
If you are reading this, you likely possess a dataset that you cannot—or will not—upload to OpenAI.
You are not alone. For many enterprises and independent developers, the convenience of ChatGPT is outweighed by the unacceptable risk of data leakage. Whether you are handling medical records subject to HIPAA, proprietary codebases that represent years of engineering investment, or sensitive financial models that could move markets, utilizing cloud AI often means trusting a third party with your most valuable intellectual property.
When that third party is a technology conglomerate with a history of using customer data to train future models, “trust” becomes an uncomfortable word.
The solution is not to abandon AI. The solution is to own the infrastructure.
Fine-tuning open-weights models on hardware you control is no longer a niche academic pursuit. It is a business requirement for privacy-conscious organizations. Models like Llama, Mistral, Qwen, and dozens of others are available for commercial use with no API fees and no data sharing requirements. The challenge has always been access to compute. Purchasing NVIDIA H100 clusters requires millions in capital expenditure. Renting from AWS demands identity verification, enterprise agreements, and hourly rates that make extended training runs prohibitively expensive.
This guide presents a third path. You will learn how to fine-tune an open-weights language model using decentralized GPU rentals—hardware owned by individuals around the world, accessible through a peer-to-peer marketplace. We will cover environment setup, security protocols for operating on public nodes, and the complete training execution.
The code examples use Llama-3.1-8B as a concrete working reference, but the workflow applies identically to any Hugging Face-compatible model. Swap the model identifier and you can fine-tune Mistral-7B, Qwen2-7B, or whatever open-weights release fits your use case.
You will accomplish this without KYC verification, without long-term contracts, and for a fraction of what traditional cloud providers charge.
The Economics of Private Fine-Tuning
Before we examine the technical implementation, let us establish the financial context.
Training a model on AWS requires navigating instance scarcity. The p4d.24xlarge instance (8x A100 GPUs) costs $32.77 per hour when you can get one, which is rarely. Lambda Labs offers better pricing but maintains waitlists that stretch for weeks. Both require credit cards, identity verification, and generate detailed billing records that link your AI activities to your legal identity.
In a decentralized marketplace, you rent compute power directly from hardware owners. This is peer-to-peer infrastructure operating on blockchain-based payment rails. The implications are significant:
Cost reduction: An RTX 4090 rents for $0.40 to $0.60 per hour on most decentralized platforms. For 8B parameter models using QLoRA, a single 4090 with 24GB VRAM completes a fine-tuning run in two to six hours depending on dataset size. Your total compute cost ranges from three to eight dollars.
Privacy by architecture: Payments occur through stablecoin transactions on networks like Polygon. There is no credit card linking your identity to the rental. The marketplace smart contract handles escrow, as detailed in our escrow documentation, ensuring neither party can defraud the other.
No gatekeepers: You do not need approval from a cloud provider’s enterprise sales team. You do not sign acceptable use policies that grant the provider rights to inspect your workloads. You connect a wallet and rent hardware.
For comparison: the equivalent fine-tuning workflow on AWS using a single A10G instance (the cheapest option with sufficient VRAM) costs approximately $1.50 per hour. Factor in setup time, idle compute while configuring your environment, and the inability to pay anonymously, and the true cost approaches $150 to $300 for what you can accomplish for under ten dollars on decentralized infrastructure.
These economics are documented in detail in our GPU rental pricing comparison.
Prerequisites
This tutorial assumes familiarity with the Linux command line. You do not need a graduate degree in machine learning, but you should be comfortable navigating a filesystem, editing text files, and interpreting error messages.
Hardware Requirements:
- GPU: Minimum 24GB VRAM. The RTX 3090, RTX 4090, and A10G all qualify. For the 70B parameter model, you need 48GB or more (A6000, dual A100s, or H100).
- System RAM: 32GB or higher. The model loading process stages weights in system memory before transferring to GPU.
- Storage: 100GB or more of NVMe SSD space. The base Llama-3 8B weights consume approximately 16GB. Your dataset, checkpoints, and the output adapter add additional overhead.
