trained models to air-gapped internal infrastructure
This approach provided customized medical AI capabilities without exposing any protected health information to external systems.
Regulatory Validation
The institution’s IRB reviewed the AI deployment as part of research protocol amendments. The clear separation between public data training (external) and patient data inference (internal, air-gapped) satisfied privacy requirements. HIPAA compliance officers approved the architecture after security assessment.

The Strategic Imperative
Organizations that view AI policy solely through a risk mitigation lens miss the larger picture. The enterprises banning ChatGPT today are not abandoning AI. They are repositioning for sustainable advantage.
Competitive Differentiation Through Data
The most valuable AI capabilities emerge from proprietary data. A generic language model trained on internet text provides generic capabilities available to everyone. A model fine-tuned on your customer interactions, your operational data, and your institutional knowledge provides capabilities unique to your organization.
This differentiation requires keeping proprietary data proprietary. Organizations that feed their competitive advantages into cloud AI services contribute to models that benefit all users—including competitors. Organizations that maintain data control while deploying private AI accumulate advantages that compound over time.
Regulatory Trajectory
AI regulation is tightening, not loosening. The EU AI Act establishes precedent that other jurisdictions will follow. US agencies including the FTC, SEC, and banking regulators are developing AI-specific guidance. China has implemented AI regulations affecting model training and deployment.
Organizations building private AI infrastructure now are preparing for regulatory environments that will increasingly constrain cloud AI usage. The investment in compliant architecture becomes more valuable as compliance requirements intensify.
Supply Chain Considerations
Dependence on a single AI provider creates strategic vulnerability. OpenAI’s pricing, policies, and capabilities change at their discretion. Service disruptions affect all customers simultaneously. Policy changes can prohibit previously acceptable use cases overnight.
Private AI deployment eliminates single-vendor dependency. Open-weights models are downloadable and permanently available. Multiple hardware options exist for deployment. The organization controls its AI supply chain rather than depending on external decisions.
Implementation Roadmap
For organizations ready to move beyond ChatGPT bans toward private AI capability, we recommend a phased approach.
Immediate Actions (Week 1-2)
- Audit current AI usage across the organization
- Classify data types by sensitivity and regulatory requirements
- Document which use cases require private infrastructure versus acceptable cloud usage
- Establish interim policy clarifying prohibited and permitted activities
Short-Term Development (Month 1-3)
- Evaluate infrastructure options based on sensitivity requirements and budget
- Select initial use cases for private AI deployment
- Identify training data sources for model customization
- Establish security protocols for external GPU usage if applicable
Medium-Term Deployment (Month 3-6)
- Fine-tune models on organizational data following our technical guide
- Deploy inference infrastructure with appropriate access controls
- Integrate with existing compliance and audit systems
- Train users on approved workflows and tools
Ongoing Operations
- Regular model updates incorporating new training data
- Security assessments of AI infrastructure
- Policy updates reflecting regulatory changes
- Capability expansion to additional use cases
Conclusion
The corporate bans on ChatGPT reflect rational risk management, not technophobia. When Samsung prohibited the tool after discovering proprietary semiconductor designs had been uploaded, they made the correct decision. When JPMorgan restricted access proactively, they demonstrated appropriate regulatory awareness. When healthcare systems block access at the firewall, they protect patient privacy as required by law.
But prohibition is not strategy. Organizations that stop at “no” forfeit productivity advantages their competitors will capture. The enterprises that thrive will be those that recognize a third path exists.
Open-weights models running on private infrastructure provide AI capability without data exposure. The models are available now. The infrastructure is accessible. The technical workflows are documented. The only barrier is organizational will to implement.
Your competitors who are fine-tuning models on their proprietary data—training systems that understand their customers, their products, and their operations—are building advantages you cannot replicate by subscribing to a generic service. While you debate policy, they are deploying capability.
The infrastructure decisions you make today determine whether AI becomes your competitive advantage or your competitors’ advantage over you. Cloud AI services turn your data into shared resources. Private AI deployment turns your data into unique capability.
The choice is not whether to use AI. The choice is whether to control it.
Related Resources
This article addresses the strategic and regulatory context for enterprise AI decisions. The following resources provide technical implementation guidance:
Core Implementation Guide
- The Ultimate Guide to Private LLM Fine-Tuning on Decentralized GPUs — Complete technical workflow for training custom models
Security and Operations
- How to Secure Your Dataset on a Public GPU Node — Operational security practices for decentralized compute
- How to Rent a GPU Without KYC — Anonymous rental workflows for privacy-sensitive deployments
Platform and Economics
- GPU Rental Pricing Comparison 2026 — Cost analysis across deployment options
- Smart Contract Escrow Explained — How decentralized payments protect both parties
- Stablecoins Are the Smartest Way to Pay for GPU Rental — Payment mechanics for decentralized infrastructure
Technical Comparisons
- Ollama vs vLLM vs TGI: Benchmarking Inference Speeds on Consumer GPUs — Inference server selection for deployment
- RunPod vs Vast.ai Comparison — Marketplace evaluation for GPU rentals