A note on model selection: This tutorial uses Meta’s Llama-3.1-8B as the working example because it represents the largest class of model that fits on a single 24GB GPU with QLoRA quantization. The Llama family now includes Llama 4 Scout and Maverick, but these use a Mixture of Experts architecture with 109B and 400B total parameters respectively, requiring multi-GPU configurations that exceed the scope of a single-node rental. The workflow described here applies equally to Mistral-7B, Qwen2-7B, Gemma-2-9B, and any other Hugging Face-compatible model that fits within your rented hardware’s VRAM constraints. Software Prerequisites:
- Python 3.10 or later
- Basic proficiency with PyTorch
- A Hugging Face account (required for downloading gated models like Llama which require license acceptance)
- A cryptocurrency wallet (MetaMask or equivalent) funded with USDC or MATIC on the Polygon network
If you have not configured a wallet for decentralized GPU rental, complete our MetaMask and Polygon setup guide before proceeding. The process takes approximately fifteen minutes.
Step 1: Securing Your Compute Node
The first step is acquiring hardware. On centralized cloud platforms, this involves creating an account, uploading identity documents, waiting for approval, and adding a payment method. Here, the process is considerably more direct.
Navigate to the GPUFlow marketplace. Connect your wallet using the button in the upper right corner. The interface displays available machines with their specifications, hourly rates, and reliability scores.
Filter for machines with the following characteristics:
- GPU: RTX 4090 (24GB VRAM) or RTX 6000 Ada (48GB VRAM)
- RAM: 32GB minimum
- Storage: 100GB+ available
- Reliability: 95% or higher uptime score
Select a node and initiate the rental. The smart contract will request a deposit covering your estimated usage. You can review how this escrow mechanism protects both parties in our smart contract escrow explanation.
Security considerations for public nodes:
When you rent a machine on any remote network, you are accessing hardware owned and physically controlled by a stranger. The virtualization layer provides meaningful isolation, but you must operate with appropriate caution:
-
Do not store private keys on the remote machine. Your cryptocurrency wallet, SSH keys for other systems, and API tokens for production services should never exist on a rental node.
-
Treat the filesystem as hostile. Assume that anything you write to disk could theoretically be recovered by the host after you disconnect. We will cover secure deletion procedures in Step 6.
-
Encrypt sensitive data during transfer. We address this in Step 3.
-
Do not reuse passwords. If the rental interface provides default credentials, change them immediately or generate a new SSH key pair.
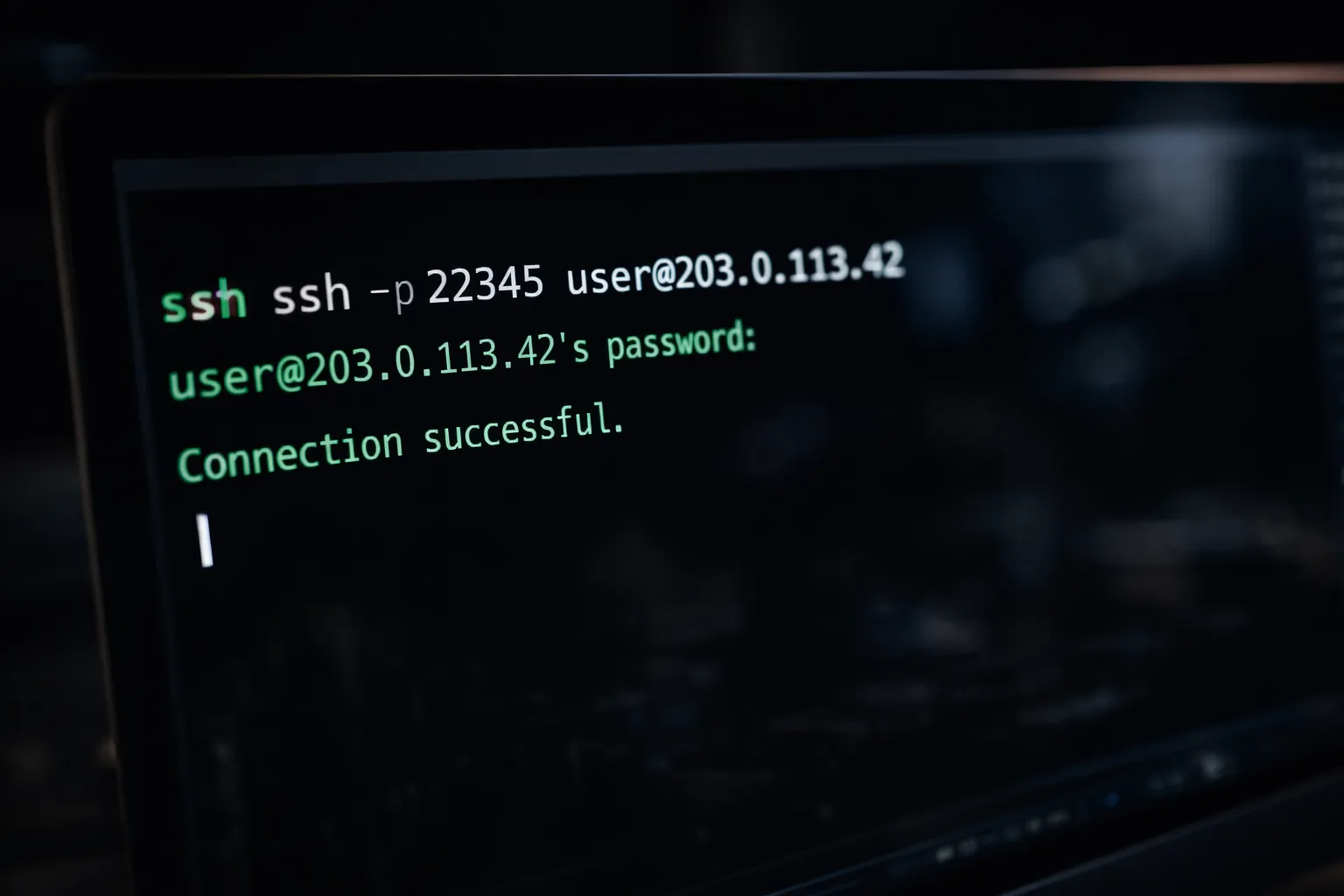
Once your rental is confirmed, the dashboard provides connection details. You will receive an SSH command resembling the following:
ssh -p 22345 [email protected]Open your local terminal and execute this command. Accept the host key fingerprint when prompted. You are now connected to your rented GPU node.
Verify that the hardware matches your order:
nvidia-smiThe output should display your rented GPU, its memory capacity, and the installed driver version. If the GPU does not appear or the specifications differ from your order, disconnect immediately and report the discrepancy through the marketplace dispute system.
Step 2: Environment Configuration
With a verified SSH connection established, the next priority is constructing a clean Python environment. Most rental nodes ship with pre-installed NVIDIA drivers and CUDA toolkits, but relying on the host’s system-level Python packages invites dependency conflicts that will consume hours of debugging.
We will create an isolated virtual environment to ensure reproducibility and stability.
Execute the following commands to create your workspace:
mkdir ~/llama3-finetune
cd ~/llama3-finetune
python3 -m venv venv
source venv/bin/activateYour terminal prompt should now display (venv) indicating that the virtual environment is active. All subsequent package installations will be contained within this directory, leaving the host system untouched.
Before installing Python packages, verify that the CUDA toolkit is accessible:
nvcc --versionNote the CUDA version number. You will need this to ensure compatibility with PyTorch. Most rental nodes run CUDA 11.8 or 12.1. If nvcc is not found, the CUDA toolkit may not be in your PATH. This is usually resolved by sourcing the appropriate environment file:
source /etc/profile.d/cuda.shIf this file does not exist, consult the marketplace documentation for your specific node configuration.
Now install the PyTorch ecosystem. The following command installs PyTorch with CUDA 12.1 support. Adjust the CUDA version suffix if your node runs a different version:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Next, install the libraries required for efficient fine-tuning. We are using the Hugging Face ecosystem along with bitsandbytes for quantization and PEFT for parameter-efficient training:
pip install transformers==4.40.0 datasets==2.19.0 peft==0.10.0 bitsandbytes==0.43.1 trl==0.8.6 accelerate==0.29.0Version pinning matters. The above versions are tested and compatible as of this writing. The Hugging Face ecosystem evolves rapidly, and unpinned installations frequently introduce breaking changes. If you encounter import errors or unexpected behavior, version mismatches are the most likely cause.
Finally, authenticate with Hugging Face. The Llama-3 weights are gated behind a license agreement that requires a Hugging Face account. Navigate to the Meta Llama-3 repository and accept the license terms. Then generate an access token from your Hugging Face settings page.
Run the authentication command:
huggingface-cli loginPaste your access token when prompted. The token is stored in ~/.cache/huggingface/token. You now have authorization to download gated model weights directly to the rental node.

Step 3: Secure Data Transfer
This section addresses the primary reason you are renting decentralized compute rather than calling an API: data sovereignty.
The standard cloud workflow involves uploading your dataset to a storage bucket—S3, Google Cloud Storage, Azure Blob—and then downloading it to your compute instance. This approach creates multiple copies of your sensitive data across systems you do not control. The storage provider has access. The compute provider has access. Both maintain logs of your activity.
We will bypass this entirely using direct encrypted transfer.
The SSH protocol includes scp (Secure Copy Protocol), which transfers files over the same encrypted channel you use for terminal access. Your data moves directly from your local machine to the rental node without touching any intermediate storage.
Open a new terminal window on your local computer. Do not close your existing SSH session to the rental node. Execute the following command, substituting your actual file path and connection details:
scp -P 22345 /path/to/your/dataset.jsonl [email protected]:~/llama3-finetune/The -P flag specifies the port number (note the capital P, which differs from ssh’s lowercase -p). For large datasets, the transfer may take several minutes. You will see progress output indicating bytes transferred.
For datasets exceeding 1GB, consider compressing before transfer:
# On your local machine
gzip -k dataset.jsonl
scp -P 22345 dataset.jsonl.gz [email protected]:~/llama3-finetune/
# Then on the remote node
cd ~/llama3-finetune
gunzip dataset.jsonl.gzAdditional security measures:
If your threat model includes sophisticated adversaries, you may wish to encrypt the dataset before transfer using GPG or age. This provides defense-in-depth: even if the transfer were somehow intercepted, the contents would remain unreadable.
# On your local machine (using age encryption)
age -p dataset.jsonl > dataset.jsonl.age
scp -P 22345 dataset.jsonl.age [email protected]:~/llama3-finetune/
# On the remote node
age -d dataset.jsonl.age > dataset.jsonl
rm dataset.jsonl.ageFor most users, the standard SCP transfer provides sufficient protection. The SSH protocol uses AES-256 encryption. Man-in-the-middle attacks are prevented by host key verification. Your data does not traverse any third-party storage systems.
Step 4: The Fine-Tuning Script
We will use the TRL (Transformer Reinforcement Learning) library’s SFTTrainer class to execute supervised fine-tuning. This library abstracts significant complexity while remaining configurable for production workloads.
Before writing the training script, you must understand the expected dataset format.
Dataset Format Requirements:
The script expects a JSONL file (JSON Lines) where each line contains a valid JSON object with a text field. The text field should contain your complete training example formatted as a single string.
Here is an example of three properly formatted lines:
{"text": "### Instruction: Summarize the following legal clause in plain English.\n\n### Input: Party A shall indemnify, defend, and hold harmless Party B from any claims, damages, or expenses arising from Party A's negligence or willful misconduct.\n\n### Response: Party A agrees to protect Party B from any legal claims or costs that result from Party A's mistakes or intentional wrongdoing."}
{"text": "### Instruction: Extract the key financial metrics from this earnings report.\n\n### Input: Q3 revenue reached $4.2B, up 12% YoY. Operating margin improved to 23.5% from 21.2%. Free cash flow was $890M.\n\n### Response: Revenue: $4.2 billion (12% year-over-year growth). Operating margin: 23.5% (up from 21.2%). Free cash flow: $890 million."}
{"text": "### Instruction: Identify potential HIPAA violations in this process description.\n\n### Input: Patient records are emailed to the billing department as PDF attachments. The billing staff prints these for manual review and shreds them after processing.\n\n### Response: Potential violations include: unencrypted email transmission of PHI, physical documents that may be visible to unauthorized personnel during processing, and lack of documented chain of custody. Recommend encrypted file transfer and on-screen review only."}Critical formatting notes:
- Each JSON object must occupy exactly one line. No multi-line JSON.
- Newlines within the
textfield must be escaped as\n. - Quotation marks within the text must be escaped as
\". - The file must use UTF-8 encoding.
If your source data exists in a different format (CSV, Parquet, separate instruction/response columns), you will need to preprocess it into this structure before transfer. Python’s json library handles the escaping automatically:
import json
with open('dataset.jsonl', 'w') as f:
for example in your_data:
text = f"### Instruction: {example['instruction']}\n\n### Input: {example['input']}\n\n### Response: {example['output']}"
f.write(json.dumps({"text": text}) + '\n')With your dataset in place, create the training script on the remote node:
cd ~/llama3-finetune
nano train.pyPaste the following configuration. This script uses QLoRA to fine-tune an 8B parameter model within the memory constraints of a 24GB GPU. The example uses Llama-3.1-8B but you can substitute any compatible model by changing the MODEL_NAME variable:
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from peft import LoraConfig
from trl import SFTTrainer
# ============================================
# CONFIGURATION - Modify these values as needed
# ============================================
# Base model identifier on Hugging Face
# Change this to fine-tune a different model (e.g., "mistralai/Mistral-7B-v0.1")
MODEL_NAME = "meta-llama/Llama-3.1-8B"
# Name for your fine-tuned adapter
OUTPUT_NAME = "llama-3-8b-custom"
# Path to your dataset
DATASET_PATH = "dataset.jsonl"
# Training hyperparameters
NUM_EPOCHS = 1
BATCH_SIZE = 4
LEARNING_RATE = 2e-4
MAX_SEQ_LENGTH = 512
# LoRA hyperparameters
LORA_RANK = 16
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
# ============================================
# QUANTIZATION CONFIGURATION
# ============================================
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)
# ============================================
# MODEL LOADING
# ============================================
print("Loading base model...")
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# ============================================
# DATASET LOADING
# ============================================
print(f"Loading dataset from {DATASET_PATH}...")
dataset = load_dataset("json", data_files=DATASET_PATH, split="train")
print(f"Dataset contains {len(dataset)} examples")
# ============================================
# LORA CONFIGURATION
# ============================================
peft_config = LoraConfig(
r=LORA_RANK,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
)
# ============================================
# TRAINING ARGUMENTS
# ============================================
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=BATCH_SIZE,
gradient_accumulation_steps=1,
learning_rate=LEARNING_RATE,
weight_decay=0.001,
fp16=True,
logging_steps=10,
save_steps=100,
save_total_limit=3,
optim="paged_adamw_32bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
)
# ============================================
# TRAINER INITIALIZATION AND EXECUTION
# ============================================
print("Initializing trainer...")
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=MAX_SEQ_LENGTH,
tokenizer=tokenizer,
args=training_args,
)
print("Starting training...")
trainer.train()
print(f"Saving adapter to {OUTPUT_NAME}...")
trainer.model.save_pretrained(OUTPUT_NAME)
tokenizer.save_pretrained(OUTPUT_NAME)
print("Training complete.")Save the file with Ctrl+O, then exit with Ctrl+X.
Understanding the key parameters:
-
LORA_RANK (r=16): Controls the expressiveness of the fine-tuned adapter. Higher values learn more but require more memory. Values between 8 and 64 are typical.
-
LORA_ALPHA (16): Scaling factor for the LoRA weights. A common heuristic sets this equal to the rank.
-
MAX_SEQ_LENGTH (512): Maximum token length for training examples. Longer sequences require more memory. If you encounter OOM errors, reduce this value first.
-
BATCH_SIZE (4): Number of examples processed simultaneously. Reduce to 2 or 1 if memory is insufficient.
-
target_modules: The specific layers where LoRA adapters are injected. For Llama-3, the attention projection layers (q, k, v, o) provide the best results.
To begin training, execute:
python train.pyThe script will first download the base model weights (approximately 16GB for an 8B model). This occurs only once; subsequent runs use the cached weights. After loading completes, you will see training progress with loss values printed every 10 steps.
Step 5: Monitoring the Training Run
While the training script executes, you must monitor the health of the GPU. If VRAM saturates or temperatures exceed safe thresholds, the process will crash—potentially corrupting your checkpoint and wasting your rental time.
Open a second terminal window on your local machine and establish another SSH connection to the rental node:
ssh -p 22345 [email protected]Execute the following command to display real-time GPU statistics:
watch -n 1 nvidia-smi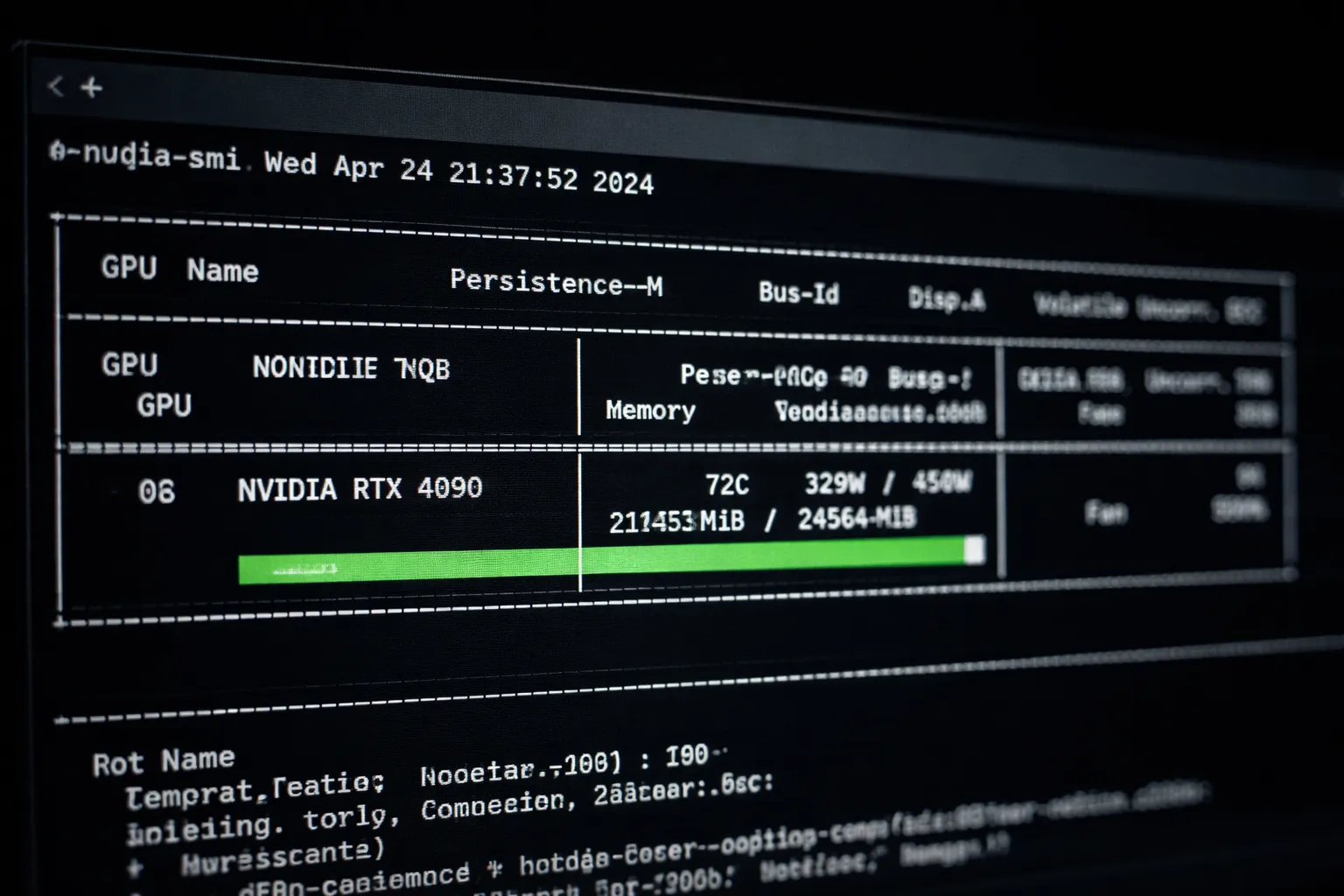
This utility refreshes every second, showing memory usage, GPU utilization percentage, and temperature. On an RTX 4090 running the configuration specified in this guide, you should observe:
- Memory usage: 18GB to 22GB of the available 24GB
- GPU utilization: 90% to 100% during active training steps
- Temperature: 60°C to 80°C depending on the host’s cooling solution
Troubleshooting common issues:
Memory approaching 24GB: If you see memory usage consistently hitting the ceiling, reduce the BATCH_SIZE parameter in your training script to 2 or 1. Alternatively, reduce MAX_SEQ_LENGTH to 256. Either change requires restarting the training run.
GPU utilization near 0%: This typically indicates a data loading bottleneck. The CPU cannot feed examples to the GPU quickly enough. This is less common on NVMe-equipped nodes but may occur with very large datasets. Consider preprocessing your dataset into a more efficient format (Arrow/Parquet) before transfer.
Temperature exceeding 85°C: Some hosts run GPUs in poorly ventilated enclosures. Sustained high temperatures may trigger thermal throttling, slowing your training. If temperatures consistently exceed 85°C, consider terminating the rental and selecting a different node. Hardware damage is the host’s problem, but lost time and corrupted checkpoints are yours.
Interpreting the loss curve:
Your training script outputs a loss value every 10 steps. This number represents how “wrong” the model’s predictions are—lower is better. You should observe:
- Initial loss: Typically between 1.5 and 3.0 depending on your dataset
- Trend: Steadily decreasing over the first several hundred steps
- Final loss: Typically between 0.5 and 1.5 for a well-configured run
If the loss stagnates immediately (no decrease after 100 steps), your learning rate may be too low. If the loss oscillates wildly or increases, your learning rate is too high. The default value of 2e-4 works well for most datasets, but adjustment may be necessary.
If the loss decreases smoothly and then suddenly spikes to very high values (10+), your dataset likely contains malformed examples. Stop the training, examine your JSONL file for encoding errors or improperly escaped characters, and restart.
A typical fine-tuning run on 1,000 examples completes in 30 to 60 minutes on an RTX 4090. Larger datasets scale approximately linearly—10,000 examples require 5 to 10 hours.
Step 6: Retrieving Your Model and Sanitizing the Environment
When training completes, your fine-tuned weights exist as a LoRA adapter in the directory specified by OUTPUT_NAME. This adapter is compact—typically 100MB to 500MB—compared to the full 16GB base model.
First, verify the adapter files exist:
ls -la ~/llama3-finetune/llama-3-8b-custom/You should see files including adapter_config.json, adapter_model.safetensors, and tokenizer files.
Do not merge the adapter on the rental node. Merging combines the LoRA weights with the base model to create a standalone fine-tuned model. This operation requires loading the full 16-bit base model into memory, which may exceed available VRAM on a 24GB card. Perform the merge on your local infrastructure, or simply load the adapter alongside the base model during inference. The PEFT library handles this seamlessly:
from peft import PeftModel
from transformers import AutoModelForCausalLM
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B",To download your adapter, return to your local terminal (not the SSH session) and execute:
scp -r -P 22345 [email protected]:~/llama3-finetune/llama-3-8b-custom ./The -r flag enables recursive copying of the entire directory. Verify the transfer completed successfully by checking the local file sizes match the remote.
Sanitizing the remote environment:
This step separates professionals from hobbyists. Your rental node now contains your proprietary dataset, your training code, and cached model weights. Leaving this material on a machine you do not control violates basic operational security.
Return to your SSH session on the rental node and execute the following commands:
# Remove your working directory and all contents
rm -rf ~/llama3-finetune
# Clear the Hugging Face cache (contains downloaded model weights)
rm -rf ~/.cache/huggingface
# Clear Python package cache
rm -rf ~/.cache/pip
# Clear bash history
history -c
cat /dev/null > ~/.bash_history
# Clear any potential swap residue (may require sudo depending on node config)
syncIf the node provides shred and you want additional assurance that deleted files cannot be recovered:
# Secure deletion (slower but more thorough)
find ~/llama3-finetune -type f -exec shred -u {} \;
rm -rf ~/llama3-finetuneDisconnect from the SSH session:
exitNavigate to the GPUFlow marketplace dashboard and formally end your rental. The smart contract will release any remaining deposit back to your wallet, minus the compute time consumed.
Running Inference with Your Fine-Tuned Model
With the adapter downloaded to your local machine, you can run inference without any cloud dependency. Here is a minimal example:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel
# Quantization config (same as training)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
quantization_config=bnb_config,
device_map="auto",
)
# Load your fine-tuned adapter
model = PeftModel.from_pretrained(base_model, "./llama-3-8b-custom")
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
# Generate a response
prompt = "### Instruction: Summarize the contract clause.\n\n### Input: The Licensee shall not reverse engineer, decompile, or disassemble the Software.\n\n### Response:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)For production deployment, consider wrapping this in an API using FastAPI or Flask, or deploying through inference servers like vLLM or Text Generation Inference (TGI). These options are explored in our upcoming guide on deploying fine-tuned models.
Conclusion
You have fine-tuned a state-of-the-art Large Language Model on proprietary data without exposing that data to any third party. You accomplished this without signing enterprise contracts, without uploading identity documents, and without granting a technology corporation access to your intellectual property.
The total cost of this operation, assuming a two-hour training run on an RTX 4090 at $0.45 per hour, was ninety cents. The equivalent workflow on AWS, accounting for setup time, instance costs, and the overhead of identity verification, would cost one hundred to two hundred dollars.
More importantly, no record exists linking your identity to this training run. No corporate acceptable use policy governs what you can train. No terms of service grants a cloud provider rights to inspect your dataset.
The era of dependency on closed-source APIs is ending. Organizations that require privacy, researchers who value sovereignty, and developers who refuse surveillance have an alternative. Decentralized GPU compute restores control over infrastructure, costs, and data to the people who create value.
Your fine-tuned model now exists on hardware you control. The decisions about how to deploy it, who can access it, and what purposes it serves belong to you alone.
What to Read Next
This guide covered the core workflow for private LLM fine-tuning. The following resources address related topics in greater depth:
Understanding Costs and Payment:
- GPU Rental Pricing Comparison 2026 — Detailed cost analysis across decentralized and centralized providers
- Stablecoins Are the Smartest Way to Pay for GPU Rental — Why cryptocurrency payments provide advantages beyond anonymity
- How to Rent a GPU Without KYC — Complete walkthrough of anonymous rental workflows
Platform Mechanics:
- Setting Up MetaMask for Polygon GPU Rental — Wallet configuration for first-time users
- Smart Contract Escrow Explained — How trustless payments protect both renters and providers
- Hidden Fees in GPU Rental — Cost factors that pricing pages do not advertise
Comparing Options:
- RunPod vs Vast.ai Comparison — How centralized marketplaces differ from decentralized alternatives